TR-4920: FlexPod Datacenter mit NetApp SnapMirror Business Continuity und ONTAP 9.10
 Änderungen vorschlagen
Änderungen vorschlagen
Jyh-shing Chen, NetApp
Einführung
Die FlexPod Lösung
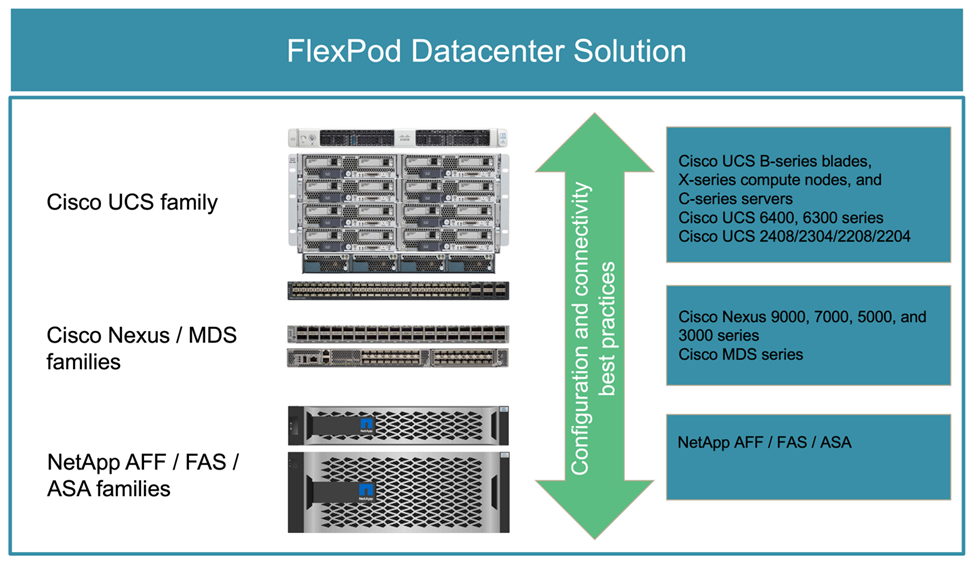
FlexPod ist eine Best-Practice-Architektur für konvergente Infrastrukturen, die die folgenden Komponenten von Cisco und NetApp umfasst:
-
Cisco Unified Computing System (Cisco UCS)
-
Cisco Nexus und MDS Switches-Familien
-
NetApp FAS, NetApp AFF und NetApp All SAN Array (ASA) Systeme
Die folgende Abbildung zeigt einige der zum Erstellen von FlexPod Lösungen verwendeten Komponenten. Diese Komponenten sind sowohl von Cisco als auch von NetApp entsprechend den Best Practices miteinander verbunden und konfiguriert, sodass eine ideale Plattform für eine Vielzahl von Enterprise Workloads ohne Bedenken eingesetzt werden kann.
Es ist ein großes Portfolio von Cisco Validated Designs (CVDs) und NetApp Verified Architectures (NVAs) erhältlich. Diese CVDs und NVAs decken alle größeren Datacenter-Workloads ab und sind das Ergebnis der kontinuierlichen Zusammenarbeit und Innovationen zwischen NetApp und Cisco auf den FlexPod-Lösungen.
FlexPod CVDs und NVAs enthalten umfangreiche Tests und Validierungen im Erstellungsprozess. Außerdem bieten sie Referenzarchitekturen-Designs sowie Schritt-für-Schritt-Anleitungen für die Implementierung von FlexPod Lösungen für Partner und Kunden. Wenn Unternehmen diese CVDs und NVAs als Leitfäden für Design und Implementierung einsetzen, können sie Risiken verringern, das Ausfallzeiten der Lösung verringern und die Verfügbarkeit, Skalierbarkeit, Flexibilität und Sicherheit der implementierten FlexPod Lösungen erhöhen.
Jede der gezeigten FlexPod-Komponentenfamilien (Cisco UCS, Cisco Nexus/MDS Switches und NetApp Storage) bietet Plattform- und Ressourcenoptionen für die vertikale und horizontale Skalierung der Infrastruktur. Gleichzeitig werden die Funktionen unterstützt, die unter den Best Practices für Konfiguration und Konnektivität von FlexPod erforderlich sind. FlexPod kann auch horizontal für Umgebungen skaliert werden, in denen mehrere konsistente Implementierungen durch die Bereitstellung weiterer FlexPod-Stacks erforderlich sind.
Disaster Recovery und Business Continuity
Unternehmen können auf verschiedene Weise sicherstellen, dass sie ihre Applikations- und Datenservices nach Ausfällen schnell wiederherstellen können. Mit einem Disaster Recovery- (DR-) und Business Continuity- Plan (BC), der Implementierung einer Lösung, die die Geschäftsziele erfüllt, und durch regelmäßige Tests der Disaster-Szenarien können Unternehmen die Wiederherstellung nach einem Notfall durchführen und wichtige Business Services nach einem Notfall aufrechterhalten.
Für verschiedene Applikations- und Datenservices können Unternehmen unterschiedliche DR- und BC-Anforderungen haben. Einige Applikationen und Daten sind möglicherweise nicht in Notfällen oder Notfallsituationen notwendig, während andere Unternehmen möglicherweise kontinuierlich zur Verfügung stehen müssen, um geschäftliche Anforderungen zu unterstützen.
Für geschäftskritische Applikations- und Datenservices, die den Betrieb stören könnten, wenn diese nicht verfügbar sind, ist eine sorgfältige Evaluierung erforderlich, um Fragen wie Wartungsarbeiten und Ausfallszenarien zu beantworten, die Ihr Unternehmen in Betracht ziehen sollte, Wie viele Daten das Unternehmen bei einem Ausfall verkraften kann und wie schnell die Recovery erfolgen kann und sollte.
Für Unternehmen, die Datenservices zur Umsatzgenerierung nutzen, müssen die Datenservices möglicherweise durch eine Lösung geschützt werden, die nicht nur verschiedenen Single-Point-of-Failure-Szenarien, sondern auch einem Ausfallszenario am Standort standhält, um den unterbrechungsfreien Geschäftsbetrieb zu gewährleisten.
Recovery-Zeitpunkt und Recovery-Zeitvorgabe
Der Recovery-Zeitpunkt (Recovery Point Objective, RPO) bezeichnet die Menge an Daten im Hinblick auf die Zeit, die Sie sich leisten können, oder den Zeitpunkt, an dem Sie Ihre Daten wiederherstellen können. Mit einem täglichen Backup-Plan kann ein Unternehmen einen Tag an Daten verlieren, weil die Änderungen an den Daten seit dem letzten Backup in einem Notfall verloren gehen könnte. Für geschäftskritische und geschäftskritische Datenservices sind unter Umständen ein RPO von Null sowie ein Plan und eine zugehörige Infrastruktur zum Schutz von Daten ohne Datenverluste erforderlich.
Die Recovery-Zeitvorgabe (Recovery Time Objective, RTO) beschreibt, wie lange Sie sich leisten können, ohne die Daten verfügbar zu haben oder wie schnell Datenservices gesichert werden müssen. So kann ein Unternehmen beispielsweise über eine Backup- und Recovery-Implementierung verfügen, bei der aufgrund seiner Größe herkömmliche Tapes für bestimmte Datensätze verwendet werden. Das Ergebnis: Die Wiederherstellung der Daten von den Backup-Tapes kann es im Falle eines Infrastruktur-Ausfalls mehrere Stunden oder gar Tage dauern. Überlegungen zur Zeit müssen außerdem die Zeit beinhalten, die erforderlich ist, um die Infrastruktur zusätzlich zum Wiederherstellen der Daten zu sichern. Für geschäftskritische Datenservices benötigen Sie unter Umständen ein sehr niedriges RTO und können daher für Business Continuity nur eine Failover-Zeit von Sekunden oder Minuten tolerieren, um die Datenservices schnell wieder online zu bringen.
SM-BC
Ab ONTAP 9.8 können Sie SAN-Workloads für transparentes Applikations-Failover mit NetApp SM-BC sichern. Sie können Konsistenzgruppen zwischen zwei AFF Clustern oder zwei ASA Clustern erstellen, um Daten zu replizieren, damit ein Recovery Point Objective von null und ein Recovery Time Objective von fast null erreicht wird.
Die SM-BC Lösung repliziert Daten mithilfe der SnapMirror Synchronous Technologie über ein IP-Netzwerk. Die Lösung bietet Granularität auf Applikationsebene und automatisches Failover zur Sicherung geschäftskritischer Daten-Services wie Microsoft SQL Server, Oracle usw. mit iSCSI oder FC protokollbasierten SAN LUNs. Ein an einem dritten Standort bereitgestellter ONTAP Mediator überwacht die SM-BC-Lösung und ermöglicht ein automatisches Failover bei einem Standortausfall.
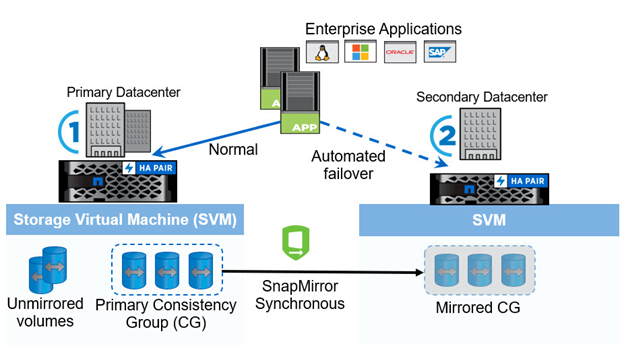
Eine Konsistenzgruppe (CG) ist eine Sammlung von FlexVol-Volumes, die eine konsistente Schreibreihenfolge für den Applikations-Workload gewährleistet, der zur Gewährleistung der Business Continuity geschützt werden muss. Es ermöglicht gleichzeitige, absturzkonsistente Snapshot-Kopien einer Sammlung von Volumes zu einem bestimmten Zeitpunkt. Eine SnapMirror-Beziehung, auch als CG-Beziehung bekannt, wird zwischen einer Quell-CG und einer Ziel-CG eingerichtet. Die Gruppe der Volumes, die als Teil einer CG ausgewählt wurden, kann einer Applikationsinstanz, einer Gruppe von Applikationsinstanzen oder für eine komplette Lösung zugeordnet werden. Darüber hinaus können auf der Grundlage von Geschäftsanforderungen und Änderungen die Beziehungen der SM-BC Consistency Group nach Bedarf erstellt oder gelöscht werden.
Wie in der folgenden Abbildung dargestellt, werden die Daten in der Konsistenzgruppe für Disaster Recovery und Business Continuity in einen zweiten ONTAP Cluster repliziert. Die Anwendungen haben Konnektivität zu den LUNs in beiden ONTAP-Clustern. I/O wird normalerweise vom primären Cluster bereitgestellt und setzt diesen automatisch vom sekundären Cluster fort, falls auf dem primären Cluster ein Notfall auftritt. Beim Design einer SM-BC-Lösung muss die unterstützte Objektanzahl für die CG-Beziehungen (z. B. maximal 20 CGS und maximal 200 Endpunkte) beachtet werden, um zu vermeiden, dass die unterstützten Grenzwerte überschritten werden.