

Verwalten Sie den für das Daten-Tiering verwendeten Objektspeicher in NetApp Cloud Tiering
 Änderungen vorschlagen
Änderungen vorschlagen
Nachdem Sie Ihre lokalen ONTAP Cluster so konfiguriert haben, dass Daten in einen bestimmten Objektspeicher verschoben werden, können Sie mithilfe von NetApp Cloud Tiering zusätzliche Objektspeicheraufgaben ausführen. Sie können neuen Objektspeicher hinzufügen, Ihre mehrstufigen Daten auf einen sekundären Objektspeicher spiegeln, den primären und den gespiegelten Objektspeicher austauschen, einen gespiegelten Objektspeicher aus einem Aggregat entfernen und vieles mehr.
Anzeigen von für einen Cluster konfigurierten Objektspeichern
Sie können alle Objektspeicher anzeigen, die für jeden Cluster konfiguriert wurden, und an welche Aggregate sie angeschlossen sind.
-
Wählen Sie auf der Seite Cluster das Menüsymbol für einen Cluster und dann Object Store Info aus.
-
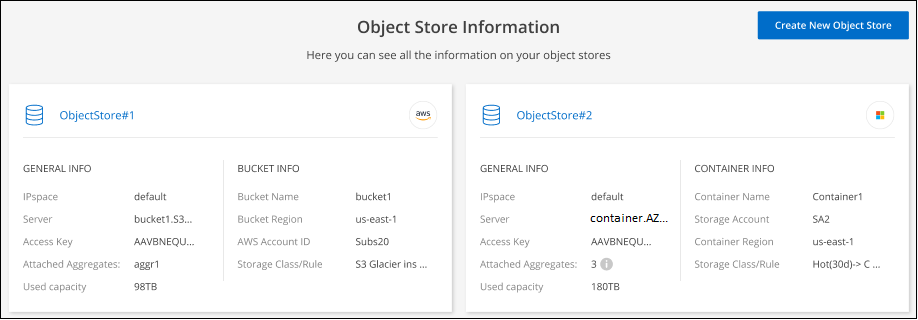
Überprüfen Sie die Details zu den Objektspeichern.
Dieses Beispiel zeigt sowohl einen Amazon S3- als auch einen Azure Blob-Objektspeicher, die an verschiedene Aggregate in einem Cluster angeschlossen sind.
Einen neuen Objektspeicher hinzufügen
Sie können einen neuen Objektspeicher für Aggregate in Ihrem Cluster hinzufügen. Nachdem Sie es erstellt haben, können Sie es an ein Aggregat anhängen.
-
Wählen Sie auf der Seite Cluster das Menüsymbol für einen Cluster und dann Object Store Info aus.
-
Wählen Sie auf der Seite „Objektspeicherinformationen“ die Option „Neuen Objektspeicher erstellen“ aus.
Der Objektspeicher-Assistent wird gestartet. Das folgende Beispiel zeigt, wie ein Objektspeicher in Amazon S3 erstellt wird.
-
Name des Objektspeichers definieren: Geben Sie einen Namen für diesen Objektspeicher ein. Es muss sich von allen anderen Objektspeichern unterscheiden, die Sie möglicherweise mit Aggregaten auf diesem Cluster verwenden.
-
Anbieter auswählen: Wählen Sie den Anbieter aus, zum Beispiel Amazon Web Services, und wählen Sie Weiter.
-
Führen Sie die Schritte auf den Seiten Objektspeicher erstellen aus:
-
S3-Bucket: Fügen Sie einen neuen S3-Bucket hinzu oder wählen Sie einen vorhandenen S3-Bucket aus, der mit dem Präfix fabric-pool beginnt. Geben Sie dann die AWS-Konto-ID ein, die Zugriff auf den Bucket gewährt, wählen Sie die Bucket-Region aus und wählen Sie Weiter.
Das Präfix fabric-pool ist erforderlich, da die IAM-Richtlinie für den Konsolenagenten es der Instanz ermöglicht, S3-Aktionen für Buckets auszuführen, die genau mit diesem Präfix benannt sind. Sie könnten den S3-Bucket beispielsweise fabric-pool-AFF1 nennen, wobei AFF1 der Name des Clusters ist.
-
Lebenszyklus der Speicherklasse: Cloud Tiering verwaltet die Lebenszyklusübergänge Ihrer mehrstufigen Daten. Die Daten beginnen in der Klasse Standard, Sie können jedoch eine Regel erstellen, um nach einer bestimmten Anzahl von Tagen eine andere Speicherklasse auf die Daten anzuwenden.
Wählen Sie die S3-Speicherklasse aus, in die Sie die mehrstufigen Daten übertragen möchten, und die Anzahl der Tage, bevor die Daten dieser Klasse zugewiesen werden, und wählen Sie Weiter. Der folgende Screenshot zeigt beispielsweise, dass abgestufte Daten nach 45 Tagen im Objektspeicher von der Klasse Standard der Klasse Standard-IA zugewiesen werden.
Wenn Sie Daten in dieser Speicherklasse behalten wählen, verbleiben die Daten in der Standard-Speicherklasse und es werden keine Regeln angewendet. "Siehe unterstützte Speicherklassen" .
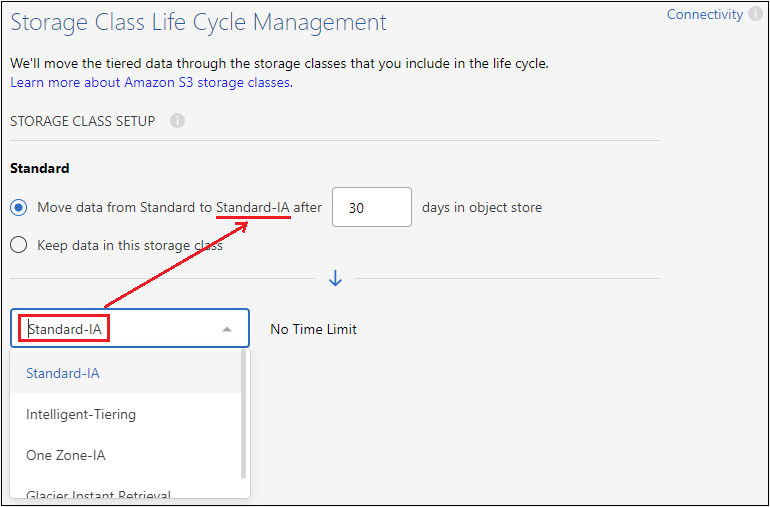
Beachten Sie, dass die Lebenszyklusregel auf alle Objekte im ausgewählten Bucket angewendet wird.
-
Anmeldeinformationen: Geben Sie die Zugriffsschlüssel-ID und den geheimen Schlüssel für einen IAM-Benutzer ein, der über die erforderlichen S3-Berechtigungen verfügt, und wählen Sie Weiter.
Der IAM-Benutzer muss sich im selben AWS-Konto befinden wie der Bucket, den Sie auf der Seite S3 Bucket ausgewählt oder erstellt haben. Die erforderlichen Berechtigungen finden Sie im Abschnitt zum Aktivieren der Tiering-Funktion.
-
Cluster-Netzwerk: Wählen Sie den IP-Bereich aus, den ONTAP für die Verbindung mit dem Objektspeicher verwenden soll, und wählen Sie Weiter.
Durch die Auswahl des richtigen IP-Bereichs wird sichergestellt, dass Cloud Tiering eine Verbindung von ONTAP zum Objektspeicher Ihres Cloud-Anbieters herstellen kann.
-
Der Objektspeicher wird erstellt.
Jetzt können Sie den Objektspeicher an ein Aggregat in Ihrem Cluster anhängen.
Einen zweiten Objektspeicher zur Spiegelung an ein Aggregat anhängen
Sie können einem Aggregat einen zweiten Objektspeicher hinzufügen, um einen FabricPool -Spiegel zu erstellen und Daten synchron auf zwei Objektspeicher zu verteilen. Sie müssen bereits einen Objektspeicher an das Aggregat angehängt haben. "Erfahren Sie mehr über FabricPool -Spiegel" .
Wenn Sie eine MetroCluster -Konfiguration verwenden, empfiehlt es sich, Objektspeicher in der öffentlichen Cloud zu verwenden, die sich in unterschiedlichen Verfügbarkeitszonen befinden. "Weitere Informationen zu den MetroCluster Anforderungen finden Sie in der ONTAP Dokumentation" . Innerhalb eines MetroCluster wird die Verwendung ungespiegelter Aggregate nicht empfohlen, da dies zu einer Fehlermeldung führt.
Wenn Sie StorageGRID als Objektspeicher in einer MetroCluster -Konfiguration verwenden, können beide ONTAP Systeme FabricPool -Tiering auf einem einzigen StorageGRID System durchführen. Jedes ONTAP -System muss Daten in verschiedene Buckets einteilen.
-
Wählen Sie auf der Seite Cluster die Option Erweiterte Einrichtung für den ausgewählten Cluster aus.

-
Ziehen Sie von der Seite „Erweiterte Einrichtung“ den gewünschten Objektspeicher an den Speicherort für den gespiegelten Objektspeicher.
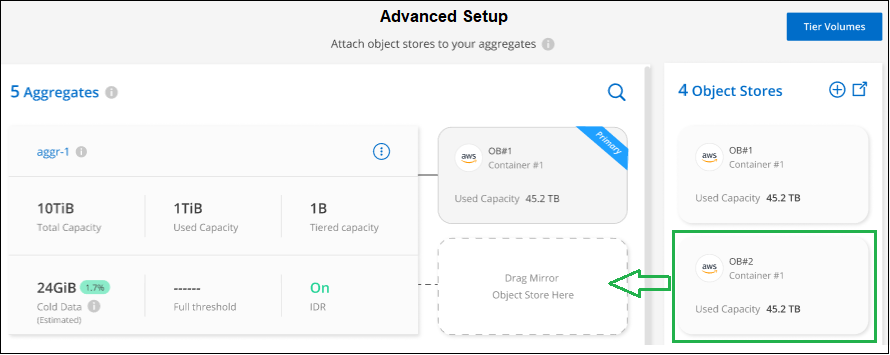
-
Wählen Sie im Dialogfeld „Objektspeicher anhängen“ die Option „Anhängen“ aus, und der zweite Objektspeicher wird an das Aggregat angehängt.
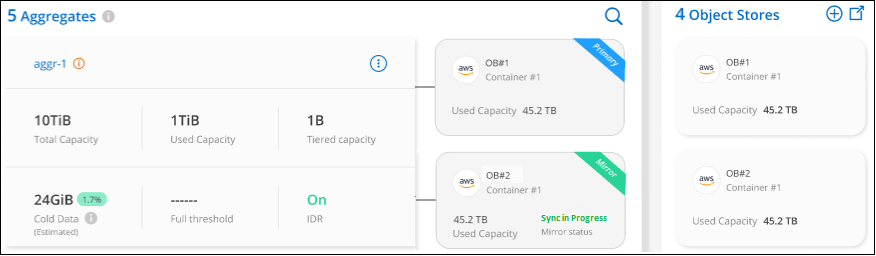
Während die beiden Objektspeicher synchronisiert werden, wird der Spiegelstatus als „Synchronisierung läuft“ angezeigt. Der Status ändert sich in „Synchronisiert“, wenn die Synchronisierung abgeschlossen ist.
Tauschen Sie den primären und den gespiegelten Objektspeicher aus
Sie können den primären und den gespiegelten Objektspeicher gegen ein Aggregat austauschen. Der Objektspeicherspiegel wird zum Primärspeicher und der ursprüngliche Primärspeicher wird zum Spiegelspeicher.
-
Wählen Sie auf der Seite Cluster die Option Erweiterte Einrichtung für den ausgewählten Cluster aus.
-
Wählen Sie auf der Seite „Erweiterte Einrichtung“ das Menüsymbol für das Aggregat und wählen Sie „Ziele tauschen“ aus.
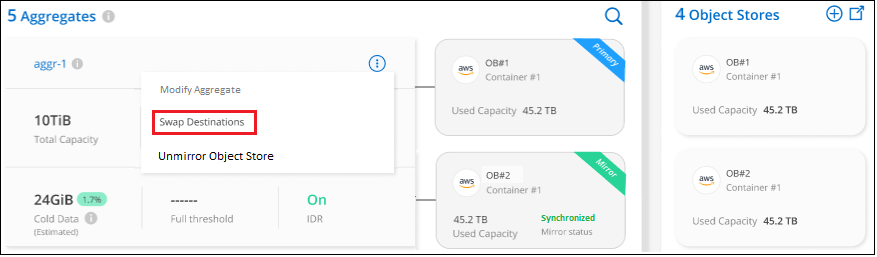
-
Bestätigen Sie die Aktion im Dialogfeld, und die Speicher der primären und gespiegelten Objekte werden vertauscht.
Entfernen eines gespiegelten Objektspeichers aus einem Aggregat
Sie können einen FabricPool Spiegel entfernen, wenn Sie keine Replikation mehr in einen zusätzlichen Objektspeicher benötigen.
-
Wählen Sie auf der Seite Cluster die Option Erweiterte Einrichtung für den ausgewählten Cluster aus.
-
Wählen Sie auf der Seite „Erweiterte Einrichtung“ das Menüsymbol für das Aggregat und wählen Sie „Objektspeicher aufheben“ aus.
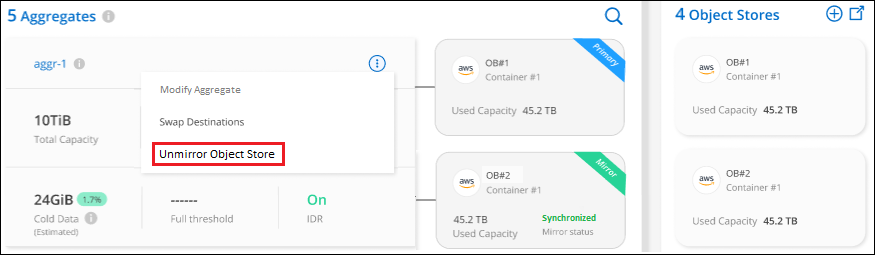
Der gespiegelte Objektspeicher wird aus dem Aggregat entfernt und die mehrstufigen Daten werden nicht mehr repliziert.

|
Wenn Sie den gespiegelten Objektspeicher aus einer MetroCluster -Konfiguration entfernen, werden Sie gefragt, ob Sie auch den primären Objektspeicher entfernen möchten. Sie können wählen, ob der primäre Objektspeicher mit dem Aggregat verbunden bleiben oder entfernt werden soll. |
Migrieren Sie Ihre mehrstufigen Daten zu einem anderen Cloud-Anbieter
Mit Cloud Tiering können Sie Ihre mehrstufigen Daten problemlos zu einem anderen Cloud-Anbieter migrieren. Wenn Sie beispielsweise von Amazon S3 zu Azure Blob wechseln möchten, können Sie die oben aufgeführten Schritte in dieser Reihenfolge ausführen:
-
Fügen Sie einen Azure Blob-Objektspeicher hinzu.
-
Hängen Sie diesen neuen Objektspeicher als Spiegel an das vorhandene Aggregat an.
-
Tauschen Sie den primären und den gespiegelten Objektspeicher aus.
-
Spiegeln Sie den Amazon S3-Objektspeicher nicht mehr.