

Lösungstechnologie
 Änderungen vorschlagen
Änderungen vorschlagen
Diese Lösung nutzt die folgenden Technologien:
-
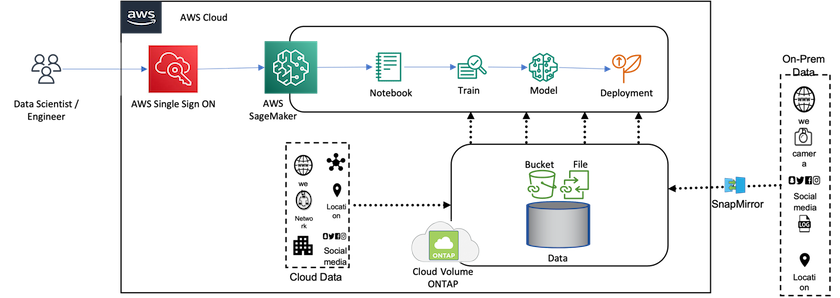
AWS SageMaker-Notizbuch. Bietet Entwicklern und Datenwissenschaftlern Machine-Learning-Funktionen zum effizienten Erstellen, Trainieren und Bereitstellen hochwertiger ML-Modelle.
-
* NetApp BlueXP.* Ermöglicht die Erkennung, Bereitstellung und den Betrieb von Speicher vor Ort sowie auf AWS, Azure und Google Cloud. Es bietet Datenschutz vor Datenverlust, Cyberbedrohungen und ungeplanten Ausfällen und optimiert die Datenspeicherung und Infrastruktur.
-
* NetApp Cloud Volumes ONTAP.* Bietet Speichervolumes der Unternehmensklasse mit NFS-, SMB/CIFS-, iSCSI- und S3-Protokollen auf AWS, Azure und Google Cloud und bietet Benutzern so mehr Flexibilität beim Zugriff auf und der Verwaltung ihrer Daten in der Cloud.
Aus BlueXP erstelltes NetApp Cloud Volumes ONTAP zum Speichern von ML-Daten.
Die folgende Abbildung zeigt die technischen Komponenten der Lösung.
Zusammenfassung des Anwendungsfalls
Ein potenzieller Anwendungsfall für den Dualprotokollzugriff von NFS und S3 liegt in den Bereichen maschinelles Lernen und Datenwissenschaft. Beispielsweise könnte ein Team von Datenwissenschaftlern an einem Machine-Learning-Projekt mit AWS SageMaker arbeiten, das Zugriff auf im NFS-Format gespeicherte Daten erfordert. Möglicherweise müssen die Daten jedoch auch über S3-Buckets abgerufen und freigegeben werden, um mit anderen Teammitgliedern zusammenzuarbeiten oder sie in andere Anwendungen zu integrieren, die S3 verwenden.
Durch die Nutzung von NetApp Cloud Volumes ONTAP kann das Team seine Daten an einem einzigen Ort speichern und darauf sowohl mit NFS- als auch mit S3-Protokollen zugreifen. Die Datenwissenschaftler können direkt von AWS SageMaker auf die Daten im NFS-Format zugreifen, während andere Teammitglieder oder Anwendungen über S3-Buckets auf dieselben Daten zugreifen können.
Dieser Ansatz ermöglicht einen einfachen und effizienten Zugriff auf die Daten und deren gemeinsame Nutzung, ohne dass zusätzliche Software oder eine Datenmigration zwischen verschiedenen Speicherlösungen erforderlich ist. Darüber hinaus ermöglicht es einen optimierten Arbeitsablauf und eine bessere Zusammenarbeit zwischen den Teammitgliedern, was zu einer schnelleren und effektiveren Entwicklung von Modellen für maschinelles Lernen führt.