Anwendungsfall 3: DevTest für vorhandene Hadoop-Daten aktivieren
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Anwendungsfall besteht die Anforderung des Kunden darin, schnell und effizient neue Hadoop/Spark-Cluster auf der Grundlage eines vorhandenen Hadoop-Clusters zu erstellen, der eine große Menge an Analysedaten für DevTest- und Berichtszwecke im selben Rechenzentrum sowie an Remote-Standorten enthält.
Szenario
In diesem Szenario werden mehrere Spark/Hadoop-Cluster aus einer großen Hadoop-Data-Lake-Implementierung vor Ort sowie an Disaster-Recovery-Standorten erstellt.
Anforderungen und Herausforderungen
Zu den wichtigsten Anforderungen und Herausforderungen für diesen Anwendungsfall gehören:
-
Erstellen Sie mehrere Hadoop-Cluster für DevTest, Qualitätssicherung oder andere Zwecke, die Zugriff auf dieselben Produktionsdaten erfordern. Die Herausforderung besteht darin, einen sehr großen Hadoop-Cluster mehrere Male gleichzeitig und auf sehr platzsparende Weise zu klonen.
-
Synchronisieren Sie die Hadoop-Daten mit DevTest- und Berichtsteams, um die betriebliche Effizienz zu steigern.
-
Verteilen Sie die Hadoop-Daten, indem Sie dieselben Anmeldeinformationen in der Produktion und in neuen Clustern verwenden.
-
Verwenden Sie geplante Richtlinien, um QA-Cluster effizient zu erstellen, ohne den Produktionscluster zu beeinträchtigen.
Lösung
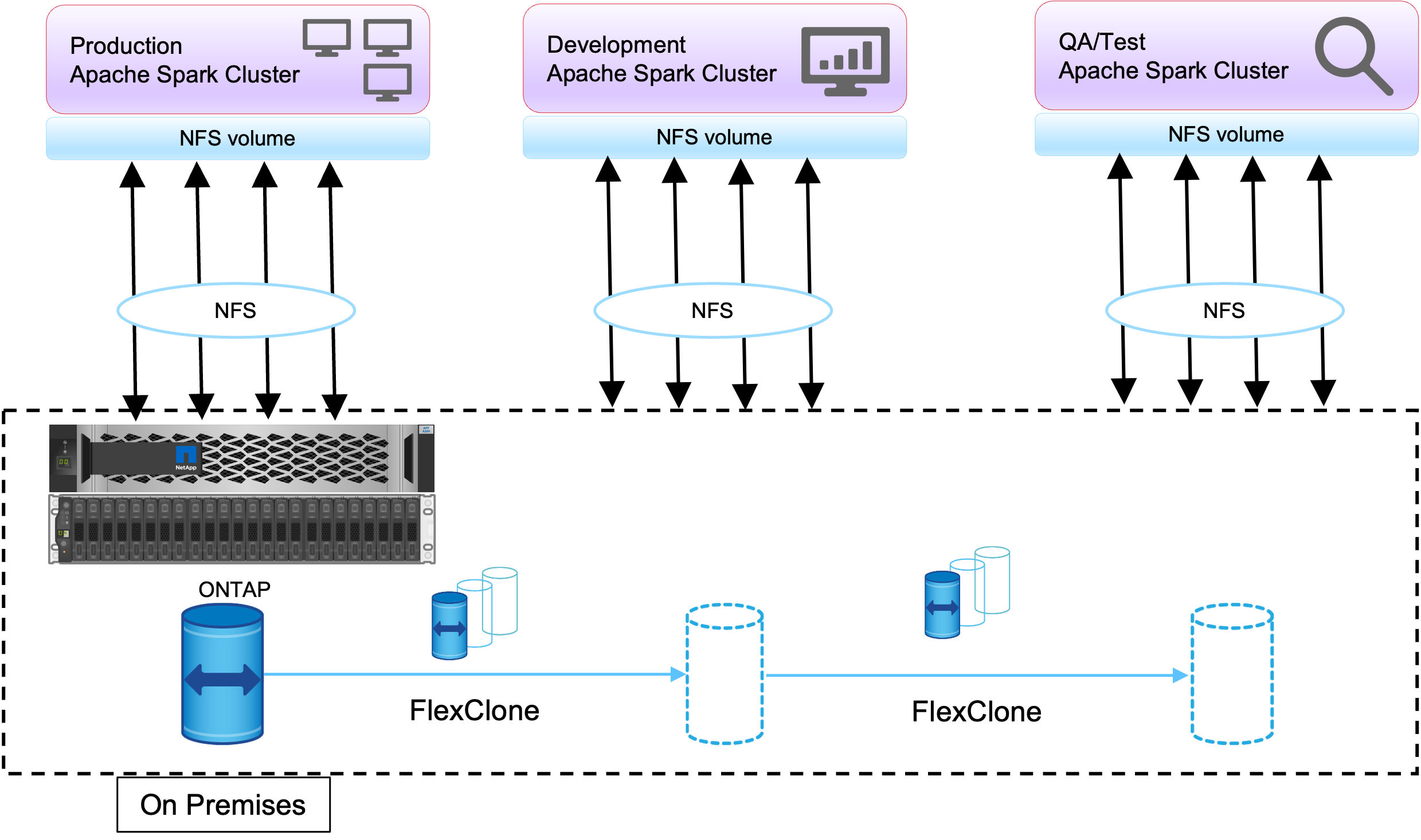
Um die gerade beschriebenen Anforderungen zu erfüllen, wird die FlexClone -Technologie verwendet. Die FlexClone -Technologie ist die Lese-/Schreibkopie einer Snapshot-Kopie. Es liest die Daten aus den übergeordneten Snapshot-Kopiedaten und verbraucht nur zusätzlichen Speicherplatz für neue/geänderte Blöcke. Es ist schnell und platzsparend.
Zunächst wurde mithilfe einer NetApp Konsistenzgruppe eine Snapshot-Kopie des vorhandenen Clusters erstellt.
Snapshot-Kopien im NetApp System Manager oder in der Storage-Admin-Eingabeaufforderung. Bei den Snapshot-Kopien der Konsistenzgruppe handelt es sich um anwendungskonsistente Snapshot-Kopien der Gruppe, und das FlexClone -Volume wird basierend auf Snapshot-Kopien der Konsistenzgruppe erstellt. Es ist erwähnenswert, dass ein FlexClone -Volume die NFS-Exportrichtlinie des übergeordneten Volumes erbt. Nachdem die Snapshot-Kopie erstellt wurde, muss ein neuer Hadoop-Cluster für DevTest- und Berichtszwecke installiert werden, wie in der folgenden Abbildung dargestellt. Das geklonte NFS-Volume aus dem neuen Hadoop-Cluster greift auf die NFS-Daten zu.
Dieses Bild zeigt den Hadoop-Cluster für DevTest.