

Technologieübersicht
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt wird die in dieser Lösung verwendete Technologie beschrieben.
NetApp ONTAP Speichercontroller
NetApp ONTAP ist ein leistungsstarkes Speicherbetriebssystem der Enterprise-Klasse.
NetApp ONTAP 9.8 führt Unterstützung für Amazon Simple Storage Service (S3)-APIs ein. ONTAP unterstützt eine Teilmenge der S3-API-Aktionen von Amazon Web Services (AWS) und ermöglicht die Darstellung von Daten als Objekte in ONTAP-basierten Systemen bei Cloud-Anbietern (AWS, Azure und GCP) und vor Ort.
Die NetApp StorageGRID -Software ist die Flaggschiff-Lösung von NetApp für Objektspeicher. ONTAP ergänzt StorageGRID , indem es einen Aufnahme- und Vorverarbeitungspunkt am Rand bereitstellt, das von NetApp betriebene Datengewebe für Objektdaten erweitert und den Wert des NetApp -Produktportfolios steigert.
Der Zugriff auf einen S3-Bucket wird über autorisierte Benutzer- und Clientanwendungen bereitgestellt. Das folgende Diagramm zeigt die Anwendung beim Zugriff auf einen S3-Bucket.
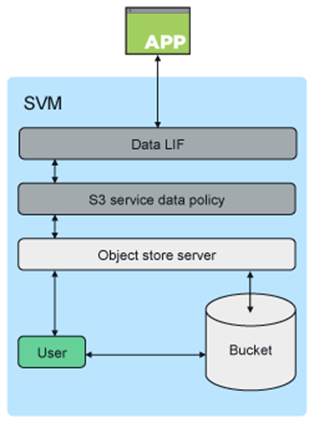
Primäre Anwendungsfälle
Der Hauptzweck der Unterstützung von S3-APIs besteht darin, Objektzugriff auf ONTAP bereitzustellen. Die einheitliche Speicherarchitektur von ONTAP unterstützt jetzt Dateien (NFS und SMB), Blöcke (FC und iSCSI) und Objekte (S3).
Native S3-Anwendungen
Immer mehr Anwendungen können die ONTAP Unterstützung für den Objektzugriff mit S3 nutzen. Obwohl sie für Archivierungs-Workloads mit hoher Kapazität gut geeignet sind, wächst der Bedarf an hoher Leistung in nativen S3-Anwendungen schnell und umfasst:
-
Analyse
-
Künstliche Intelligenz
-
Edge-to-Core-Aufnahme
-
Maschinelles Lernen
Kunden können jetzt vertraute Verwaltungstools wie ONTAP System Manager verwenden, um schnell leistungsstarken Objektspeicher für Entwicklung und Betrieb in ONTAP bereitzustellen und dabei die Effizienz und Sicherheit des ONTAP Speichers zu nutzen.
FabricPool -Endpunkte
Ab ONTAP 9.8 unterstützt FabricPool die Tiering-Funktion für Buckets in ONTAP und ermöglicht so ONTAP-zu- ONTAP -Tiering. Dies ist eine hervorragende Option für Kunden, die ihre vorhandene FAS Infrastruktur als Objektspeicher-Endpunkt umfunktionieren möchten.
FabricPool unterstützt das Tiering zu ONTAP auf zwei Arten:
-
Lokale Cluster-Tiering. Inaktive Daten werden mithilfe von Cluster-LIFs in einen Bucket auf dem lokalen Cluster verschoben.
-
Remote-Cluster-Tiering. Inaktive Daten werden in einem Bucket auf einem Remote-Cluster abgelegt, und zwar auf ähnliche Weise wie bei einer herkömmlichen FabricPool Cloud-Ebene, wobei IC-LIFs auf dem FabricPool Client und Daten-LIFs auf dem ONTAP Objektspeicher verwendet werden.
ONTAP S3 ist geeignet, wenn Sie S3-Funktionen auf vorhandenen Clustern ohne zusätzliche Hardware und Verwaltung wünschen. Für Bereitstellungen mit mehr als 300 TB ist die NetApp StorageGRID -Software weiterhin die führende NetApp -Lösung für Objektspeicher. Bei Verwendung von ONTAP oder StorageGRID als Cloud-Ebene ist keine FabricPool -Lizenz erforderlich.
NetApp ONTAP für Confluent Tiered Storage
In jedem Rechenzentrum müssen geschäftskritische Anwendungen ausgeführt werden und wichtige Daten verfügbar und sicher sein. Das neue NetApp AFF A900 -System basiert auf der Software ONTAP Enterprise Edition und verfügt über ein hoch belastbares Design. Unser neues blitzschnelles NVMe-Speichersystem verhindert Störungen unternehmenskritischer Vorgänge, minimiert die Leistungsoptimierung und schützt Ihre Daten vor Ransomware-Angriffen.
Von der ersten Bereitstellung bis zur Skalierung Ihres Confluent-Clusters erfordert Ihre Umgebung eine schnelle Anpassung an Änderungen, die Ihre geschäftskritischen Anwendungen nicht beeinträchtigen. ONTAP Enterprise-Datenmanagement, Quality of Service (QoS) und Leistung ermöglichen Ihnen die Planung und Anpassung an Ihre Umgebung.
Die gemeinsame Verwendung von NetApp ONTAP und Confluent Tiered Storage vereinfacht die Verwaltung von Apache Kafka-Clustern, indem ONTAP als Scale-Out-Speicherziel genutzt wird und eine unabhängige Skalierung der Rechen- und Speicherressourcen für Confluent ermöglicht wird.
Ein ONTAP S3-Server basiert auf den ausgereiften Scale-Out-Speicherfunktionen von ONTAP. Die Skalierung Ihres ONTAP Clusters kann nahtlos erfolgen, indem Sie Ihre S3-Buckets erweitern, um neu hinzugefügte Knoten zum ONTAP Cluster zu verwenden.
Einfache Verwaltung mit ONTAP System Manager
ONTAP System Manager ist eine browserbasierte grafische Benutzeroberfläche, mit der Sie Ihren ONTAP -Speichercontroller an weltweit verteilten Standorten in einer einzigen Konsole konfigurieren, verwalten und überwachen können.
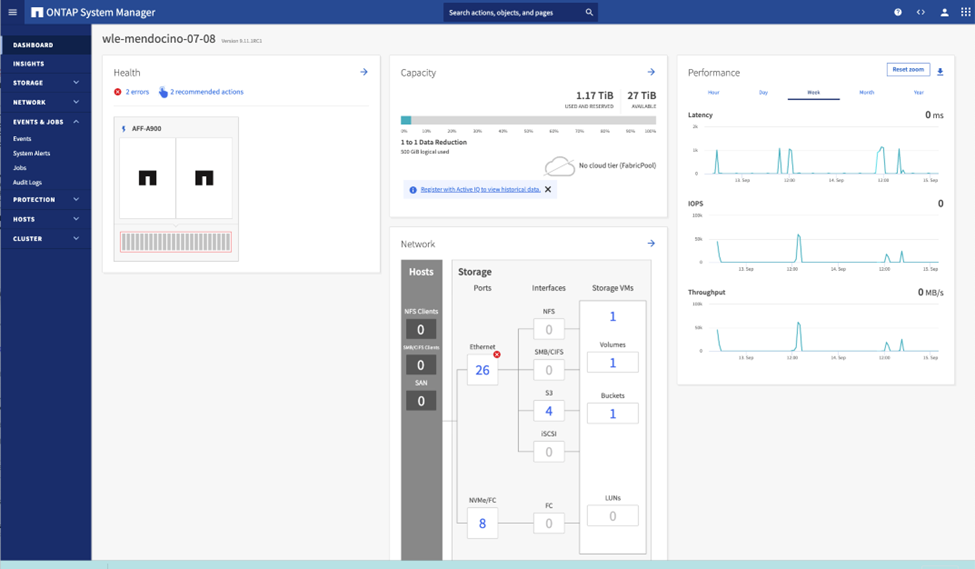
Sie können ONTAP S3 mit System Manager und der ONTAP CLI konfigurieren und verwalten. Wenn Sie S3 aktivieren und Buckets mit System Manager erstellen, bietet ONTAP Best-Practice-Standards für eine vereinfachte Konfiguration. Wenn Sie den S3-Server und die Buckets über die CLI konfigurieren, können Sie sie bei Bedarf weiterhin mit System Manager verwalten und umgekehrt.
Wenn Sie mit System Manager einen S3-Bucket erstellen, konfiguriert ONTAP ein standardmäßiges Leistungsservicelevel, das dem höchsten auf Ihrem System verfügbaren entspricht. Bei einem AFF -System wäre die Standardeinstellung beispielsweise „Extrem“. Leistungsdienstebenen sind vordefinierte adaptive QoS-Richtliniengruppen. Anstelle einer der Standard-Serviceebenen können Sie eine benutzerdefinierte QoS-Richtliniengruppe oder keine Richtliniengruppe angeben.
Zu den vordefinierten adaptiven QoS-Richtliniengruppen gehören die folgenden:
-
Extrem. Wird für Anwendungen verwendet, die die geringste Latenz und höchste Leistung erfordern.
-
Leistung. Wird für Anwendungen mit mäßigem Leistungsbedarf und geringer Latenz verwendet.
-
Wert. Wird für Anwendungen verwendet, bei denen Durchsatz und Kapazität wichtiger sind als Latenz.
-
Brauch. Geben Sie eine benutzerdefinierte QoS-Richtlinie oder keine QoS-Richtlinie an.
Wenn Sie Für Tiering verwenden auswählen, werden keine Leistungsservicelevel ausgewählt und das System versucht, kostengünstige Medien mit optimaler Leistung für die gestaffelten Daten auszuwählen.
ONTAP versucht, diesen Bucket auf lokalen Ebenen bereitzustellen, die über die am besten geeigneten Festplatten verfügen und so das gewählte Servicelevel erfüllen. Wenn Sie jedoch angeben müssen, welche Datenträger in den Bucket aufgenommen werden sollen, sollten Sie den S3-Objektspeicher über die CLI konfigurieren, indem Sie die lokalen Ebenen (Aggregat) angeben. Wenn Sie den S3-Server über die CLI konfigurieren, können Sie ihn bei Bedarf weiterhin mit System Manager verwalten.
Wenn Sie angeben möchten, welche Aggregate für Buckets verwendet werden, können Sie dies nur über die CLI tun.
Zusammenfließend
Confluent Platform ist eine umfassende Daten-Streaming-Plattform, die Ihnen den einfachen Zugriff auf Daten sowie deren Speicherung und Verwaltung als kontinuierliche Echtzeit-Streams ermöglicht. Confluent wurde von den ursprünglichen Entwicklern von Apache Kafka entwickelt und erweitert die Vorteile von Kafka um Funktionen auf Unternehmensniveau, während es gleichzeitig den Aufwand für die Verwaltung oder Überwachung von Kafka verringert. Heute nutzen über 80 % der Fortune 100-Unternehmen Datenstreaming-Technologie und die meisten davon verwenden Confluent.
Warum Confluent?
Durch die Integration historischer und Echtzeitdaten in eine einzige, zentrale Quelle der Wahrheit erleichtert Confluent den Aufbau einer völlig neuen Kategorie moderner, ereignisgesteuerter Anwendungen, den Aufbau einer universellen Datenpipeline und die Erschließung leistungsstarker neuer Anwendungsfälle mit voller Skalierbarkeit, Leistung und Zuverlässigkeit.
Wofür wird Confluent verwendet?
Mit der Confluent Platform können Sie sich darauf konzentrieren, wie Sie aus Ihren Daten geschäftlichen Nutzen ziehen, anstatt sich um die zugrunde liegenden Mechanismen zu kümmern, beispielsweise darum, wie Daten zwischen unterschiedlichen Systemen transportiert oder integriert werden. Insbesondere vereinfacht die Confluent Platform die Verbindung von Datenquellen mit Kafka, die Erstellung von Streaming-Anwendungen sowie die Sicherung, Überwachung und Verwaltung Ihrer Kafka-Infrastruktur. Heute wird die Confluent Platform für eine breite Palette von Anwendungsfällen in zahlreichen Branchen eingesetzt, von Finanzdienstleistungen, Omnichannel-Einzelhandel und autonomen Autos bis hin zu Betrugserkennung, Microservices und IoT.
Die folgende Abbildung zeigt die Komponenten der Confluent-Plattform.
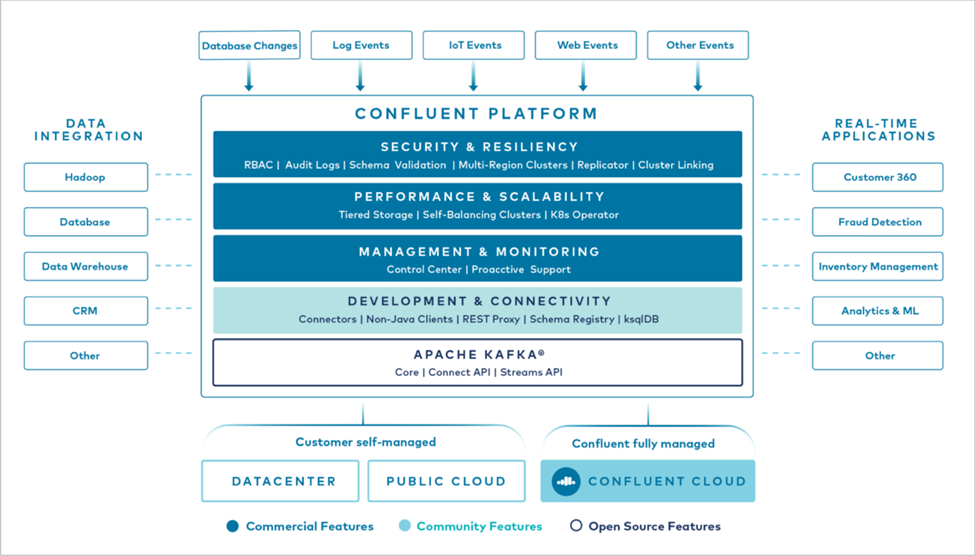
Übersicht über die Confluent Event-Streaming-Technologie
Der Kern der Confluent Platform ist "Kafka" , die beliebteste Open-Source-Plattform für verteiltes Streaming. Zu den wichtigsten Funktionen von Kafka gehören die folgenden:
-
Veröffentlichen und abonnieren Sie Datensatz-Streams.
-
Speichern Sie Datensatzströme fehlertolerant.
-
Verarbeiten Sie Datensatzströme.
Die Confluent Platform umfasst standardmäßig auch Schema Registry, REST Proxy, insgesamt über 100 vorgefertigte Kafka-Konnektoren und ksqlDB.
Übersicht über die Enterprise-Funktionen der Confluent-Plattform
-
Confluent-Kontrollzentrum. Ein UI-basiertes System zur Verwaltung und Überwachung von Kafka. Es ermöglicht Ihnen die einfache Verwaltung von Kafka Connect und das Erstellen, Bearbeiten und Verwalten von Verbindungen zu anderen Systemen.
-
Confluent für Kubernetes. Confluent für Kubernetes ist ein Kubernetes-Operator. Kubernetes-Operatoren erweitern die Orchestrierungsfunktionen von Kubernetes, indem sie die einzigartigen Funktionen und Anforderungen für eine bestimmte Plattformanwendung bereitstellen. Für die Confluent Platform bedeutet dies eine erhebliche Vereinfachung des Bereitstellungsprozesses von Kafka auf Kubernetes und die Automatisierung typischer Aufgaben im Lebenszyklus der Infrastruktur.
-
Kafka Connect-Konnektoren. Konnektoren verwenden die Kafka Connect-API, um Kafka mit anderen Systemen wie Datenbanken, Schlüssel-Wert-Speichern, Suchindizes und Dateisystemen zu verbinden. Confluent Hub verfügt über herunterladbare Konnektoren für die gängigsten Datenquellen und -senken, einschließlich vollständig getesteter und unterstützter Versionen dieser Konnektoren mit Confluent Platform. Weitere Details finden Sie "hier," .
-
Selbstausgleichende Cluster. Bietet automatisierten Lastausgleich, Fehlererkennung und Selbstheilung. Es bietet außerdem Unterstützung für das Hinzufügen oder Außerbetriebnehmen von Brokern nach Bedarf, ohne dass eine manuelle Anpassung erforderlich ist.
-
Konfluente Clusterverknüpfung. Verbindet Cluster direkt miteinander und spiegelt Themen von einem Cluster zum anderen über eine Linkbrücke. Die Clusterverknüpfung vereinfacht die Einrichtung von Multi-Datacenter-, Multi-Cluster- und Hybrid-Cloud-Bereitstellungen.
-
Confluent automatischer Datenausgleich. Überwacht Ihren Cluster hinsichtlich der Anzahl der Broker, der Größe der Partitionen, der Anzahl der Partitionen und der Anzahl der Leader innerhalb des Clusters. Sie können Daten verschieben, um eine gleichmäßige Arbeitslast in Ihrem Cluster zu erreichen, und gleichzeitig den Datenverkehr drosseln, um die Auswirkungen auf die Produktionsarbeitslasten während der Neuverteilung zu minimieren.
-
Konfluenter Replikator. Macht es einfacher als je zuvor, mehrere Kafka-Cluster in mehreren Rechenzentren zu verwalten.
-
Stufenspeicher. Bietet Optionen zum Speichern großer Mengen von Kafka-Daten bei Ihrem bevorzugten Cloud-Anbieter und reduziert so den Betriebsaufwand und die Kosten. Mit Tiered Storage können Sie Daten auf kostengünstigem Objektspeicher aufbewahren und Broker nur dann skalieren, wenn Sie mehr Rechenressourcen benötigen.
-
Confluent JMS-Client. Confluent Platform enthält einen JMS-kompatiblen Client für Kafka. Dieser Kafka-Client implementiert die JMS 1.1-Standard-API und verwendet Kafka-Broker als Backend. Dies ist nützlich, wenn Sie über ältere Anwendungen verfügen, die JMS verwenden, und Sie den vorhandenen JMS-Nachrichtenbroker durch Kafka ersetzen möchten.
-
Confluent MQTT-Proxy. Bietet eine Möglichkeit, Daten von MQTT-Geräten und -Gateways direkt an Kafka zu veröffentlichen, ohne dass ein MQTT-Broker dazwischengeschaltet werden muss.
-
Confluent-Sicherheits-Plugins. Confluent-Sicherheits-Plugins werden verwendet, um verschiedenen Tools und Produkten der Confluent-Plattform Sicherheitsfunktionen hinzuzufügen. Derzeit ist ein Plug-In für den Confluent REST-Proxy verfügbar, das bei der Authentifizierung eingehender Anfragen hilft und den authentifizierten Auftraggeber an Anfragen an Kafka weitergibt. Dadurch können Confluent REST-Proxy-Clients die Multitenant-Sicherheitsfunktionen des Kafka-Brokers nutzen.