Anwendungsfall 2: Backup und Disaster Recovery von der Cloud in die lokale Umgebung
 Änderungen vorschlagen
Änderungen vorschlagen
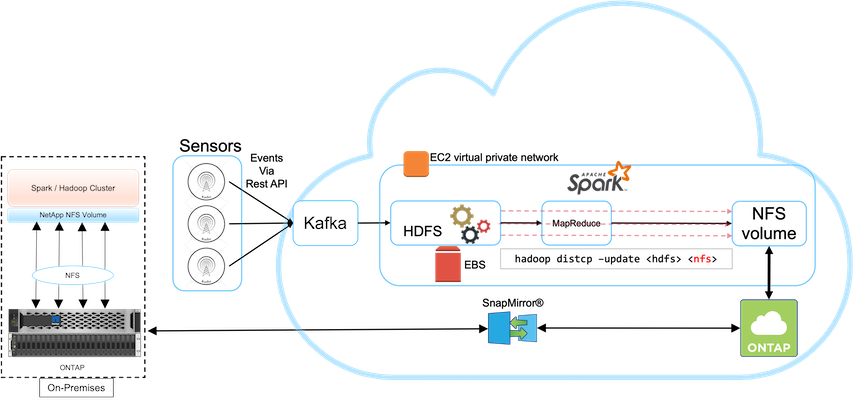
Dieser Anwendungsfall basiert auf einem Rundfunkkunden, der Cloud-basierte Analysedaten in seinem lokalen Rechenzentrum sichern muss, wie in der folgenden Abbildung dargestellt.
Szenario
In diesem Szenario werden die IoT-Sensordaten in die Cloud eingespeist und mithilfe eines Open-Source-Apache-Spark-Clusters innerhalb von AWS analysiert. Voraussetzung ist, dass die verarbeiteten Daten aus der Cloud vor Ort gesichert werden.
Anforderungen und Herausforderungen
Zu den wichtigsten Anforderungen und Herausforderungen für diesen Anwendungsfall gehören:
-
Das Aktivieren des Datenschutzes sollte keine Auswirkungen auf die Leistung des Spark/Hadoop-Produktionsclusters in der Cloud haben.
-
Cloud-Sensordaten müssen effizient und sicher vor Ort verschoben und geschützt werden.
-
Flexibilität bei der Datenübertragung von der Cloud zu lokalen Standorten unter verschiedenen Bedingungen, z. B. bei Bedarf, sofort und bei geringer Cluster-Auslastung.
Lösung
Der Kunde verwendet AWS Elastic Block Store (EBS) für seinen Spark-Cluster-HDFS-Speicher, um Daten von Remote-Sensoren über Kafka zu empfangen und aufzunehmen. Folglich fungiert der HDFS-Speicher als Quelle für die Sicherungsdaten.
Um diese Anforderungen zu erfüllen, wird NetApp ONTAP Cloud in AWS bereitgestellt und eine NFS-Freigabe erstellt, die als Sicherungsziel für den Spark/Hadoop-Cluster fungiert.
Nachdem die NFS-Freigabe erstellt wurde, kopieren Sie die Daten aus dem HDFS-EBS-Speicher in die ONTAP -NFS-Freigabe. Nachdem die Daten in NFS in ONTAP Cloud gespeichert wurden, können die Daten mithilfe der SnapMirror -Technologie bei Bedarf sicher und effizient aus der Cloud in den lokalen Speicher gespiegelt werden.
Dieses Bild zeigt die Backup- und Disaster-Recovery-Lösung von der Cloud zur lokalen Lösung.