

Scannen Sie Datenbankschemata mit NetApp Data Classification
 Änderungen vorschlagen
Änderungen vorschlagen
Führen Sie einige Schritte aus, um mit dem Scannen Ihrer Datenbankschemata mit NetApp Data Classification zu beginnen.
Überprüfen der Voraussetzungen
Überprüfen Sie die folgenden Voraussetzungen, um sicherzustellen, dass Sie über eine unterstützte Konfiguration verfügen, bevor Sie die Datenklassifizierung aktivieren.
Unterstützte Datenbanken
Die Datenklassifizierung kann Schemata aus den folgenden Datenbanken scannen:
-
Amazon Relational Database Service (Amazon RDS)
-
MongoDB
-
MySQL
-
Orakel
-
PostgreSQL
-
SAP HANA
-
SQL Server (MSSQL)

|
Die Funktion zum Sammeln von Statistiken muss in der Datenbank aktiviert sein. |
Datenbankanforderungen
Jede Datenbank mit Verbindung zur Datenklassifizierungsinstanz kann gescannt werden, unabhängig davon, wo sie gehostet wird. Um eine Verbindung zur Datenbank herzustellen, benötigen Sie lediglich die folgenden Informationen:
-
IP-Adresse oder Hostname
-
Hafen
-
Dienstname (nur für den Zugriff auf Oracle-Datenbanken)
-
Anmeldeinformationen, die Lesezugriff auf die Schemata ermöglichen
Bei der Auswahl eines Benutzernamens und Kennworts ist es wichtig, dass Sie einen Benutzernamen und ein Kennwort auswählen, der über vollständige Leseberechtigungen für alle Schemata und Tabellen verfügt, die Sie scannen möchten. Wir empfehlen Ihnen, einen dedizierten Benutzer für das Datenklassifizierungssystem mit allen erforderlichen Berechtigungen zu erstellen.

|
Für MongoDB ist eine schreibgeschützte Administratorrolle erforderlich. |
Bereitstellen der Datenklassifizierungsinstanz
Stellen Sie die Datenklassifizierung bereit, wenn noch keine Instanz bereitgestellt ist.
Wenn Sie Datenbankschemata scannen, die über das Internet zugänglich sind, können Sie"Datenklassifizierung in der Cloud bereitstellen" oder"Stellen Sie die Datenklassifizierung an einem lokalen Standort mit Internetzugang bereit" .
Wenn Sie Datenbankschemata scannen, die in einer Dark Site ohne Internetzugang installiert wurden, müssen Sie"Stellen Sie die Datenklassifizierung am selben lokalen Standort bereit, der keinen Internetzugang hat" . Dies erfordert auch, dass der Konsolenagent am selben lokalen Standort bereitgestellt wird.
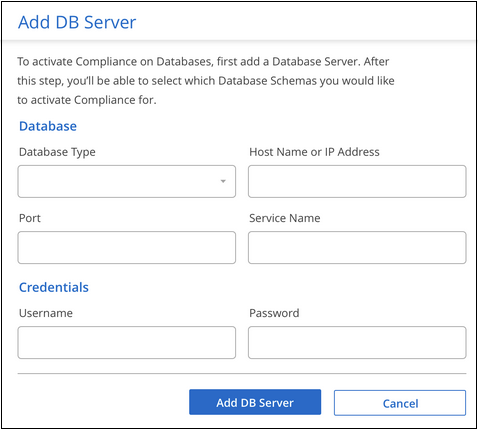
Hinzufügen des Datenbankservers
Fügen Sie den Datenbankserver hinzu, auf dem sich die Schemas befinden.
-
Wählen Sie im Menü „Datenklassifizierung“ die Option „Konfiguration“ aus.
-
Wählen Sie auf der Konfigurationsseite System hinzufügen > Datenbankserver hinzufügen.
-
Geben Sie die erforderlichen Informationen zur Identifizierung des Datenbankservers ein.
-
Wählen Sie den Datenbanktyp aus.
-
Geben Sie den Port und den Hostnamen oder die IP-Adresse ein, um eine Verbindung zur Datenbank herzustellen.
-
Geben Sie für Oracle-Datenbanken den Dienstnamen ein.
-
Geben Sie die Anmeldeinformationen ein, damit Data Classification auf den Server zugreifen kann.
-
Wählen Sie DB-Server hinzufügen.
-
Die Datenbank wird der Liste der Systeme hinzugefügt.
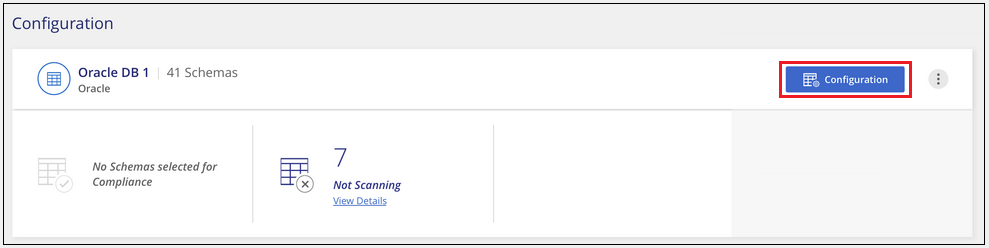
Aktivieren und Deaktivieren von Scans für Datenbankschemata
Sie können den vollständigen Scan Ihrer Schemata jederzeit stoppen oder starten.

|
Es gibt keine Option, nur Kartenscans für Datenbankschemata auszuwählen. |
-
Wählen Sie auf der Konfigurationsseite die Schaltfläche Verwalten für die Datenbank, die Sie konfigurieren möchten.
-
Wählen Sie für jedes Schema, für das Sie Scans aktivieren möchten, die Spalte Scan type aus und stellen Sie den Scan auf off oder Full scan ein.
Die Datenklassifizierung beginnt mit dem Scannen der von Ihnen aktivierten Datenbankschemata. Sie können den Fortschritt des ersten Scans verfolgen, indem Sie zum Menü Konfiguration navigieren und dann die Systemkonfiguration auswählen. Der Fortschritt jedes Scans wird als Fortschrittsbalken angezeigt. Sie können auch mit der Maus über den Fortschrittsbalken fahren, um die Anzahl der gescannten Dateien im Verhältnis zur Gesamtzahl der Dateien im Volume anzuzeigen. Wenn Fehler vorliegen, werden diese zusammen mit den erforderlichen Maßnahmen zur Behebung des Fehlers in der Spalte „Status“ angezeigt.
Die Datenklassifizierung scannt Ihre Datenbanken einmal pro Tag; Datenbanken werden nicht kontinuierlich gescannt wie andere Datenquellen.