

Kundenanwendungsfälle
 Änderungen vorschlagen
Änderungen vorschlagen
NetApp ActiveIQ Anwendungsfall
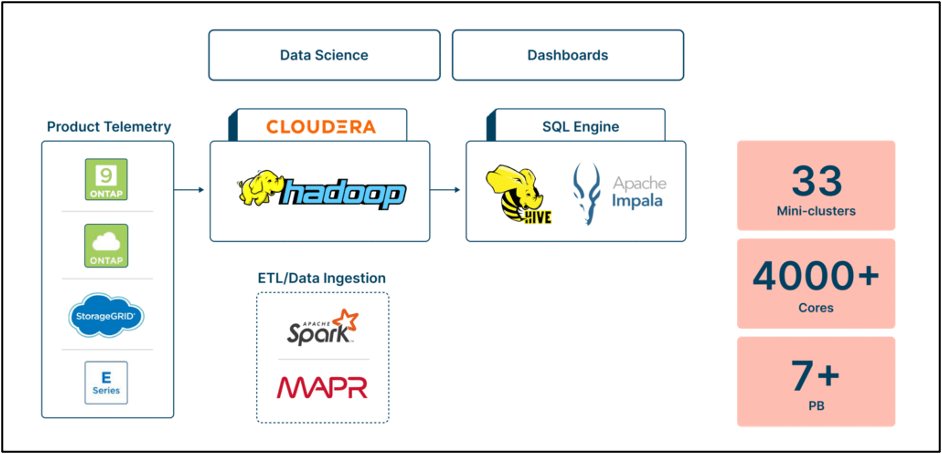
Herausforderung: NetApps eigene interne Active IQ Lösung, die ursprünglich zur Unterstützung zahlreicher Anwendungsfälle konzipiert wurde, hat sich zu einem umfassenden Angebot sowohl für interne Benutzer als auch für Kunden entwickelt. Allerdings stellte die zugrunde liegende Hadoop/MapR-basierte Backend-Infrastruktur aufgrund des schnellen Datenwachstums und der Notwendigkeit eines effizienten Datenzugriffs Herausforderungen hinsichtlich Kosten und Leistung dar. Die Skalierung des Speichers bedeutete das Hinzufügen unnötiger Rechenressourcen, was zu höheren Kosten führte.
Darüber hinaus war die Verwaltung des Hadoop-Clusters zeitaufwändig und erforderte spezielles Fachwissen. Probleme mit der Datenleistung und -verwaltung erschwerten die Situation zusätzlich: Abfragen dauerten durchschnittlich 45 Minuten und es kam aufgrund von Fehlkonfigurationen zu Ressourcenknappheit. Um diese Herausforderungen zu bewältigen, suchte NetApp nach einer Alternative zur bestehenden Hadoop-Umgebung und kam zu dem Schluss, dass eine neue, moderne Lösung auf Basis von Dremio die Kosten senken, Speicher und Rechenleistung entkoppeln, die Leistung verbessern, das Datenmanagement vereinfachen, feinkörnige Kontrollen bieten und Disaster-Recovery-Funktionen bereitstellen würde.
Lösung: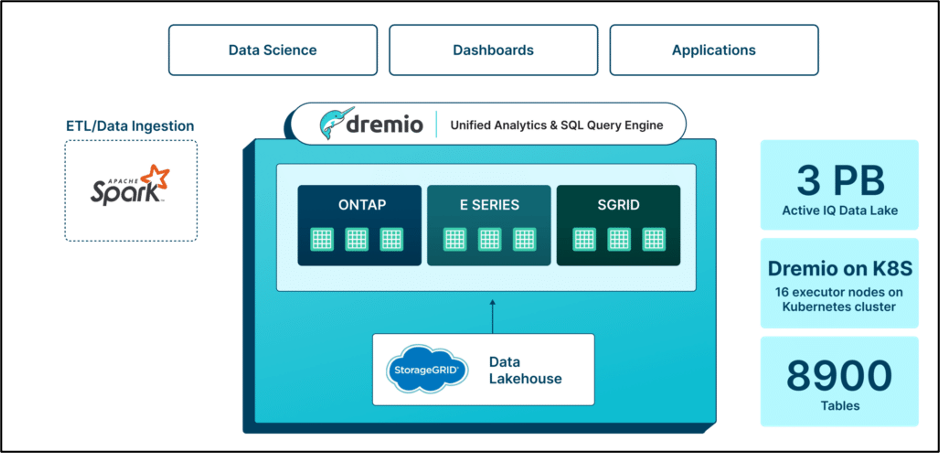 Dremio ermöglichte NetApp die schrittweise Modernisierung seiner Hadoop-basierten Dateninfrastruktur und stellte einen Fahrplan für einheitliche Analysen bereit. Im Gegensatz zu anderen Anbietern, die erhebliche Änderungen an der Datenverarbeitung erforderten, ließ sich Dremio nahtlos in bestehende Pipelines integrieren, was bei der Migration Zeit und Kosten sparte. Durch die Umstellung auf eine vollständig containerisierte Umgebung konnte NetApp den Verwaltungsaufwand reduzieren, die Sicherheit verbessern und die Ausfallsicherheit erhöhen. Durch die Übernahme offener Ökosysteme wie Apache Iceberg und Arrow durch Dremio wurde Zukunftssicherheit, Transparenz und Erweiterbarkeit gewährleistet.
Dremio ermöglichte NetApp die schrittweise Modernisierung seiner Hadoop-basierten Dateninfrastruktur und stellte einen Fahrplan für einheitliche Analysen bereit. Im Gegensatz zu anderen Anbietern, die erhebliche Änderungen an der Datenverarbeitung erforderten, ließ sich Dremio nahtlos in bestehende Pipelines integrieren, was bei der Migration Zeit und Kosten sparte. Durch die Umstellung auf eine vollständig containerisierte Umgebung konnte NetApp den Verwaltungsaufwand reduzieren, die Sicherheit verbessern und die Ausfallsicherheit erhöhen. Durch die Übernahme offener Ökosysteme wie Apache Iceberg und Arrow durch Dremio wurde Zukunftssicherheit, Transparenz und Erweiterbarkeit gewährleistet.
Als Ersatz für die Hadoop/Hive-Infrastruktur bot Dremio über die semantische Ebene Funktionalität für sekundäre Anwendungsfälle. Während die vorhandenen Spark-basierten ETL- und Datenaufnahmemechanismen erhalten blieben, stellte Dremio eine einheitliche Zugriffsebene für eine einfachere Datenermittlung und -erkundung ohne Duplizierung bereit. Dieser Ansatz reduzierte die Datenreplikationsfaktoren erheblich und entkoppelte Speicherung und Datenverarbeitung.
Vorteile: Mit Dremio konnte NetApp durch die Minimierung des Rechenleistungsverbrauchs und des Speicherplatzbedarfs in seinen Datenumgebungen erhebliche Kostensenkungen erzielen. Der neue Active IQ Data Lake besteht aus 8.900 Tabellen mit 3 Petabyte an Daten, verglichen mit der vorherigen Infrastruktur mit über 7 Petabyte. Die Migration zu Dremio umfasste auch den Übergang von 33 Mini-Clustern und 4.000 Kernen zu 16 Executor-Knoten auf Kubernetes-Clustern. Trotz erheblicher Reduzierung der Rechenressourcen konnte NetApp bemerkenswerte Leistungsverbesserungen erzielen. Durch den direkten Datenzugriff über Dremio verringerte sich die Abfragelaufzeit von 45 Minuten auf 2 Minuten, was zu einer um 95 % schnelleren Gewinnung von Erkenntnissen für die vorausschauende Wartung und Optimierung führte. Die Migration führte außerdem zu einer Reduzierung der Rechenkosten um mehr als 60 %, zu mehr als 20-mal schnelleren Abfragen und zu Einsparungen bei den Gesamtbetriebskosten (TCO) um mehr als 30 %.
Anwendungsfall für Kunden im Autoteileverkauf.
Herausforderungen: In diesem globalen Autoteilevertriebsunternehmen konnten sich die für die Finanzplanung und -analyse zuständigen Führungs- und Unternehmensgruppen keinen konsolidierten Überblick über die Verkaufsberichte verschaffen und waren gezwungen, die Verkaufskennzahlenberichte der einzelnen Geschäftsbereiche zu lesen und zu versuchen, diese zu konsolidieren. Dies führte dazu, dass Kunden Entscheidungen auf der Grundlage von Daten trafen, die mindestens einen Tag alt waren. Die Vorlaufzeiten für neue Analyseerkenntnisse betragen in der Regel mehr als vier Wochen. Die Fehlerbehebung bei Datenpipelines würde noch mehr Zeit in Anspruch nehmen und den ohnehin schon langen Zeitplan um weitere drei Tage oder mehr verlängern. Der langsame Berichtsentwicklungsprozess und die langsame Berichtsleistung zwangen die Analysten dazu, ständig auf die Verarbeitung oder das Laden der Daten zu warten, anstatt neue Geschäftseinblicke zu gewinnen und neues Geschäftsverhalten zu fördern. Diese problematischen Umgebungen bestanden aus zahlreichen unterschiedlichen Datenbanken für unterschiedliche Geschäftsbereiche, was zu zahlreichen Datensilos führte. Die langsame und fragmentierte Umgebung erschwerte die Datenverwaltung, da es für Analysten zu viele Möglichkeiten gab, ihre eigene Version der Wahrheit zu entwickeln, anstatt nur auf eine einzige Quelle der Wahrheit zurückgreifen zu müssen. Der Ansatz kostete über 1,9 Millionen US-Dollar an Datenplattform- und Personalkosten. Für die Wartung der alten Plattform und die Bearbeitung von Datenanfragen waren sieben technische Außendiensttechniker (Vollzeitäquivalente) pro Jahr erforderlich. Angesichts der zunehmenden Datenanforderungen konnte das Data-Intelligence-Team die bestehende Umgebung nicht skalieren, um zukünftige Anforderungen zu erfüllen.
Lösung: Große Iceberg-Tabellen kostengünstig im NetApp Object Store speichern und verwalten. Erstellen Sie Datendomänen mithilfe der semantischen Ebene von Dremio, sodass Geschäftsbenutzer Datenprodukte einfach erstellen, suchen und freigeben können.
Vorteile für den Kunden: • Verbesserte und optimierte vorhandene Datenarchitektur und Verkürzung der Zeit bis zum Erlangen von Erkenntnissen von vier Wochen auf nur wenige Stunden • Verkürzung der Fehlerbehebungszeit von drei Tagen auf nur wenige Stunden • Senkung der Kosten für Datenplattform und -verwaltung um mehr als 380.000 US-Dollar • (2) Vollzeitäquivalente an Data-Intelligence-Aufwand pro Jahr eingespart