

Failover von Anwendungen an einen Remote-Standort mit NetApp Disaster Recovery
 Änderungen vorschlagen
Änderungen vorschlagen
Führen Sie im Katastrophenfall ein Failover Ihres primären VMware-Standorts vor Ort auf einen anderen VMware-Standort vor Ort oder auf VMware Cloud auf AWS durch. Sie können den Failover-Prozess testen, um sicherzustellen, dass er bei Bedarf erfolgreich ist.
Erforderliche NetApp Console-Rolle Für die Ausführung dieser Aufgabe ist die Rolle „Superadmin“, „Disaster recovery admin“ oder „Disaster recovery failover admin“ erforderlich. "Erfahren Sie mehr über Benutzerrollen und Berechtigungen in NetApp Disaster Recovery". "Erfahren Sie mehr über die Zugriffsrollen der NetApp Console für alle Dienste".
Über diese Aufgabe
Im Falle eines Failovers verwendet Disaster Recovery standardmäßig die aktuellste SnapMirror Snapshot-Kopie. Sie können jedoch einen bestimmten Snapshot aus einem Point-in-Time-Snapshot auswählen (gemäß der Aufbewahrungsrichtlinie von SnapMirror). Verwenden Sie die Option „Zeitpunkt“.
Dieser Prozess unterscheidet sich, je nachdem, ob der Produktionsstandort fehlerfrei ist und Sie aus anderen Gründen als einem kritischen Infrastrukturausfall ein Failover zum Disaster Recovery-Standort durchführen:
-
Kritischer Produktionsstandortausfall, bei dem auf das Quell-vCenter oder den ONTAP Cluster nicht zugegriffen werden kann: Mit NetApp Disaster Recovery können Sie einen beliebigen verfügbaren Snapshot für die Wiederherstellung auswählen.
-
Die Produktionsumgebung ist fehlerfrei: Sie können entweder „Jetzt einen Snapshot erstellen“ oder einen zuvor erstellten Snapshot auswählen.
Dieses Verfahren unterbricht die Replikationsbeziehung, setzt die vCenter-Quell-VMs offline, registriert die Volumes als Datenspeicher im Disaster Recovery-vCenter, startet die geschützten VMs unter Verwendung der Failover-Regeln im Plan neu und aktiviert das Lesen/Schreiben auf der Zielsite.
Testen des Failover-Prozesses
Vor einem Live-Failover können Sie einen Test durchführen, um Ihre Bereitschaft zu überprüfen. Die Workloads bleiben während des Testvorgangs online.
Während eines Failover-Tests erstellt Disaster Recovery temporär VMs. Disaster Recovery ordnet einen temporären Datenspeicher, der das FlexClone Volume sichert, den ESXi-Hosts zu.
Dieser Prozess beansprucht keine zusätzliche physische Kapazität auf dem lokalen ONTAP Speicher oder dem FSx für NetApp ONTAP -Speicher in AWS. Das ursprüngliche Quellvolume wird nicht verändert, und Replikationsaufträge können auch während der Notfallwiederherstellung fortgesetzt werden.
Nach Abschluss des Tests sollten Sie die VMs mit der Option Test bereinigen zurücksetzen. Dies wird zwar empfohlen, ist aber nicht zwingend erforderlich.
Ein Test-Failover-Vorgang hat keine Auswirkungen auf Produktions-Workloads, die auf der Testsite verwendete SnapMirror -Beziehung und geschützte Workloads, die weiterhin normal ausgeführt werden müssen.
Für ein Test-Failover führt Disaster Recovery die folgenden Vorgänge aus:
-
Führen Sie Vorprüfungen des Zielclusters und der SnapMirror -Beziehung durch.
-
Erstellen Sie aus dem ausgewählten Snapshot für jedes geschützte ONTAP Volume auf dem ONTAP -Cluster des Zielstandorts ein neues FlexClone Volume.
-
Wenn es sich bei einem der Datenspeicher um VMFS handelt, erstellen Sie eine iGroup und ordnen Sie sie jeder LUN zu.
-
Registrieren Sie die Ziel-VMs innerhalb von vCenter als neue Datenspeicher.
-
Schalten Sie die Ziel-VMs gemäß der auf der Seite „Ressourcengruppen“ erfassten Startreihenfolge ein.
-
Führen Sie eine Stilllegung aller unterstützten Datenbankanwendungen in VMs durch, die als „anwendungskonsistent“ gekennzeichnet sind.
-
Wenn die Quell-vCenter- und ONTAP Cluster noch aktiv sind, erstellen Sie eine SnapMirror -Beziehung in umgekehrter Richtung, um alle Änderungen im Failover-Zustand zurück auf die ursprüngliche Quellsite zu replizieren.
-
Melden Sie sich an bei "NetApp Console" .
-
Wählen Sie in der linken Navigation der NetApp Console Schutz > Notfallwiederherstellung.
-
Wählen Sie im NetApp Disaster Recovery Menü Replikationspläne aus.
-
Wählen Sie den Replikationsplan aus.
-
Wählen Sie rechts die Option Aktionen*
 und wählen Sie *Failover testen.
und wählen Sie *Failover testen. -
Wählen Sie auf der Seite „Failover testen“ den Snapshot für den Failover-Test aus: Wählen Sie Jetzt Snapshot erstellen oder Auswählen, um einen vorhandenen Snapshot auszuwählen. Wenn Sie Auswählen wählen, wählen Sie den vorhandenen Snapshot aus.
Geben Sie anschließend „Test failover“ ein und wählen Sie Test fail over.
-
Nachdem der Test abgeschlossen ist, bereinigen Sie die Testumgebung.
Bereinigen der Testumgebung nach einem Failovertest
Nachdem der Failover-Test abgeschlossen ist, sollten Sie die Testumgebung bereinigen. Dieser Prozess entfernt die temporären VMs vom Teststandort, den FlexClones und den temporären Datenspeichern.
-
Wählen Sie im NetApp Disaster Recovery Menü Replikationspläne aus.
-
Wählen Sie den Replikationsplan aus.
-
Wählen Sie rechts die Option Aktionen aus.
dann Failover-Test bereinigen. -
Geben Sie auf der Seite „Test-Failover“ die Option „Failover bereinigen“ ein und wählen Sie dann Failover-Test bereinigen aus.
Führen Sie ein Failover des Quellstandorts auf einen Notfallwiederherstellungsstandort durch
Führen Sie im Katastrophenfall bei Bedarf ein Failover Ihres primären VMware-Standorts vor Ort auf einen anderen VMware-Standort vor Ort oder auf VMware Cloud auf AWS mit FSx für NetApp ONTAP durch.
Der Failover-Prozess umfasst die folgenden Vorgänge:
-
Disaster Recovery führt Vorprüfungen des Zielclusters und der SnapMirror -Beziehung durch.
-
Wenn Sie den neuesten Snapshot ausgewählt haben, wird das SnapMirror Update durchgeführt, um die neuesten Änderungen zu replizieren.
-
Die Quell-VMs sind heruntergefahren.
-
Die SnapMirror Beziehung ist unterbrochen und das Ziel-Volume ist nun lesen/schreiben.
-
Basierend auf der Auswahl des Snapshots wird das aktive Dateisystem auf den angegebenen Snapshot (neuester oder ausgewählter) wiederhergestellt.
-
Datenspeicher werden basierend auf den im Replikationsplan erfassten Informationen erstellt und im VMware- oder VMC-Cluster oder -Host bereitgestellt. Wenn es sich bei einem der Datenspeicher um VMFS handelt, erstellen Sie eine iGroup und ordnen Sie sie jeder LUN zu.
-
Die Ziel-VMs werden innerhalb von vCenter als neue Datenspeicher registriert.
-
Die Ziel-VMs werden gemäß der auf der Seite „Ressourcengruppen“ erfassten Bootreihenfolge eingeschaltet.
-
Wenn das Quell-vCenter noch aktiv ist, schalten Sie alle VMs auf der Quellseite aus, für die ein Failover durchgeführt wird.
-
Führen Sie eine Stilllegung aller unterstützten Datenbankanwendungen in VMs durch, die als „anwendungskonsistent“ gekennzeichnet sind.
-
Wenn die Quell-vCenter- und ONTAP Cluster noch aktiv sind, erstellen Sie eine SnapMirror -Beziehung in umgekehrter Richtung, um alle Änderungen im Failover-Zustand zurück auf die ursprüngliche Quellsite zu replizieren. Die SnapMirror -Beziehung wird von der Ziel- zur Quell-VM umgekehrt.

|
Nach dem Start des Failovers können Sie die wiederhergestellten VMs im vCenter der Notfallwiederherstellungsumgebung (VMs, Netzwerke und Datenspeicher) sehen. Standardmäßig werden die VMs im Ordner Workload wiederhergestellt. |
Bei datenspeicherbasierten Replikationsplänen werden VMs, die Sie hinzugefügt und erkannt haben, für die aber keine Zuordnungsdetails angegeben wurden, in das Failover einbezogen. Der Failover schlägt fehl und es wird eine Benachrichtigung in den Jobs angezeigt. Sie müssen die Zuordnungsdetails angeben, um das Failover erfolgreich abzuschließen.

|
Falls der Replikationsplan einen leeren Datenspeicher enthält, müssen Sie zuerst den leeren Datenspeicher aus dem Plan entfernen oder die Option Force failover verwenden, die die leeren Datenspeicher überspringt. |
-
Wählen Sie im NetApp Disaster Recovery Menü Replikationspläne aus.
-
Im Dropdown-Menü nach vCenter Replikationsplänen filtern.
-
Wählen Sie den Replikationsplan aus.
-
Wählen Sie rechts die Option Aktionen aus
, bewegen Sie den Mauszeiger über Wiederherstellen und wählen Sie dann Fail over aus.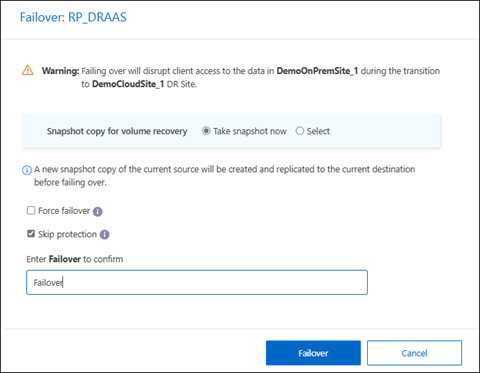
-
Auf der Failover-Seite können Sie entweder jetzt einen neuen Snapshot erstellen oder einen vorhandenen Snapshot für den Datenspeicher auswählen, der als Grundlage für die Wiederherstellung dienen soll. Standardmäßig wird die neueste Version verwendet.
Vor dem Failover wird ein Snapshot der aktuellen Quelle erstellt und zum aktuellen Ziel repliziert.
-
Wählen Sie Failover erzwingen, wenn der Failover auch dann erfolgen soll, wenn ein Fehler erkannt wird, der normalerweise das Auftreten des Failovers verhindern würde.
-
Wählen Sie Schutz überspringen, wenn der Dienst nicht automatisch eine umgekehrte SnapMirror Schutzbeziehung nach einem Failover des Replikationsplans erstellen soll. Dies ist hilfreich, wenn Sie zusätzliche Vorgänge am wiederhergestellten Standort durchführen möchten, bevor Sie ihn im Rahmen der NetApp Disaster Recovery wieder online schalten.
Sie können einen umgekehrten Schutz einrichten, indem Sie im Menü „Aktionen“ des Replikationsplans die Option „Ressourcen schützen“ auswählen. Dadurch wird versucht, für jedes Volume im Plan eine umgekehrte Replikationsbeziehung zu erstellen. Sie können diesen Job wiederholt ausführen, bis der Schutz wiederhergestellt ist. Wenn der Schutz wiederhergestellt ist, können Sie auf die übliche Weise ein Failback einleiten. -
Geben Sie „Failover“ in das Feld ein.
-
Wählen Sie Failover.
-
Um den Fortschritt zu überprüfen, wählen Sie im Menü Jobüberwachung.
-
Wählen Sie im NetApp Disaster Recovery Menü Replikationspläne aus.
-
Im Dropdown-Menü nach Kubernetes-Replikationsplänen filtern.
-
Wählen Sie den Replikationsplan aus.
-
Wählen Sie rechts die Option Aktionen aus
, bewegen Sie den Mauszeiger über Wiederherstellen und wählen Sie dann Fail over aus. -
Wählen Sie die Snapshot-Kopie aus, die Sie für das Failover verwenden möchten. Sie können Jetzt Snapshot erstellen wählen, um einen brandneuen Snapshot zu erstellen, der in den Ziel-Cluster kopiert wird, oder Neuesten Snapshot verwenden, um den aktuellsten verfügbaren Snapshot im Ziel-Cluster zu verwenden.
-
Wählen Sie Schutz überspringen, wenn der Dienst nicht automatisch eine umgekehrte SnapMirror Schutzbeziehung nach einem Failover des Replikationsplans erstellen soll. Dies ist hilfreich, wenn Sie zusätzliche Vorgänge am wiederhergestellten Standort durchführen möchten, bevor Sie ihn im Rahmen der NetApp Disaster Recovery wieder online schalten.
-
Geben Sie „Failover“ ein, um die Aktion zu bestätigen, und wählen Sie dann Failover aus.
Den Status des Auftrags können Sie unter Job monitoring oder Replication plans überwachen.