

FabricPool
 Änderungen vorschlagen
Änderungen vorschlagen
Übersicht über FabricPool
FabricPool ist eine Hybrid-Storage-Lösung in ONTAP mit einem All-Flash-Aggregat (SSD) als Performance-Tier und einem Objektspeicher in einem Public-Cloud-Service als Cloud-Tier. Diese Konfiguration ermöglicht richtlinienbasierte Datenverschiebung, je nachdem, ob häufig auf Daten zugegriffen wird. FabricPool wird in ONTAP sowohl für AFF- als auch für rein SSD-basierte Aggregate auf den FAS Plattformen unterstützt. Die Datenverarbeitung erfolgt auf Blockebene, wobei häufig abgerufene Datenblöcke in der All-Flash-Performance-Tier mit als „heiße“ und selten genutzte Blöcke gekennzeichnet sind.
Mit FabricPool können Sie die Storage-Kosten senken, ohne dabei auf Performance, Effizienz, Sicherheit oder Schutz verzichten zu müssen. FabricPool ist transparent für Enterprise-Applikationen und nutzt Cloud-Effizienz durch niedrigere Storage-TCO, ohne dass der Aufbau der Applikationsinfrastruktur umgestaltet werden muss.
FlexPod bietet die Storage Tiering-Funktionen von FabricPool für eine effizientere Nutzung von ONTAP Flash Storage. Inaktive Virtual Machines (VMs), selten genutzte VM-Vorlagen und VM-Backups von NetApp SnapCenter für vSphere können wertvollen Speicherplatz im Datastore-Volume belegen. Durch das Verschieben selten genutzter Daten in die Cloud-Tier werden Speicherplatz und Ressourcen für hochperformante, geschäftskritische Applikationen freigegeben, die in der FlexPod-Infrastruktur gehostet werden.

|
Die Fibre Channel- und iSCSI-Protokolle dauern im Allgemeinen länger, bevor eine Zeitüberschreitung von 60 bis 120 Sekunden auftritt. Sie versuchen jedoch nicht, eine Verbindung auf die gleiche Weise einzurichten, wie es die NAS-Protokolle tun. Wenn ein SAN-Protokoll nicht mehr verfügbar ist, muss die Anwendung neu gestartet werden. Selbst eine kurze Störung kann verheerende Folgen für Produktionsapplikationen mit SAN-Protokollen haben, da keine Möglichkeit besteht, die Verbindung mit öffentlichen Clouds zu garantieren. Um dieses Problem zu vermeiden, empfiehlt NetApp die Verwendung von Private Clouds beim Tiering von Daten, auf die SAN-Protokolle zugreifen. |
In ONTAP 9.6 lässt sich FabricPool mit allen wichtigen Public-Cloud-Providern integrieren: Alibaba Cloud Object Storage Service, Amazon AWS S3, Google Cloud Storage, IBM Cloud Object Storage und Microsoft Azure Blob Storage. In diesem Bericht wird der Schwerpunkt auf Amazon AWS S3 Storage als Cloud-Objekt-Tier der Wahl gelegt.
Das zusammengesetzte Aggregat
Eine FabricPool Instanz wird erstellt, indem ein ONTAP Flash-Aggregat mit einem Cloud-Objektspeicher wie einem AWS S3-Bucket verknüpft wird, um ein gruppiertes Aggregat zu erstellen. Wenn Volumes innerhalb des zusammengesetzten Aggregats erstellt werden, können sie die Tiering-Funktionen von FabricPool nutzen. Wenn Daten auf das Volume geschrieben werden, weist ONTAP jedem der Datenblöcke eine Temperatur zu. Wird der Block zum ersten Mal geschrieben, wird ihm die Temperatur „heiß“ zugewiesen. Im Verlauf der Zeit wird bei nicht abgerufenen Daten ein Kühlvorgang durchlaufen, bis dieser schließlich einem „kalten“ Status zugewiesen wird. Diese selten genutzten Datenblöcke werden dann vom Performance-SSD-Aggregat und in den Cloud-Objektspeicher verschoben.
Die Zeitspanne zwischen dem „Kaltstart“ und dem Verschieben in den Cloud-Objektspeicher wird durch die Volume-Tiering-Richtlinie in ONTAP geändert. Weitere Granularität wird durch Ändern der ONTAP-Einstellungen erreicht, die die Anzahl der Tage, die für einen Block „kalt“ werden, steuern. Kandidaten für Daten-Tiering sind herkömmliche Volume-Snapshots, SnapCenter für vSphere VM-Backups und andere Snapshot-basierte Backups von NetApp und alle unregelmäßig genutzten Blöcke in einem vSphere Datastore, z. B. VM-Vorlagen und selten verwendete VM-Daten.
Berichterstellung für inaktive Daten
In ONTAP steht die Berichterstellung für inaktive Daten (Inactive Data Reporting, IDR) zur Verfügung. Dies unterstützt Sie bei der Bewertung der Menge an kalten Daten, die von einem Aggregat verteilt werden können. IDR ist in ONTAP 9.6 standardmäßig aktiviert und verwendet eine standardmäßige Kühlrichtlinie für 31 Tage, um zu bestimmen, welche Daten im Volume inaktiv sind.
|
|
Die Menge der „kalten“ Daten in Tier hängt von den Tiering-Richtlinien ab, die für das Volume festgelegt sind. Diese Menge kann sich von der Menge der kalten Daten unterscheiden, die von IDR unter Verwendung der standardmäßigen 31-Tage-Kühldauer erkannt wurden. |
Erstellen von Objekten und Verschieben von Daten
FabricPool arbeitet auf Blockebene von NetApp WAFL, wobei Kühlblöcke, sie in Storage-Objekte verketten und diese Objekte auf eine Cloud-Tier migrieren. Jedes FabricPool Objekt hat 4 MB und besteht aus 1,024 4-KB-Blöcken. Die Objektgröße wurde auf 4 MB festgelegt, basierend auf Performance-Empfehlungen führender Cloud-Provider und kann nicht geändert werden. Wenn „kalte“ Blöcke gelesen und wieder „heiß“ werden, werden nur die angeforderten Blöcke im 4-MB-Objekt abgerufen und zurück zur Performance-Tier verschoben. Weder das gesamte Objekt noch die gesamte Datei werden zurückmigriert. Es werden nur die erforderlichen Blöcke migriert.
|
|
Wenn ONTAP eine Möglichkeit für sequenzielle Leseköpfe erkennt, fordert die IT Blöcke aus dem Cloud-Tier an, bevor sie gelesen werden, um die Performance zu verbessern. |
Daten werden standardmäßig nur dann in den Cloud-Tier verschoben, wenn das Performance-Aggregat zu mehr als 50 % genutzt wird. Dieser Schwellenwert kann auf einen niedrigeren Prozentsatz festgelegt werden, um eine kleinere Menge an Daten-Storage auf dem Flash-Tier mit der Performance in die Cloud zu verschieben. Dies könnte nützlich sein, wenn die Tiering-Strategie dazu dient, nur kalte Daten zu verschieben, wenn sich das Aggregat der Kapazität nähert.
Wenn die Performance-Tier-Auslastung bei einer Kapazität von mehr als 70 % liegt, werden kalte Daten direkt aus der Cloud-Tier gelesen, ohne zurück in die Performance-Tier geschrieben zu werden. Durch Verhinderung von Datenschreibbacks auf stark ausgelasteten Aggregaten erhält FabricPool das Aggregat für aktive Daten aufrecht.
Performance-Tier-Speicherplatz zurückgewinnen
Wie bereits erwähnt, besteht der primäre Anwendungsfall für FabricPool darin, hochperformante On-Premises-Flash-Storage am effizientesten zu nutzen. „Kalte“ Daten in Form von Volume-Snapshots und VM-Backups der virtuellen FlexPod Infrastruktur beanspruchen unter kann viel teuren Flash-Storage. Wertvolle Performance- Tiered Storage kann durch die Implementierung von zwei Tiering-Richtlinien freigegeben werden: Nur Snapshot oder Auto.
Richtlinie für ausschließlich Snapshot-Tiering
Mit der in der folgenden Abbildung gezeigten Richtlinie zum ausschließlich Snapshot Tiering werden Snapshot Daten für kalte Volumes und SnapCenter für vSphere Backups von VMs, die Speicherplatz belegen, aber keine Blöcke gemeinsam mit dem aktiven Filesystem an einen Cloud-Objektspeicher freigeben. Die reine Snapshot-Tiering-Richtlinie verschiebt selten genutzte Datenblöcke auf die Cloud-Tier. Wenn eine Wiederherstellung erforderlich ist, werden kalte Blöcke in der Cloud als „heiße“ und zurück in das Flash-Tier mit der Performance vor Ort verschoben.
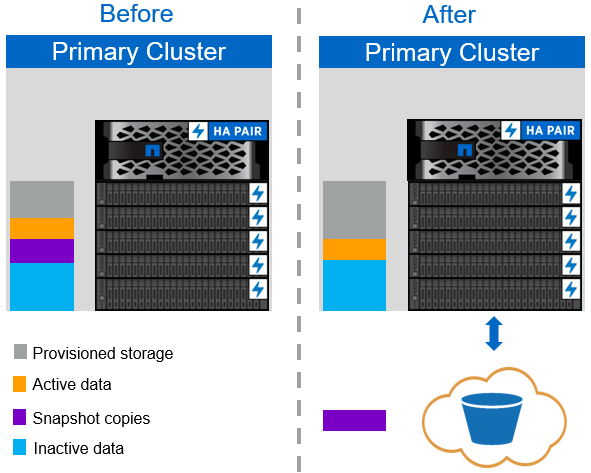
Automatisches Tiering
Die in der folgenden Abbildung dargestellte FabricPool Auto Tiering-Richtlinie verschiebt nicht nur kalte Snapshot Datenblöcke in die Cloud, sondern auch alle kalten Blöcke im aktiven Filesystem. Dies kann VM-Vorlagen und sämtliche nicht verwendeten VM-Daten im Datastore Volume enthalten. Welche kalten Blöcke bewegt werden, wird vom gesteuert tiering-minimum-cooling-days Einstellung für die Lautstärke. Wenn kalte Blöcke im Cloud-Tier von einer Applikation zufällig gelesen werden, werden diese Blöcke „heiß“ gemacht und zurück auf die Performance-Tier gebracht. Wenn jedoch kalte Blöcke durch einen sequenziellen Prozess wie einen Virenschutzscanner gelesen werden, bleiben die Blöcke im Cloud-Objektspeicher erhalten und bleiben erhalten. Sie werden nicht zurück auf die Performance-Tier verschoben.
Bei Verwendung der Auto-Tiering-Richtlinie werden Blöcke, auf die selten zugegriffen wird, mit denen die Daten häufig abgerufen werden, von der Cloud-Tier mit der Geschwindigkeit der Cloud-Konnektivität zurückgeholt. Dies kann sich auf die VM-Performance auswirken, wenn die Applikation latenzempfindlich ist. Dies sollte vor der Verwendung der Auto-Tiering-Richtlinie für den Datastore in Betracht gezogen werden. NetApp empfiehlt, LIFs über Ports mit einer Geschwindigkeit von 10 GbE zu aktivieren, um eine ausreichende Performance zu erzielen.
|
|
Der Objektspeicher-Profiler sollte verwendet werden, um die Latenz und den Durchsatz beim Objektspeicher zu testen, bevor sie an ein FabricPool Aggregat angehängt werden. |
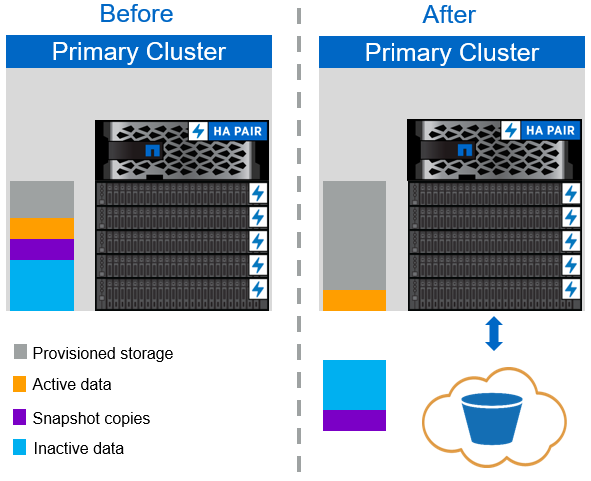
Alle Tiering-Richtlinien
Im Gegensatz zu den reinen Snapshot- und Auto-Richtlinien werden bei der All-Tiering-Richtlinie ganze Datenvolumen sofort in die Cloud-Tier verschoben. Diese Richtlinie eignet sich am besten für sekundäre Datensicherungs- oder Archivierungs-Volumes, für die Daten zwar zu historischen oder gesetzlichen Zwecken aufbewahrt werden müssen, aber nur selten benötigt werden. Die Richtlinie „Alle“ wird für VMware Datastore Volumes nicht empfohlen, da alle in den Datastore geschriebenen Daten sofort in die Cloud-Tier verschoben werden. Nachfolgende Lesezugriffe werden aus der Cloud durchgeführt und können möglicherweise zu Performance-Problemen für VMs und Applikationen im Datastore Volume führen.
Sicherheit
Die Sicherheit spielt für die Cloud und für FabricPool eine zentrale Rolle. Alle nativen Sicherheitsfunktionen von ONTAP werden in der Performance-Tier unterstützt und das Verschieben von Daten ist bei der Übertragung in die Cloud-Tier sicher. FabricPool verwendet das "AES-256-GCM" Der Verschlüsselungsalgorithmus auf der Performance-Tier bleibt über eine End-to-End-Verschlüsselung in der Cloud-Tier erhalten. Datenblöcke, die in den Cloud-Objektspeicher verschoben werden, sind mit TLS (Transport Layer Security) v1.2 gesichert, um die Datenvertraulichkeit und -Integrität zwischen Storage Tiers zu wahren.
|
|
Die Kommunikation mit dem Cloud-Objektspeicher über eine unverschlüsselte Verbindung wird von NetApp unterstützt, wird aber nicht empfohlen. |
Datenverschlüsselung
Die Datenverschlüsselung ist entscheidend für den Schutz geistigen Eigentums, Handelsinformationen und persönlich identifizierbare Kundeninformationen. FabricPool unterstützt sowohl NetApp Volume Encryption (NVE) als auch NetApp Storage Encryption (NSE) vollständig, um bestehende Datensicherungsstrategien zu beibehalten. Alle verschlüsselten Daten auf der Performance-Tier bleiben beim Verschieben in die Cloud-Tier verschlüsselt. Die Client-seitige Verschlüsselung befindet sich im Eigentum von ONTAP, und die serverseitigen Objektspeicherschlüssel sind im Eigentum des jeweiligen Cloud-Objektspeichers. Nicht mit NVE verschlüsselte Daten werden über den AES-256-GCM-Algorithmus verschlüsselt. Keine anderen AES-256-Chiffren werden unterstützt.
|
|
Die Verwendung von NSE oder NVE ist optional und muss nicht FabricPool verwenden. |