

AI Data Engine Architektur
 Änderungen vorschlagen
Änderungen vorschlagen
AI Data Engine (AIDE) basiert auf einer skalierbaren, fehlertoleranten Architektur, die Speicher und Rechenleistung trennt und so hohe Leistung und Flexibilität für KI-Workloads ermöglicht.
Physikalische Komponenten
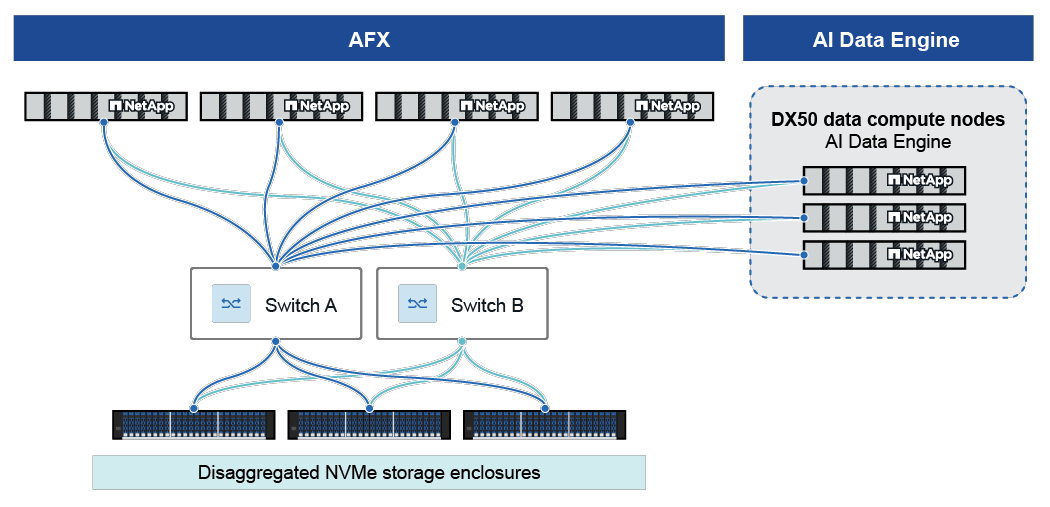
AFX-Controller-Knoten
AFX-Controller-Knoten führen eine spezialisierte Variante der ONTAP Software aus, die entwickelt wurde, um die Anforderungen der AFX-Umgebung zu unterstützen. Clients greifen über mehrere Protokolle, einschließlich NFS und SMB, auf die Knoten zu. Jeder Knoten hat eine vollständige Sicht auf den Speicher, auf den er basierend auf den Client-Anfragen zugreifen kann. Die Knoten sind zustandsbehaftet mit nichtflüchtigem Speicher, um kritische Zustandsinformationen zu speichern, und beinhalten zusätzliche Verbesserungen, die speziell auf die Ziel-Workloads zugeschnitten sind.
Für AIDE-Bereitstellungen sind mindestens vier AFX-Controller-Knoten erforderlich, um hohe Verfügbarkeit und Leistung sicherzustellen.
Datenrechenknoten
Datenrechenknoten sind Linux-basierte Server mit hoher CPU-, RAM- und GPU-Leistung, die speziell für KI-Datenverarbeitungsaufgaben entwickelt wurden. Sie hosten KI-spezifische Dienste wie Metadaten-Katalogisierung, Vektorsuche und Einbettungspipelines.
Für AIDE Deployments werden genau drei Datenrechenknoten benötigt.
Cluster-/Storage-Switches
Redundante Hochgeschwindigkeits-Switches (100GbE oder höher) verbinden ONTAP und Datenrechenknoten für mit niedriger Latenz Datentransfer und hohe Verfügbarkeit.
Storage-Shelfs
NVMe-oF-Einschübe mit SSDs hoher Dichte bieten ultra-niedrige Latenz und Redundanz und unterstützen PB-skalierbaren Speicher.
Netzwerk
Alle Datenrechenknoten und ONTAP-Speicherknoten sind über redundante Hochgeschwindigkeits-Cluster-Switches (mindestens 100GbE) verbunden. Diese Architektur trennt Rechen- und Speicherressourcen, sodass jede unabhängig skaliert werden kann und sowohl die Leistung als auch die Ressourcenauslastung optimiert werden.
Die Netzwerkverbindung zwischen den Datenrechenknoten und ONTAP-Knoten ist durch dedizierte VLANs und IPspaces auf den Cluster-Switches isoliert. Dadurch wird sichergestellt, dass die gesamte Kommunikation, wie Datenzugriff, Management-APIs und interner Dienstverkehr, sicher und effizient bleibt und andere Netzwerkoperationen nicht beeinträchtigt.
AI Data Engine Hauptmerkmale
Die Hauptfunktionen der AI Data Engine (AIDE) arbeiten zusammen, um den Lebenszyklus von KI-Daten zu automatisieren, zu sichern und zu beschleunigen. Jede Funktion ist als Satz von Microservices implementiert, die auf Datenrechenknoten ausgeführt werden, in ONTAP storage integriert sind und über REST-APIs und Verwaltungsschnittstellen bereitgestellt werden.
Metadata Engine
Die Metadata Engine generiert automatisch eine strukturierte, aktuelle und interaktive Ansicht Ihres NetApp Datenbestands.
Die Metadata Engine ist in der ONTAP One-Basislizenz enthalten und ist nach der Installation von AIDE verfügbar.
Sie können über ONTAP System Manager darauf zugreifen.
-
Katalogisiert Metadaten für alle Datenquellen, einschließlich Volumes, die lokal auf dem AFX-Cluster gespeichert sind, und solche, die von entfernten ONTAP Clustern synchronisiert werden.
-
Extrahiert automatisch Metadaten und füllt den Katalog, während Daten aufgenommen oder geändert werden.
-
Bietet REST-API-Zugriff zum Abfragen von Metadaten und ermöglicht Datenexperten und Speicheradministratoren, Daten zu entdecken, zu klassifizieren und zu verstehen.
-
Lagert Metadatenabfragen vom Datenpfad aus und reduziert so die NFS-Verkehrslast auf Speichersystemen.
-
Unterstützt große Metadatensätze mit Indizierung und Suchfunktionen.
-
Integriert sich in Workspace- und Datenerfassungsabstraktionen, um Zugriffskontrolle und Governance durchzusetzen.
Datensynchronisierung
Data Sync ist ein automatisierter Hintergrunddienst, der sicherstellt, dass der Metadatenkatalog und die Datensammlungen aktuell und konsistent mit den zugrunde liegenden Datenquellen bleiben, selbst wenn sich die Quelldaten ändern.
Die Datensynchronisierungsfunktion ist in der ONTAP One-Basislizenz enthalten und steht nach der Installation von AIDE zur Verfügung.
-
Synchronisiert Daten von entfernten oder lokalen ONTAP Clustern mithilfe richtliniengesteuerter SnapMirror-Replikation. Daten von entfernten Clustern werden für die AIDE-Verarbeitung in den lokalen AFX-Cluster kopiert.
-
Aktualisiert inkrementell basierend auf erkannten Änderungen und propagiert nur die modifizierten Daten.
-
Gewährleistet sichere, inkrementelle Datenmobilität und Synchronisierung über den gesamten Datenbestand hinweg.
-
Plant und überwacht Synchronisierungsintervalle mit konfigurierbaren Aktualisierungsraten pro Arbeitsbereich.
-
Integriert sich in Workflows zur Erstellung von Arbeitsbereichen, um Metadaten zu extrahieren und zu aktualisieren, wenn neue Datenquellen hinzugefügt werden.
Data Guardrails
Der Data Guardrails Dienst bietet kontinuierliche, automatisierte Steuerung und Schutz für sensible Daten während des gesamten KI-Lebenszyklus.
Data Guardrails Funktionalität ist nicht in der ONTAP One-Basislizenz enthalten und erfordert eine separate AIDE premium services Lizenz.
Sie können auf die Data Guardrails-Funktionalität über die AIDE Console zugreifen.
-
Scannt, klassifiziert und kategorisiert kontinuierlich Daten.
-
Identifiziert sensible Daten und Risiken mithilfe integrierter und anpassbarer Klassifikatoren für Aufgaben wie PII-Erkennung.
-
Automatisiert den Umgang mit sensiblen Daten durch richtlinienbasierte Schwärzung, Maskierung und Zugriffsbeschränkungen.
-
Setzt Unternehmens- und Regulierungsstandards durch an Arbeitsbereiche angehängte Guardrail-Richtlinien durch.
-
Beschränkt den Zugriff auf sensible Dateien oder Datenträger gemäß der Konfiguration, mit Audit-Protokollierung und Compliance-Berichterstattung.
-
Integriert sich in die Arbeitsbereichs- und Datenerfassungsverwaltung, um Data Guardrails konsistent über AI Data Workflows hinweg anzuwenden.
Data Curator
Der Data Curator Service ermöglicht schnelle Datenentdeckung, Suche, Vektorisierung und Abruf für AI- und GenAI-Anwendungen.
Data Curator Funktionalität ist nicht in der ONTAP One-Basislizenz enthalten und erfordert eine separate AIDE Premium-Services-Lizenz.
Sie können Data Curator über die AIDE Console aufrufen.
-
Durchsucht den Speicher nach relevanten Daten mithilfe des zentralen Metadatenkatalogs.
-
Bietet Tools für Datenwissenschaftler, um kuratierte Datensammlungen zu erstellen.
-
Erzeugt automatisch Vektoreinbettungen auf der Speicherschicht.
-
Bietet einen sicheren Abruf-Endpunkt für KI-Anwendungen, unterstützt vektorsemantische Suche und Neubewertung.
-
Lässt sich in KI-Tools und -Technologien integrieren, einschließlich Retrieval-Augmented Generation (RAG)-Pipelines und agentic AI-Frameworks.
-
Bietet REST-APIs für den programmatischen Zugriff auf Datensammlungen, Vektorsuche und Abrufendpunkte.
Sicherheit und Mandantenfähigkeit
Die Plattform setzt sowohl rollenbasierte Zugriffssteuerung (RBAC) als auch ressourcenbasierte Zugriffskontrolllisten (ACLs) durch. Alle API- und Benutzeraktionen werden protokolliert, und alle Daten werden im Ruhezustand und während der Übertragung verschlüsselt. Einzelne Mandanten sind für Daten und Metadaten isoliert.