

SmartStore-Leistung an einem einzelnen Standort
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt wird die Leistung von Splunk SmartStore auf einem NetApp StorageGRID Controller beschrieben. Splunk SmartStore verschiebt warme Daten in den Remote-Speicher, in diesem Fall in den StorageGRID Objektspeicher bei der Leistungsvalidierung.
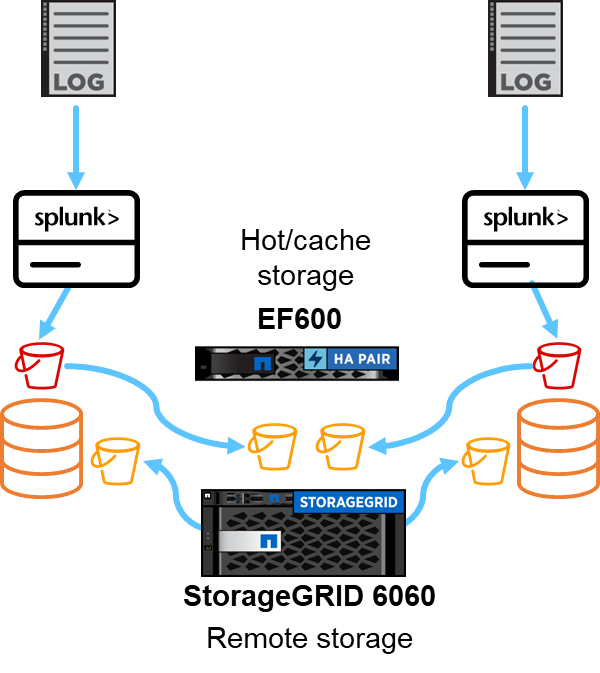
Wir haben EF600 für Hot-/Cache-Speicher und StorageGRID 6060 für Remote-Speicher verwendet. Für die Leistungsvalidierung haben wir die folgende Architektur verwendet. Wir haben zwei Suchköpfe, vier Heavy Forwarder zum Weiterleiten der Daten an Indexer, sieben Splunk Event Generators (Eventgens) zum Generieren der Echtzeitdaten und 18 Indexer zum Speichern der Daten verwendet.
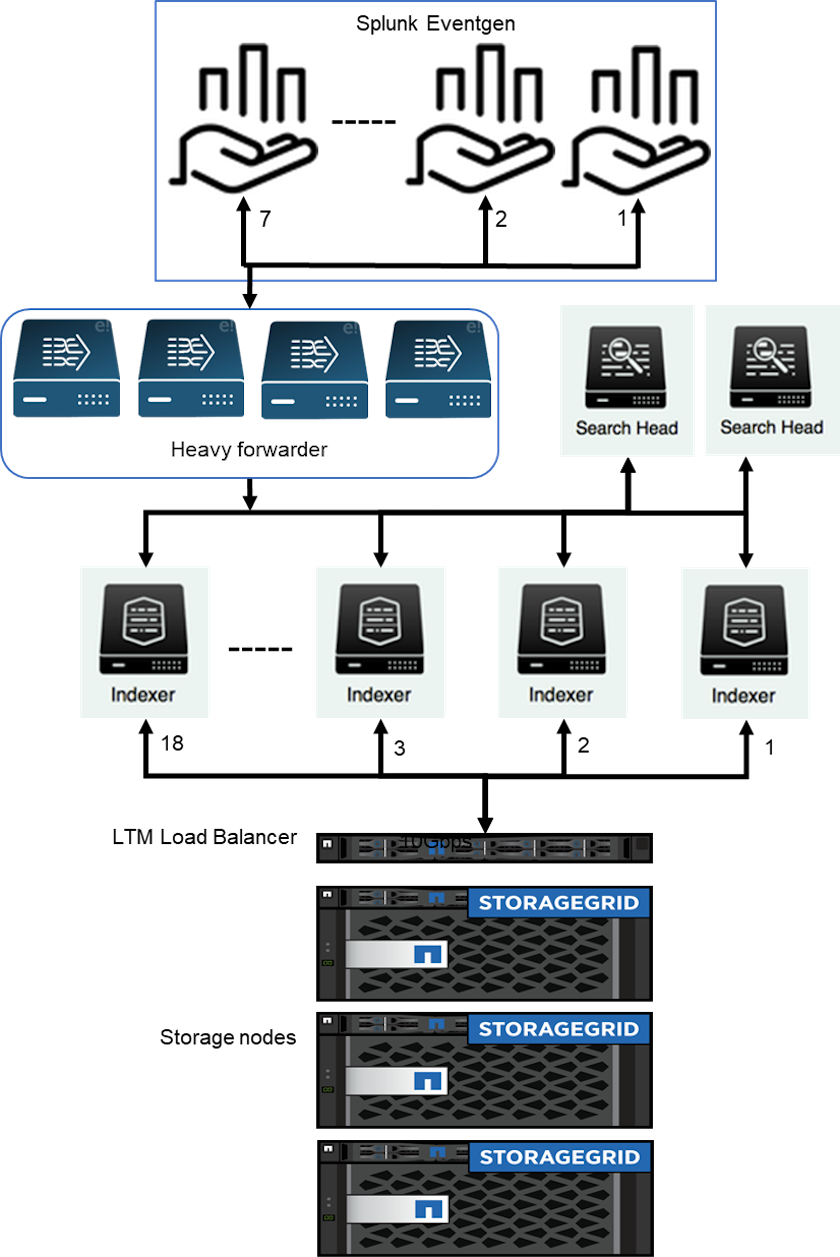
Konfiguration
In dieser Tabelle ist die für die Leistungsvalidierung von SmartStorage verwendete Hardware aufgeführt.
| Splunk-Komponente | Aufgabe | Menge | Kerne | Erinnerung | Betriebssystem |
|---|---|---|---|---|---|
Schwerlast-Forwarder |
Verantwortlich für die Aufnahme und Weiterleitung von Daten an die Indexer |
4 |
16 Kerne |
32 GB RAM |
SLED 15 SP2 |
Indexer |
Verwaltet die Benutzerdaten |
18 |
16 Kerne |
32 GB RAM |
SLED 15 SP2 |
Suchkopf |
Das Benutzer-Frontend sucht Daten in Indexern |
2 |
16 Kerne |
32 GB RAM |
SLED 15 SP2 |
Suchkopf-Deployer |
Verarbeitet Updates für Suchkopfcluster |
1 |
16 Kerne |
32 GB RAM |
SLED 15 SP2 |
Cluster-Master |
Verwaltet die Splunk-Installation und Indexer |
1 |
16 Kerne |
32 GB RAM |
SLED 15 SP2 |
Überwachungskonsole und Lizenzmaster |
Führt eine zentrale Überwachung der gesamten Splunk-Bereitstellung durch und verwaltet Splunk-Lizenzen |
1 |
16 Kerne |
32 GB RAM |
SLED 15 SP2 |
SmartStore Remote Store-Leistungsvalidierung
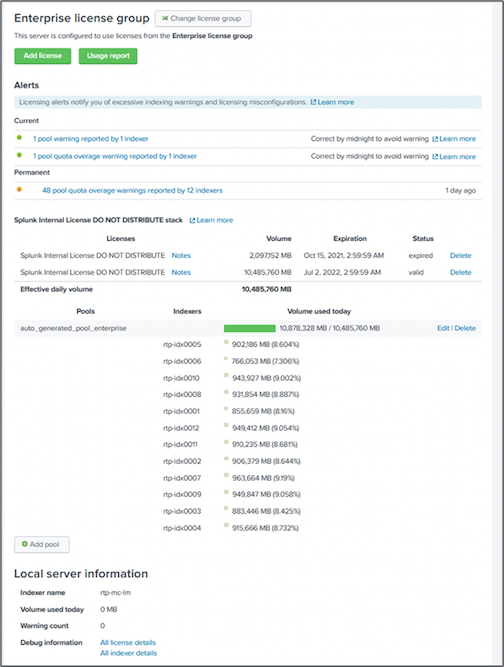
Bei dieser Leistungsvalidierung haben wir den SmartStore-Cache im lokalen Speicher auf allen Indexern für 10 Tage Daten konfiguriert. Wir haben die maxDataSize=auto (750 MB Bucket-Größe) im Splunk-Cluster-Manager und habe die Änderungen an alle Indexer gesendet. Um die Upload-Leistung zu messen, haben wir 10 Tage lang täglich 10 TB aufgenommen und alle Hot Buckets gleichzeitig auf Warm übertragen. Außerdem haben wir den Spitzen- und Durchschnittsdurchsatz pro Instanz und Bereitstellung über das Dashboard der SmartStore Monitoring Console erfasst.
Dieses Bild zeigt die an einem Tag aufgenommenen Daten.
Wir haben den folgenden Befehl vom Cluster-Master ausgeführt (der Indexname ist eventgen-test ). Anschließend haben wir den Spitzen- und Durchschnitts-Upload-Durchsatz pro Instanz und Bereitstellungsweite über die Dashboards der SmartStore Monitoring Console erfasst.
for i in rtp-idx0001 rtp-idx0002 rtp-idx0003 rtp-idx0004 rtp-idx0005 rtp-idx0006 rtp-idx0007 rtp-idx0008 rtp-idx0009 rtp-idx0010 rtp-idx0011 rtp-idx0012 rtp-idx0013011 rtdx0014 rtp-idx0015 rtp-idx0016 rtp-idx0017 rtp-idx0018 ; do ssh $i "hostname; date; /opt/splunk/bin/splunk _internal call /data/indexes/eventgen-test/roll-hot-buckets -auth admin:12345678; sleep 1 "; done

|
Der Cluster-Master verfügt über eine passwortlose Authentifizierung für alle Indexer (rtp-idx0001…rtp-idx0018). |
Um die Download-Leistung zu messen, haben wir alle Daten aus dem Cache entfernt, indem wir die Evict-CLI mit dem folgenden Befehl zweimal ausgeführt haben.
|
|
Wir haben den folgenden Befehl vom Clustermaster aus ausgeführt und die Suche vom Suchkopf aus über 10 Tage Daten aus dem Remotespeicher von StorageGRID ausgeführt. Anschließend haben wir den Spitzen- und Durchschnitts-Upload-Durchsatz pro Instanz und Bereitstellungsweite über die Dashboards der SmartStore Monitoring Console erfasst. |
for i in rtp-idx0001 rtp-idx0002 rtp-idx0003 rtp-idx0004 rtp-idx0005 rtp-idx0006 rtp-idx0007 rtp-idx0008 rtp-idx0009 rtp-idx0010 rtp-idx0011 rtp-idx0012 rtp-idx0013 rtp-idx0014 rtp-idx0015 rtp-idx0016 rtp-idx0017 rtp-idx0018 ; do ssh $i " hostname; date; /opt/splunk/bin/splunk _internal call /services/admin/cacheman/_evict -post:mb 1000000000 -post:path /mnt/EF600 -method POST -auth admin:12345678; "; done
Die Indexerkonfigurationen wurden vom SmartStore-Clustermaster gepusht. Der Cluster-Master hatte die folgende Konfiguration für den Indexer.
Rtp-cm01:~ # cat /opt/splunk/etc/master-apps/_cluster/local/indexes.conf [default] maxDataSize = auto #defaultDatabase = eventgen-basic defaultDatabase = eventgen-test hotlist_recency_secs = 864000 repFactor = auto [volume:remote_store] storageType = remote path = s3://smartstore2 remote.s3.access_key = U64TUHONBNC98GQGL60R remote.s3.secret_key = UBoXNE0jmECie05Z7iCYVzbSB6WJFckiYLcdm2yg remote.s3.endpoint = 3.sddc.netapp.com:10443 remote.s3.signature_version = v2 remote.s3.clientCert = [eventgen-basic] homePath = $SPLUNK_DB/eventgen-basic/db coldPath = $SPLUNK_DB/eventgen-basic/colddb thawedPath = $SPLUNK_DB/eventgen-basic/thawed [eventgen-migration] homePath = $SPLUNK_DB/eventgen-scale/db coldPath = $SPLUNK_DB/eventgen-scale/colddb thawedPath = $SPLUNK_DB/eventgen-scale/thaweddb [main] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [history] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [summary] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [remote-test] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb [eventgen-test] homePath = $SPLUNK_DB/$_index_name/db maxDataSize=auto maxHotBuckets=1 maxWarmDBCount=2 coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb [eventgen-evict-test] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb maxDataSize = auto_high_volume maxWarmDBCount = 5000 rtp-cm01:~ #
Wir haben die folgende Suchanfrage im Suchkopf ausgeführt, um die Leistungsmatrix zu erfassen.
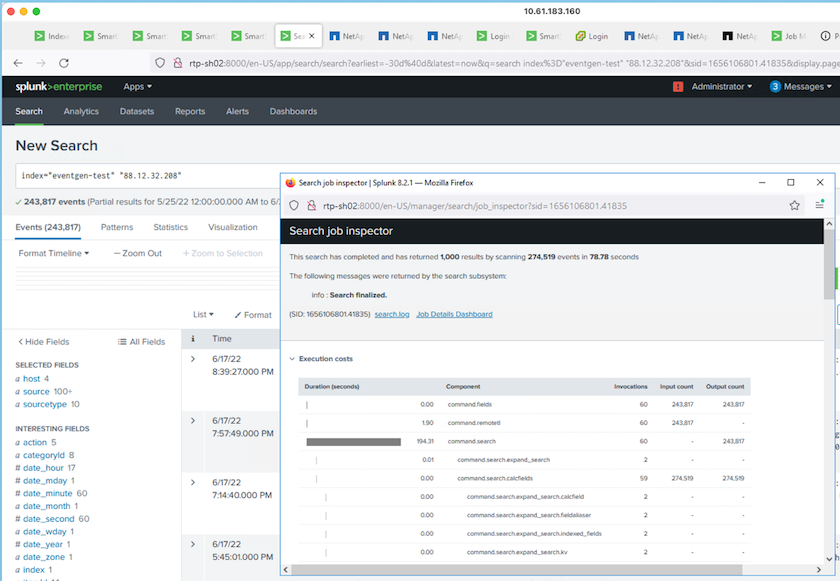
Wir haben die Leistungsinformationen vom Cluster-Master gesammelt. Die Spitzenleistung betrug 61,34 GBps.
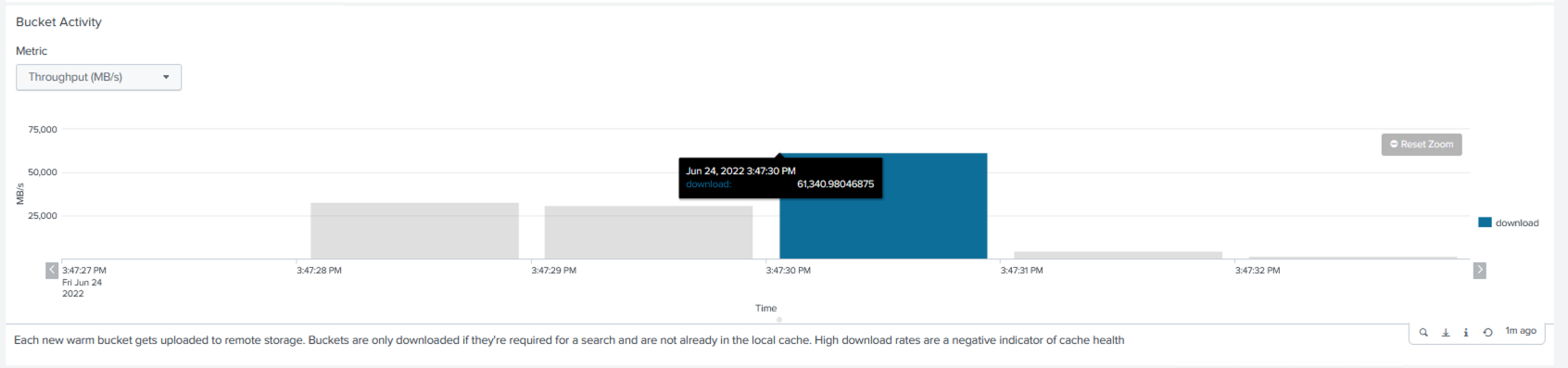
Die durchschnittliche Leistung lag bei etwa 29 GBps.
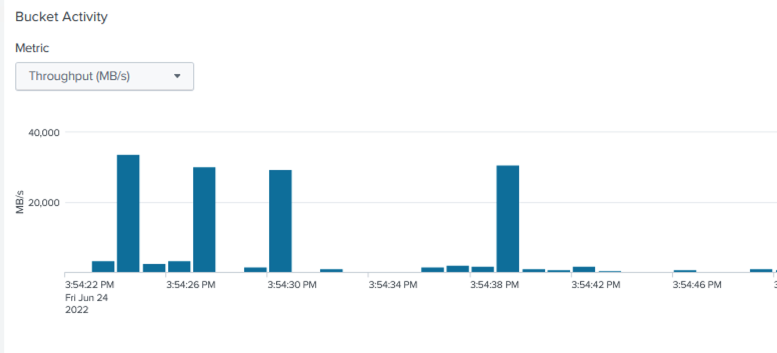
StorageGRID -Leistung
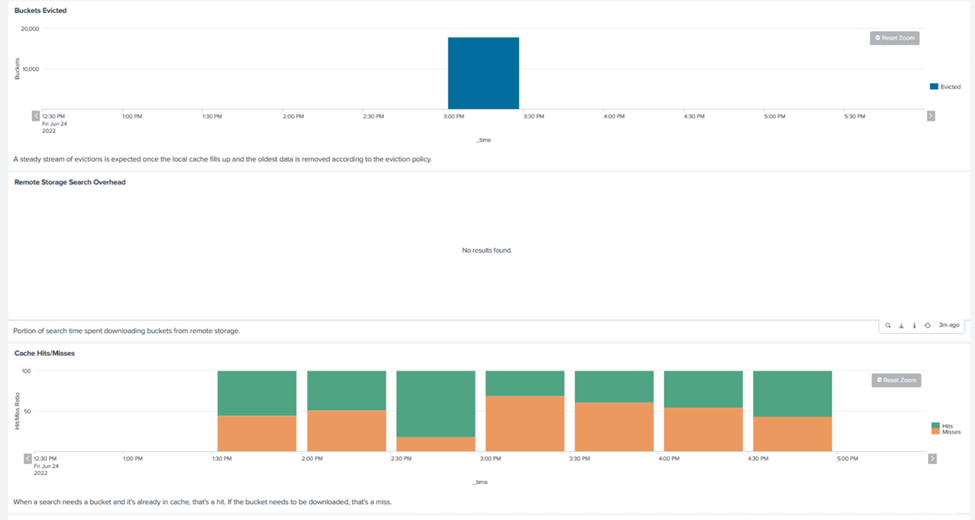
Die Leistung von SmartStore basiert auf der Suche nach bestimmten Mustern und Zeichenfolgen in großen Datenmengen. Bei dieser Validierung werden die Ereignisse generiert mit "Eventgen" auf einem bestimmten Splunk-Index (eventgen-test) über den Suchkopf, und die Anfrage geht für die meisten Abfragen an StorageGRID . Das folgende Bild zeigt die Treffer und Fehlschläge der Abfragedaten. Die Trefferdaten stammen von der lokalen Festplatte und die Fehlerdaten vom StorageGRID Controller.
|
|
Die grüne Farbe zeigt die Trefferdaten und die orange Farbe die Fehltrefferdaten. |
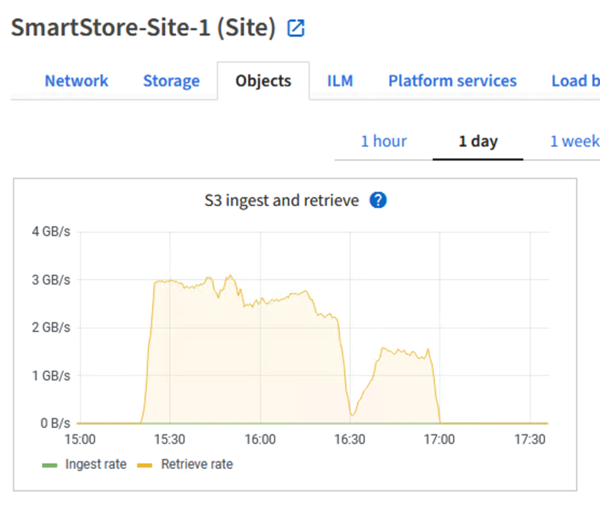
Wenn die Abfrage für die Suche auf StorageGRID ausgeführt wird, wird die Zeit für die S3-Abrufrate von StorageGRID im folgenden Bild angezeigt.
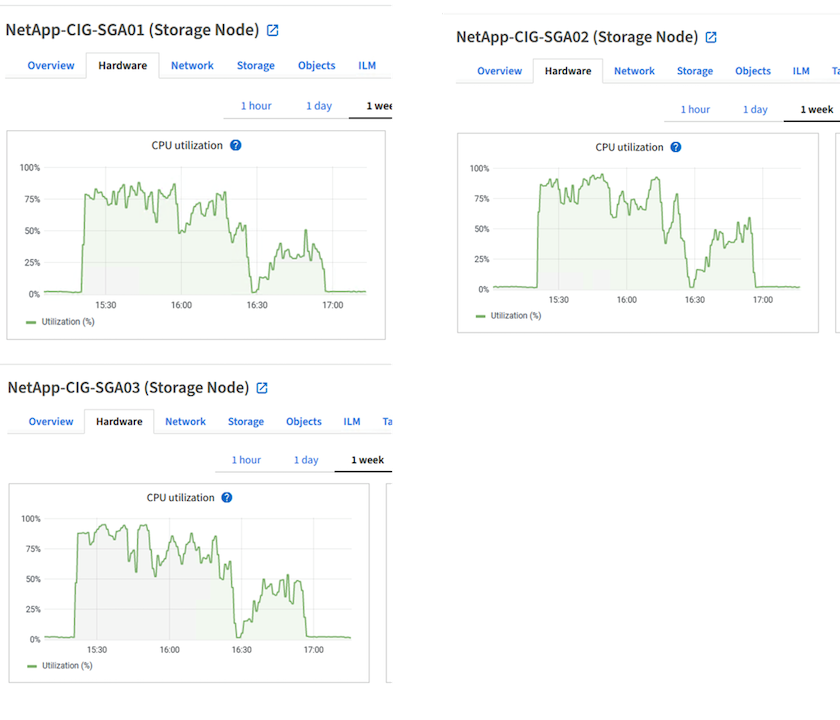
StorageGRID Hardwarenutzung
Die StorageGRID Instanz verfügt über einen Load Balancer und drei StorageGRID Controller. Die CPU-Auslastung für alle drei Controller liegt zwischen 75 % und 100 %.
SmartStore mit NetApp Storage Controller – Vorteile für den Kunden
-
Entkopplung von Rechenleistung und Speicher. Der Splunk SmartStore entkoppelt Rechenleistung und Speicher, sodass Sie diese unabhängig voneinander skalieren können.
-
Daten auf Anfrage. SmartStore bringt Daten bei Bedarf in die Nähe der Rechenleistung und bietet Rechen- und Speicherelastizität sowie Kosteneffizienz, um eine längere Datenaufbewahrung im großen Maßstab zu erreichen.
-
AWS S3 API-kompatibel. SmartStore verwendet die AWS S3-API zur Kommunikation mit dem Wiederherstellungsspeicher, einem AWS S3- und S3-API-kompatiblen Objektspeicher wie StorageGRID.
-
Reduziert Speicherbedarf und Kosten. SmartStore reduziert den Speicherbedarf für ältere Daten (warm/kalt). Es wird nur eine einzige Datenkopie benötigt, da der NetApp Speicher Datenschutz bietet und sich um Ausfälle und hohe Verfügbarkeit kümmert.
-
Hardwarefehler. Ein Knotenausfall in einer SmartStore-Bereitstellung macht die Daten nicht unzugänglich und ermöglicht eine viel schnellere Wiederherstellung des Indexers nach einem Hardwarefehler oder Datenungleichgewicht.
-
Anwendungs- und datenbewusster Cache.
-
Indexer hinzufügen/entfernen und Cluster nach Bedarf einrichten/abbauen.
-
Die Speicherebene ist nicht mehr an die Hardware gebunden.