

Splunk-Architektur
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt wird die Splunk-Architektur beschrieben, einschließlich wichtiger Definitionen, verteilter Splunk-Bereitstellungen, Splunk SmartStore, Datenfluss, Hardware- und Softwareanforderungen, Anforderungen für Einzel- und Multisite-Umgebungen usw.
Wichtige Definitionen
In den nächsten beiden Tabellen sind die Splunk- und NetApp Komponenten aufgeführt, die in der verteilten Splunk-Bereitstellung verwendet werden.
Diese Tabelle listet die Splunk-Hardwarekomponenten für die verteilte Splunk Enterprise-Konfiguration auf.
| Splunk-Komponente | Aufgabe |
|---|---|
Indexer |
Repository für Splunk Enterprise-Daten |
Universal-Spediteur |
Verantwortlich für die Aufnahme und Weiterleitung von Daten an die Indexer |
Suchkopf |
Das Benutzer-Frontend, das zum Suchen von Daten in Indexern verwendet wird |
Cluster-Master |
Verwaltet die Splunk-Installation von Indexern und Suchköpfen |
Überwachungskonsole |
Zentralisiertes Überwachungstool für die gesamte Bereitstellung |
Lizenzmaster |
License Master kümmert sich um die Splunk Enterprise-Lizenzierung |
Bereitstellungsserver |
Aktualisiert Konfigurationen und verteilt Apps an die Verarbeitungskomponente |
Speicherkomponente |
Aufgabe |
NetApp AFF |
Zur Verwaltung von Hot-Tier-Daten wird ein vollständiger Flash-Speicher verwendet. Auch als lokaler Speicher bekannt. |
NetApp StorageGRID |
S3-Objektspeicher zur Verwaltung von Warm-Tier-Daten. Wird von SmartStore verwendet, um Daten zwischen der heißen und warmen Ebene zu verschieben. Auch als Remote-Speicher bekannt. |
Diese Tabelle listet die Komponenten der Splunk-Speicherarchitektur auf.
| Splunk-Komponente | Aufgabe | Verantwortliche Komponente |
|---|---|---|
SmartStore |
Bietet Indexern die Möglichkeit, Daten vom lokalen Speicher in den Objektspeicher zu verschieben. |
Splunk |
Heiß |
Der Landeplatz, an dem Universal Forwarder neu geschriebene Daten platzieren. Der Speicher ist beschreibbar und die Daten sind durchsuchbar. Diese Datenebene besteht normalerweise aus SSDs oder schnellen HDDs. |
ONTAP |
Cache-Manager |
Verwaltet den lokalen Cache der indizierten Daten, ruft bei einer Suche warme Daten aus dem Remote-Speicher ab und entfernt am wenigsten häufig verwendete Daten aus dem Cache. |
SmartStore |
Warm |
Die Daten werden logisch in den Bucket gerollt und zunächst vom Hot-Tier in den Warm-Tier umbenannt. Die Daten innerhalb dieser Ebene sind geschützt und können, wie die Hot-Tier-Ebene, aus SSDs oder HDDs mit größerer Kapazität bestehen. Sowohl inkrementelle als auch vollständige Backups werden mithilfe gängiger Datenschutzlösungen unterstützt. |
StorageGRID |
Verteilte Splunk-Bereitstellungen
Um größere Umgebungen zu unterstützen, in denen die Daten von vielen Maschinen stammen, müssen Sie große Datenmengen verarbeiten. Wenn viele Benutzer die Daten durchsuchen müssen, können Sie die Bereitstellung skalieren, indem Sie Splunk Enterprise-Instanzen auf mehrere Maschinen verteilen. Dies wird als verteilte Bereitstellung bezeichnet.
In einer typischen verteilten Bereitstellung führt jede Splunk Enterprise-Instanz eine spezielle Aufgabe aus und befindet sich auf einer von drei Verarbeitungsebenen, die den Hauptverarbeitungsfunktionen entsprechen.
In der folgenden Tabelle sind die Verarbeitungsebenen von Splunk Enterprise aufgeführt.
| Stufe | Komponente | Beschreibung |
|---|---|---|
Dateneingabe |
Spediteur |
Ein Forwarder verbraucht Daten und leitet die Daten dann an eine Gruppe von Indexern weiter. |
Indizierung |
Indexer |
Ein Indexer indiziert eingehende Daten, die er normalerweise von einer Gruppe von Weiterleitungen erhält. Der Indexer wandelt die Daten in Ereignisse um und speichert die Ereignisse in einem Index. Der Indexer durchsucht die indexierten Daten auch als Antwort auf Suchanfragen eines Suchkopfs. |
Suchverwaltung |
Suchkopf |
Ein Suchkopf dient als zentrale Ressource für die Suche. Die Suchköpfe in einem Cluster sind austauschbar und haben von jedem Mitglied des Suchkopfclusters aus Zugriff auf dieselben Suchvorgänge, Dashboards, Wissensobjekte usw. |
In der folgenden Tabelle sind die wichtigen Komponenten aufgeführt, die in einer verteilten Splunk Enterprise-Umgebung verwendet werden.
| Komponente | Beschreibung | Verantwortung |
|---|---|---|
Index-Cluster-Master |
Koordiniert Aktivitäten und Updates eines Indexer-Clusters |
Indexverwaltung |
Indexcluster |
Gruppe von Splunk Enterprise-Indexern, die so konfiguriert sind, dass sie Daten untereinander replizieren |
Indizierung |
Suchkopf-Deployer |
Verarbeitet die Bereitstellung und Aktualisierung des Cluster-Masters |
Suchkopfverwaltung |
Suchkopfcluster |
Gruppe von Suchköpfen, die als zentrale Ressource für die Suche dient |
Suchverwaltung |
Lastenausgleich |
Wird von Clusterkomponenten verwendet, um die steigende Nachfrage von Suchköpfen, Indexern und S3-Zielen zu bewältigen und die Last auf die Clusterkomponenten zu verteilen. |
Lastmanagement für Clusterkomponenten |
Entdecken Sie die folgenden Vorteile der verteilten Bereitstellungen von Splunk Enterprise:
-
Zugriff auf vielfältige oder verteilte Datenquellen
-
Bereitstellung von Funktionen zur Bewältigung der Datenanforderungen von Unternehmen jeder Größe und Komplexität
-
Erreichen Sie hohe Verfügbarkeit und stellen Sie die Notfallwiederherstellung mit Datenreplikation und Multisite-Bereitstellung sicher
Splunk SmartStore
SmartStore ist eine Indexerfunktion, die es Remote-Objektspeichern wie Amazon S3 ermöglicht, indizierte Daten zu speichern. Wenn das Datenvolumen einer Bereitstellung zunimmt, übersteigt der Bedarf an Speicher in der Regel den Bedarf an Rechenressourcen. Mit SmartStore können Sie Ihren Indexerspeicher und Ihre Rechenressourcen kostengünstig verwalten, indem Sie diese Ressourcen separat skalieren.
SmartStore führt eine Remote-Speicherebene und einen Cache-Manager ein. Diese Funktionen ermöglichen die Speicherung von Daten entweder lokal auf Indexern oder auf der Remote-Speicherebene. Der Cache-Manager verwaltet die Datenbewegung zwischen dem Indexer und der Remote-Speicherebene, die auf dem Indexer konfiguriert ist.
Mit SmartStore können Sie den Speicherbedarf des Indexers auf ein Minimum reduzieren und E/A-optimierte Rechenressourcen auswählen. Die meisten Daten befinden sich auf dem Remote-Speicher. Der Indexer verwaltet einen lokalen Cache, der eine minimale Datenmenge enthält: Hot Buckets, Kopien von Warm Buckets, die an aktiven oder kürzlich durchgeführten Suchvorgängen beteiligt sind, und Bucket-Metadaten.
Splunk SmartStore-Datenfluss
Wenn eingehende Daten aus verschiedenen Quellen die Indexer erreichen, werden die Daten indiziert und lokal in einem Hot Bucket gespeichert. Der Indexer repliziert außerdem die Hot-Bucket-Daten auf Zielindexer. Bisher ist der Datenfluss identisch mit dem Datenfluss für Nicht-SmartStore-Indizes.
Wenn der heiße Eimer ins Warme rollt, divergiert der Datenfluss. Der Quellindexer kopiert den Warm Bucket in den Remote-Objektspeicher (Remote-Speicherebene), während die vorhandene Kopie in seinem Cache verbleibt, da Suchvorgänge häufig über kürzlich indizierte Daten ausgeführt werden. Die Zielindexer löschen jedoch ihre Kopien, da der Remotespeicher eine hohe Verfügbarkeit bietet, ohne dass mehrere lokale Kopien verwaltet werden müssen. Die Masterkopie des Buckets befindet sich jetzt im Remote-Speicher.
Das folgende Bild zeigt den Datenfluss von Splunk SmartStore.
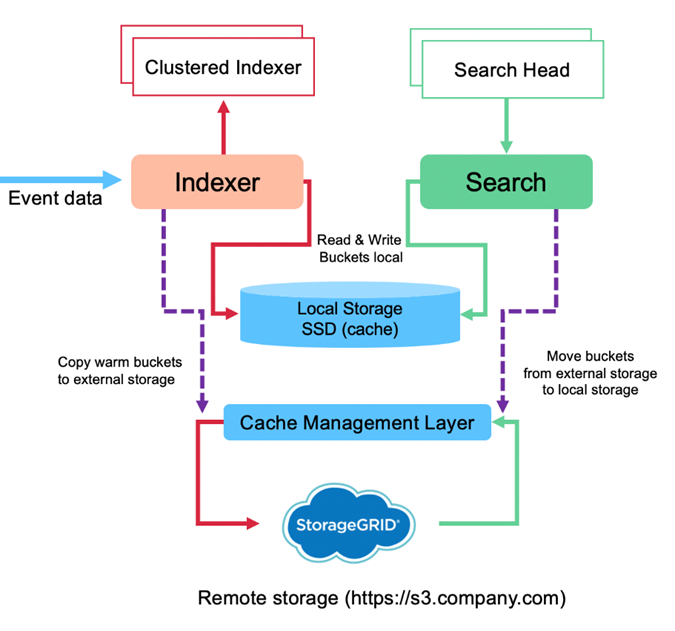
Der Cache-Manager auf dem Indexer ist für den SmartStore-Datenfluss von zentraler Bedeutung. Es ruft bei Bedarf Kopien von Buckets aus dem Remote-Speicher ab, um Suchanfragen zu verarbeiten. Außerdem werden ältere oder weniger häufig durchsuchte Kopien von Buckets aus dem Cache entfernt, da die Wahrscheinlichkeit, dass sie an Suchvorgängen teilnehmen, mit der Zeit abnimmt.
Die Aufgabe des Cache-Managers besteht darin, die Nutzung des verfügbaren Caches zu optimieren und gleichzeitig sicherzustellen, dass Suchvorgänge sofortigen Zugriff auf die benötigten Buckets haben.
Softwareanforderungen
In der folgenden Tabelle sind die Softwarekomponenten aufgeführt, die zur Implementierung der Lösung erforderlich sind. Die bei der Implementierung der Lösung verwendeten Softwarekomponenten können je nach Kundenanforderungen variieren.
| Produktfamilie | Produktname | Produktversion | Betriebssystem |
|---|---|---|---|
NetApp StorageGRID |
StorageGRID -Objektspeicher |
11,6 |
n/a |
CentOS |
CentOS |
8,1 |
CentOS 7.x |
Splunk Enterprise |
Splunk Enterprise mit SmartStore |
8.0.3 |
CentOS 7.x |
Anforderungen für Einzel- und Multisite-Standorte
In einer Enterprise-Splunk-Umgebung (mittlere und große Bereitstellungen), in der die Daten von vielen Maschinen stammen und viele Benutzer die Daten durchsuchen müssen, können Sie Ihre Bereitstellung skalieren, indem Sie Splunk Enterprise-Instanzen auf einzelne und mehrere Standorte verteilen.
Entdecken Sie die folgenden Vorteile der verteilten Bereitstellungen von Splunk Enterprise:
-
Zugriff auf vielfältige oder verteilte Datenquellen
-
Bereitstellung von Funktionen zur Bewältigung der Datenanforderungen von Unternehmen jeder Größe und Komplexität
-
Erreichen Sie hohe Verfügbarkeit und stellen Sie die Notfallwiederherstellung mit Datenreplikation und Multisite-Bereitstellung sicher
In der folgenden Tabelle sind die in einer verteilten Splunk Enterprise-Umgebung verwendeten Komponenten aufgeführt.
| Komponente | Beschreibung | Verantwortung |
|---|---|---|
Index-Cluster-Master |
Koordiniert Aktivitäten und Updates eines Indexer-Clusters |
Indexverwaltung |
Indexcluster |
Gruppe von Splunk Enterprise-Indexern, die so konfiguriert sind, dass sie die Daten des jeweils anderen replizieren |
Indizierung |
Suchkopf-Deployer |
Verarbeitet die Bereitstellung und Aktualisierung des Cluster-Masters |
Suchkopfverwaltung |
Suchkopfcluster |
Gruppe von Suchköpfen, die als zentrale Ressource für die Suche dient |
Suchverwaltung |
Lastenausgleichsmodule |
Wird von Clusterkomponenten verwendet, um die steigende Nachfrage von Suchköpfen, Indexern und S3-Zielen zu bewältigen und die Last auf die Clusterkomponenten zu verteilen. |
Lastmanagement für Clusterkomponenten |
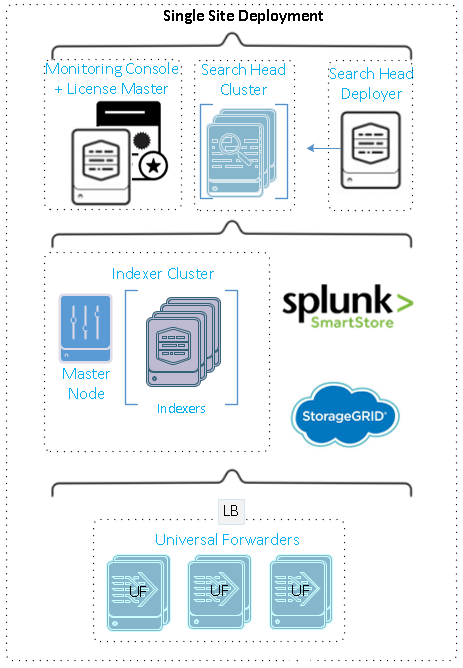
Diese Abbildung zeigt ein Beispiel für eine verteilte Bereitstellung an einem einzelnen Standort.
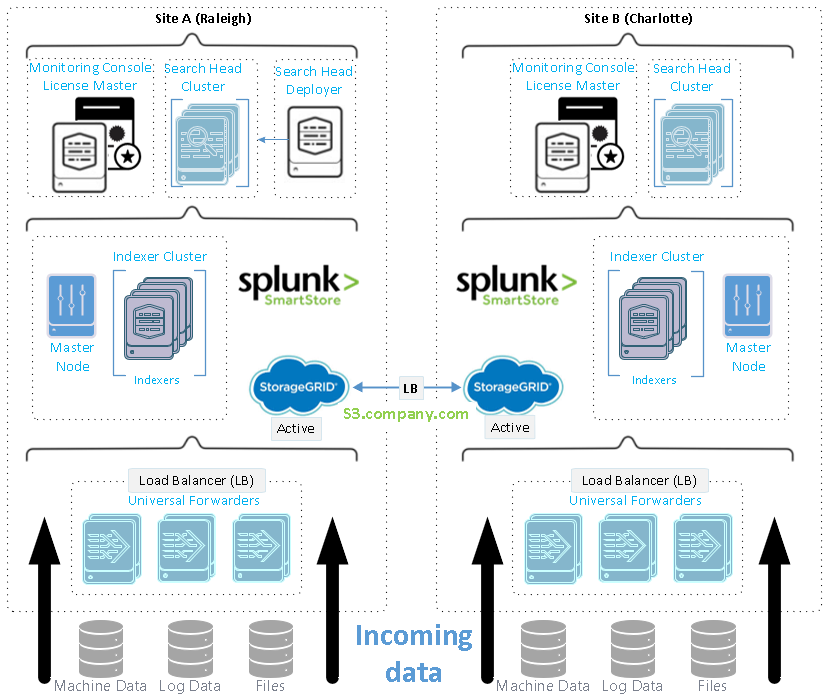
Diese Abbildung zeigt ein Beispiel für eine verteilte Bereitstellung an mehreren Standorten.
Hardwareanforderungen
In den folgenden Tabellen ist die Mindestanzahl an Hardwarekomponenten aufgeführt, die zur Implementierung der Lösung erforderlich sind. Die in bestimmten Implementierungen der Lösung verwendeten Hardwarekomponenten können je nach Kundenanforderungen variieren.

|
Unabhängig davon, ob Sie Splunk SmartStore und StorageGRID an einem oder mehreren Standorten bereitgestellt haben, werden alle Systeme über den StorageGRID GRID Manager in einer einzigen Fensteransicht verwaltet. Weitere Einzelheiten finden Sie im Abschnitt „Einfache Verwaltung mit Grid Manager“. |
In dieser Tabelle ist die für einen einzelnen Standort verwendete Hardware aufgeführt.
| Hardware | Menge | Scheibe | Nutzbare Kapazität | Hinweis |
|---|---|---|---|---|
StorageGRID SG1000 |
1 |
n/a |
n/a |
Admin-Knoten und Load Balancer |
StorageGRID SG6060 |
4 |
x48, 8 TB (NL-SAS-Festplatte) |
1PB |
Remote-Speicher |
In dieser Tabelle ist die für eine Multisite-Konfiguration verwendete Hardware (pro Site) aufgeführt.
| Hardware | Menge | Scheibe | Nutzbare Kapazität | Hinweis |
|---|---|---|---|---|
StorageGRID SG1000 |
2 |
n/a |
n/a |
Admin-Knoten und Load Balancer |
StorageGRID SG6060 |
4 |
x48, 8 TB (NL-SAS-Festplatte) |
1PB |
Remote-Speicher |
NetApp StorageGRID Load Balancer: SG1000
Für die Objektspeicherung ist die Verwendung eines Lastenausgleichs erforderlich, um den Cloud-Speicher-Namespace darzustellen. StorageGRID unterstützt Load Balancer von Drittanbietern führender Anbieter wie F5 und Citrix, viele Kunden entscheiden sich jedoch aufgrund seiner Einfachheit, Ausfallsicherheit und hohen Leistung für den StorageGRID -Balancer der Enterprise-Klasse. Der StorageGRID Load Balancer ist als VM, Container oder speziell entwickeltes Gerät verfügbar.
Das StorageGRID SG1000 ermöglicht die Verwendung von Hochverfügbarkeitsgruppen (HA) und intelligentem Lastenausgleich für S3-Datenpfadverbindungen. Kein anderes lokales Objektspeichersystem bietet einen angepassten Lastenausgleich.
Das SG1000-Gerät bietet die folgenden Funktionen:
-
Ein Load Balancer und optional Admin-Node-Funktionen für ein StorageGRID System
-
Der StorageGRID Appliance Installer vereinfacht die Bereitstellung und Konfiguration von Knoten
-
Vereinfachte Konfiguration von S3-Endpunkten und SSL
-
Dedizierte Bandbreite (im Gegensatz zur gemeinsamen Nutzung eines Load Balancers eines Drittanbieters mit anderen Anwendungen)
-
Bis zu 4 x 100 Gbit/s aggregierte Ethernet-Bandbreite
Das folgende Bild zeigt das SG1000 Gateway Services-Gerät.

SG6060
Das StorageGRID SG6060-Gerät umfasst einen Compute Controller (SG6060) und ein Storage Controller Shelf (E-Series E2860), das zwei Storage Controller und 60 Laufwerke enthält. Dieses Gerät bietet die folgenden Funktionen:
-
Skalieren Sie bis zu 400 PB in einem einzigen Namespace.
-
Bis zu 4 x 25 Gbit/s aggregierte Ethernet-Bandbreite.
-
Enthält den StorageGRID Appliance Installer zur Vereinfachung der Knotenbereitstellung und -konfiguration.
-
Jedes SG6060-Gerät kann über ein oder zwei zusätzliche Erweiterungsfächer für insgesamt 180 Laufwerke verfügen.
-
Zwei E-Series E2800-Controller (Duplex-Konfiguration) zur Bereitstellung von Speichercontroller-Failover-Unterstützung.
-
Laufwerksfach mit fünf Schubladen für sechzig 3,5-Zoll-Laufwerke (zwei Solid-State-Laufwerke und 58 NL-SAS-Laufwerke).
Das folgende Bild zeigt das Gerät SG6060.

Splunk-Design
Die folgende Tabelle listet die Splunk-Konfiguration für eine einzelne Site auf.
| Splunk-Komponente | Aufgabe | Menge | Kerne | Erinnerung | Betriebssystem |
|---|---|---|---|---|---|
Universal-Spediteur |
Verantwortlich für die Aufnahme und Weiterleitung von Daten an die Indexer |
4 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Indexer |
Verwaltet die Benutzerdaten |
10 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Suchkopf |
Das Benutzer-Frontend durchsucht Daten in Indexern |
3 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Suchkopf-Deployer |
Verarbeitet Updates für Suchkopfcluster |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Cluster-Master |
Verwaltet die Splunk-Installation und Indexer |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Überwachungskonsole und Lizenzmaster |
Führt eine zentrale Überwachung der gesamten Splunk-Bereitstellung durch und verwaltet Splunk-Lizenzen |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Die folgenden Tabellen beschreiben die Splunk-Konfiguration für Multisite-Konfigurationen.
Diese Tabelle listet die Splunk-Konfiguration für eine Multisite-Konfiguration (Site A) auf.
| Splunk-Komponente | Aufgabe | Menge | Kerne | Erinnerung | Betriebssystem |
|---|---|---|---|---|---|
Universal-Spediteur |
Verantwortlich für die Aufnahme und Weiterleitung der Daten an die Indexer. |
4 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Indexer |
Verwaltet die Benutzerdaten |
10 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Suchkopf |
Das Benutzer-Frontend durchsucht Daten in Indexern |
3 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Suchkopf-Deployer |
Verarbeitet Updates für Suchkopfcluster |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Cluster-Master |
Verwaltet die Splunk-Installation und Indexer |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Überwachungskonsole und Lizenzmaster |
Führt eine zentrale Überwachung der gesamten Splunk-Bereitstellung durch und verwaltet Splunk-Lizenzen. |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Diese Tabelle listet die Splunk-Konfiguration für eine Multisite-Konfiguration (Site B) auf.
| Splunk-Komponente | Aufgabe | Menge | Kerne | Erinnerung | Betriebssystem |
|---|---|---|---|---|---|
Universal-Spediteur |
Verantwortlich für die Aufnahme und Weiterleitung von Daten an die Indexer |
4 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Indexer |
Verwaltet die Benutzerdaten |
10 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Suchkopf |
Das Benutzer-Frontend durchsucht Daten in Indexern |
3 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Cluster-Master |
Verwaltet die Splunk-Installation und Indexer |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |
Überwachungskonsole und Lizenzmaster |
Führt eine zentrale Überwachung der gesamten Splunk-Bereitstellung durch und verwaltet Splunk-Lizenzen |
1 |
16 Kerne |
32 GB RAM |
CentOS 8.1 |