

Anwendungsfall 1: Sichern von Hadoop-Daten
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Szenario verfügt der Kunde über ein großes lokales Hadoop-Repository und möchte es für die Notfallwiederherstellung sichern. Die aktuelle Backup-Lösung des Kunden ist jedoch kostspielig und leidet unter einem langen Backup-Fenster von mehr als 24 Stunden.
Anforderungen und Herausforderungen
Zu den wichtigsten Anforderungen und Herausforderungen für diesen Anwendungsfall gehören:
-
Software-Abwärtskompatibilität:
-
Die vorgeschlagene alternative Sicherungslösung sollte mit den aktuell im Produktions-Hadoop-Cluster verwendeten Softwareversionen kompatibel sein.
-
-
Um die vereinbarten SLAs einzuhalten, sollte die vorgeschlagene Alternativlösung sehr niedrige RPOs und RTOs erreichen.
-
Das von der NetApp Backup-Lösung erstellte Backup kann sowohl im lokal im Rechenzentrum erstellten Hadoop-Cluster als auch im Hadoop-Cluster verwendet werden, der am Disaster-Recovery-Standort am Remote-Standort ausgeführt wird.
-
Die vorgeschlagene Lösung muss kosteneffizient sein.
-
Die vorgeschlagene Lösung muss die Leistungseinbußen bei den aktuell laufenden, produktiven Analysejobs während der Sicherungszeiten reduzieren.
Vorhandene Backup-Lösung des Kundenx
Die folgende Abbildung zeigt die ursprüngliche native Hadoop-Backup-Lösung.
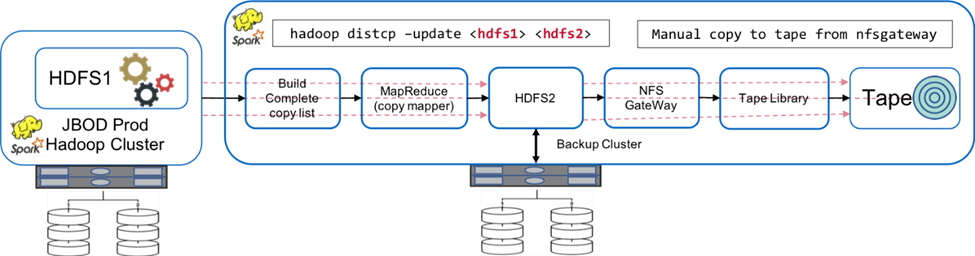
Die Produktionsdaten werden über den Zwischensicherungscluster auf Band gesichert:
-
HDFS1-Daten werden nach HDFS2 kopiert, indem der
hadoop distcp -update <hdfs1> <hdfs2>Befehl. -
Der Backup-Cluster fungiert als NFS-Gateway und die Daten werden manuell über das Linux-System auf Band kopiert.
cpBefehl durch die Bandbibliothek.
Zu den Vorteilen der ursprünglichen nativen Hadoop-Backup-Lösung gehören:
-
Die Lösung basiert auf nativen Hadoop-Befehlen, sodass der Benutzer keine neuen Verfahren erlernen muss.
-
Die Lösung nutzt eine dem Industriestandard entsprechende Architektur und Hardware.
Zu den Nachteilen der ursprünglichen nativen Hadoop-Backup-Lösung gehören:
-
Das lange Backup-Fenster beträgt mehr als 24 Stunden, wodurch die Produktionsdaten gefährdet sind.
-
Erhebliche Leistungseinbußen des Clusters während der Sicherungszeiten.
-
Das Kopieren auf Band ist ein manueller Vorgang.
-
Die Backup-Lösung ist hinsichtlich der erforderlichen Hardware und der für manuelle Prozesse erforderlichen Arbeitsstunden teuer.
Backup-Lösungen
Basierend auf diesen Herausforderungen und Anforderungen und unter Berücksichtigung des vorhandenen Backup-Systems wurden drei mögliche Backup-Lösungen vorgeschlagen. In den folgenden Unterabschnitten werden die drei verschiedenen Sicherungslösungen mit den Bezeichnungen Lösung A bis Lösung C beschrieben.
Lösung A
In Lösung A sendet der Hadoop-Backup-Cluster die sekundären Backups an NetApp NFS-Speichersysteme, wodurch die Bandanforderung entfällt, wie in der folgenden Abbildung dargestellt.
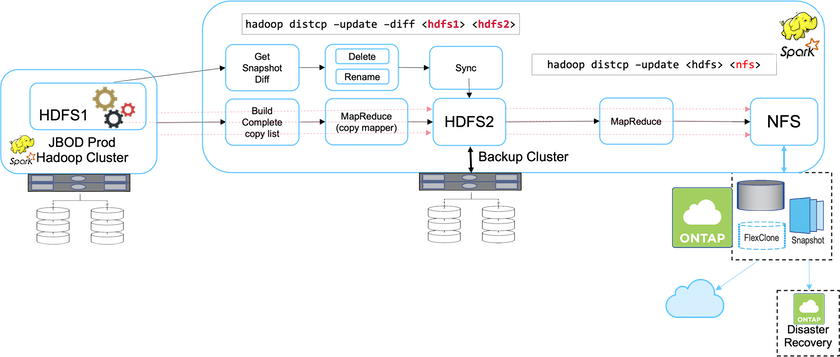
Die detaillierten Aufgaben für Lösung A umfassen:
-
Der Produktions-Hadoop-Cluster verfügt über die Analysedaten des Kunden im HDFS, die geschützt werden müssen.
-
Der Backup-Hadoop-Cluster mit HDFS fungiert als Zwischenspeicherort für die Daten. Nur eine Reihe von Festplatten (JBOD) stellt den Speicher für HDFS sowohl in den Produktions- als auch in den Backup-Hadoop-Clustern bereit.
-
Schützen Sie die Hadoop-Produktionsdaten vom Produktionscluster HDFS zum Backup-Cluster HDFS, indem Sie Folgendes ausführen:
Hadoop distcp –update –diff <hdfs1> <hdfs2>Befehl.

|
Der Hadoop-Snapshot wird verwendet, um die Daten vor der Produktion im Hadoop-Backup-Cluster zu schützen. |
-
Der NetApp ONTAP Speichercontroller stellt ein per NFS exportiertes Volume bereit, das für den Backup-Hadoop-Cluster bereitgestellt wird.
-
Durch Ausführen des
Hadoop distcpDurch den Einsatz von MapReduce und mehreren Mappern werden die Analysedaten vom Backup-Hadoop-Cluster auf NFS geschützt.Nachdem die Daten in NFS auf dem NetApp -Speichersystem gespeichert wurden, werden die Technologien NetApp Snapshot, SnapRestore und FlexClone verwendet, um die Hadoop-Daten nach Bedarf zu sichern, wiederherzustellen und zu duplizieren.
|
|
Hadoop-Daten können mithilfe der SnapMirror -Technologie sowohl in der Cloud als auch an Disaster-Recovery-Standorten geschützt werden. |
Zu den Vorteilen von Lösung A gehören:
-
Hadoop-Produktionsdaten werden vor dem Backup-Cluster geschützt.
-
HDFS-Daten werden durch NFS geschützt und ermöglichen so den Schutz von Cloud- und Notfallwiederherstellungsstandorten.
-
Verbessert die Leistung durch Auslagerung von Sicherungsvorgängen auf den Sicherungscluster.
-
Eliminiert manuelle Bandvorgänge
-
Ermöglicht Unternehmensverwaltungsfunktionen über NetApp -Tools.
-
Erfordert nur minimale Änderungen an der vorhandenen Umgebung.
-
Ist eine kostengünstige Lösung.
Der Nachteil dieser Lösung besteht darin, dass sie einen Backup-Cluster und zusätzliche Mapper zur Leistungsverbesserung erfordert.
Der Kunde hat vor Kurzem Lösung A aufgrund ihrer Einfachheit, Kosten und Gesamtleistung implementiert.
Bei dieser Lösung können SAN-Festplatten von ONTAP anstelle von JBOD verwendet werden. Diese Option verlagert die Speicherlast des Backup-Clusters auf ONTAP. Der Nachteil besteht jedoch darin, dass SAN-Fabric-Switches erforderlich sind.
Lösung B
Lösung B fügt dem Produktions-Hadoop-Cluster ein NFS-Volume hinzu, wodurch der Backup-Hadoop-Cluster überflüssig wird, wie in der folgenden Abbildung gezeigt.
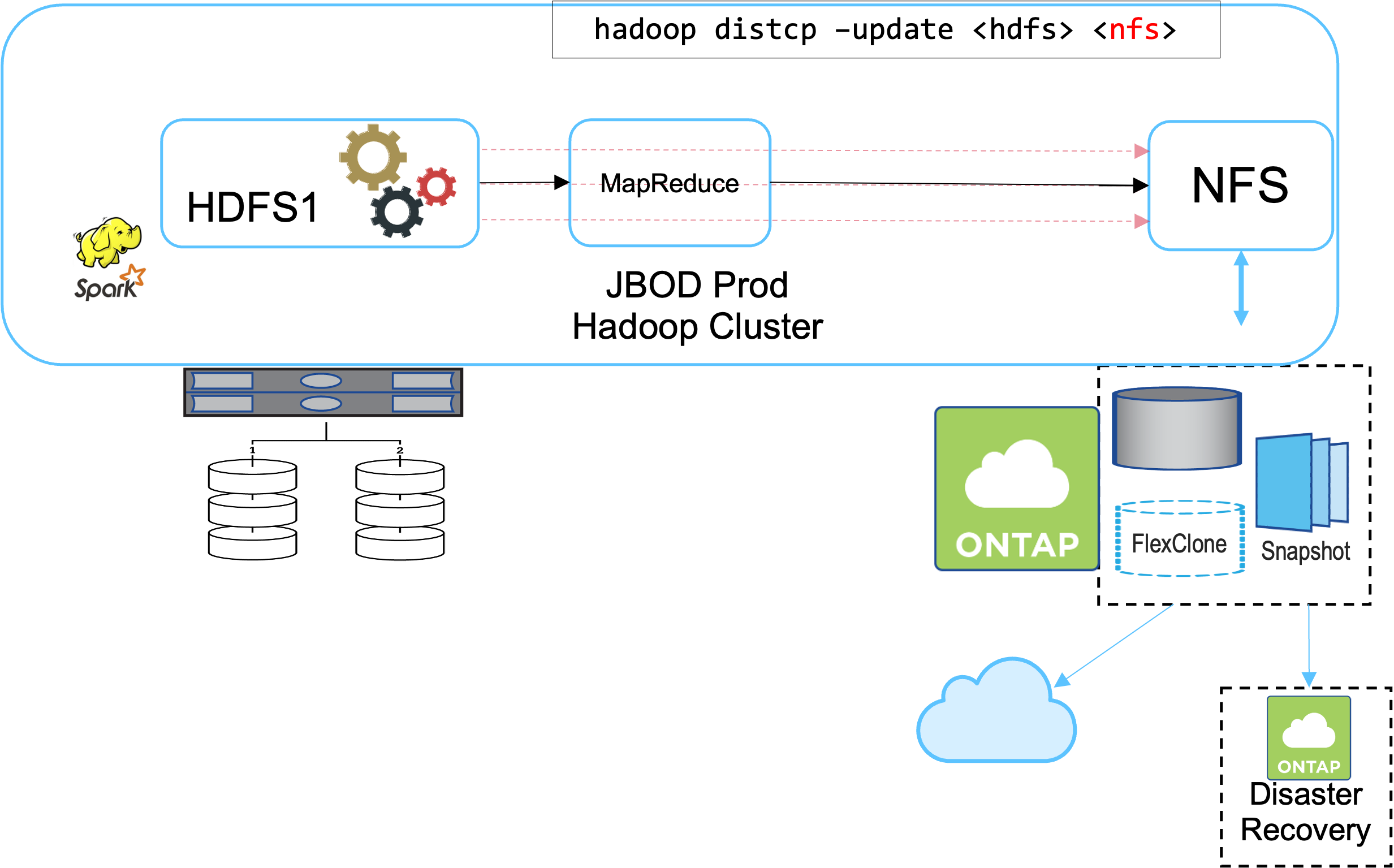
Die detaillierten Aufgaben für Lösung B umfassen:
-
Der NetApp ONTAP Speichercontroller stellt den NFS-Export zum Produktions-Hadoop-Cluster bereit.
Der Hadoop-Native
hadoop distcpDer Befehl schützt die Hadoop-Daten vom Produktionscluster HDFS auf NFS. -
Nachdem die Daten in NFS auf dem NetApp -Speichersystem gespeichert wurden, werden die Technologien Snapshot, SnapRestore und FlexClone verwendet, um die Hadoop-Daten nach Bedarf zu sichern, wiederherzustellen und zu duplizieren.
Zu den Vorteilen der Lösung B gehören:
-
Der Produktionscluster wird für die Backup-Lösung leicht modifiziert, was die Implementierung vereinfacht und zusätzliche Infrastrukturkosten reduziert.
-
Ein Backup-Cluster für den Backup-Vorgang ist nicht erforderlich.
-
HDFS-Produktionsdaten werden bei der Konvertierung in NFS-Daten geschützt.
-
Die Lösung ermöglicht Unternehmensverwaltungsfunktionen über NetApp -Tools.
Der Nachteil dieser Lösung besteht darin, dass sie im Produktionscluster implementiert wird, was zu zusätzlichen Administratoraufgaben im Produktionscluster führen kann.
Lösung C
In Lösung C werden die NetApp SAN-Volumes direkt für den Hadoop-Produktionscluster zur HDFS-Speicherung bereitgestellt, wie in der folgenden Abbildung dargestellt.
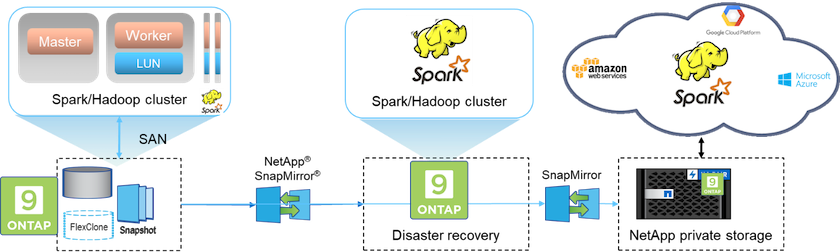
Die detaillierten Schritte für Lösung C umfassen:
-
NetApp ONTAP SAN-Speicher wird im Produktions-Hadoop-Cluster für die HDFS-Datenspeicherung bereitgestellt.
-
Zum Sichern der HDFS-Daten aus dem Produktions-Hadoop-Cluster werden die Technologien NetApp Snapshot und SnapMirror verwendet.
-
Während des Snapshot-Kopiersicherungsprozesses kommt es zu keinen Leistungseinbußen bei der Produktion des Hadoop/Spark-Clusters, da die Sicherung auf der Speicherebene erfolgt.
|
|
Die Snapshot-Technologie ermöglicht Backups, die unabhängig von der Datengröße in Sekundenschnelle abgeschlossen sind. |
Zu den Vorteilen der Lösung C gehören:
-
Mithilfe der Snapshot-Technologie können platzsparende Backups erstellt werden.
-
Ermöglicht Unternehmensverwaltungsfunktionen über NetApp -Tools.