

Testablauf und detaillierte Ergebnisse
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt werden die Ergebnisse des Testverfahrens im Detail beschrieben.
Bilderkennungstraining mit ResNet in ONTAP
Wir haben den ResNet50-Benchmark mit einem und zwei SR670 V2-Servern ausgeführt. Bei diesem Test wurde der MXNet 22.04-py3 NGC-Container zum Ausführen des Trainings verwendet.
Bei dieser Validierung haben wir folgendes Testverfahren verwendet:
-
Wir haben den Host-Cache vor dem Ausführen des Skripts geleert, um sicherzustellen, dass die Daten nicht bereits zwischengespeichert waren:
sync ; sudo /sbin/sysctl vm.drop_caches=3
-
Wir haben das Benchmark-Skript mit dem ImageNet-Datensatz im Serverspeicher (lokaler SSD-Speicher) sowie auf dem NetApp AFF Speichersystem ausgeführt.
-
Wir haben die Netzwerk- und lokale Speicherleistung mithilfe von
ddBefehl. -
Für den Einzelknotenlauf haben wir den folgenden Befehl verwendet:
python train_imagenet.py --gpus 0,1,2,3,4,5,6,7 --batch-size 408 --kv-store horovod --lr 10.5 --mom 0.9 --lr-step-epochs pow2 --lars-eta 0.001 --label-smoothing 0.1 --wd 5.0e-05 --warmup-epochs 2 --eval-period 4 --eval-offset 2 --optimizer sgdwfastlars --network resnet-v1b-stats-fl --num-layers 50 --num-epochs 37 --accuracy-threshold 0.759 --seed 27081 --dtype float16 --disp-batches 20 --image-shape 4,224,224 --fuse-bn-relu 1 --fuse-bn-add-relu 1 --bn-group 1 --min-random-area 0.05 --max-random-area 1.0 --conv-algo 1 --force-tensor-core 1 --input-layout NHWC --conv-layout NHWC --batchnorm-layout NHWC --pooling-layout NHWC --batchnorm-mom 0.9 --batchnorm-eps 1e-5 --data-train /data/train.rec --data-train-idx /data/train.idx --data-val /data/val.rec --data-val-idx /data/val.idx --dali-dont-use-mmap 0 --dali-hw-decoder-load 0 --dali-prefetch-queue 5 --dali-nvjpeg-memory-padding 256 --input-batch-multiplier 1 --dali- threads 6 --dali-cache-size 0 --dali-roi-decode 1 --dali-preallocate-width 5980 --dali-preallocate-height 6430 --dali-tmp-buffer-hint 355568328 --dali-decoder-buffer-hint 1315942 --dali-crop-buffer-hint 165581 --dali-normalize-buffer-hint 441549 --profile 0 --e2e-cuda-graphs 0 --use-dali
-
Für die verteilten Läufe haben wir das Parallelisierungsmodell des Parameterservers verwendet. Wir haben zwei Parameterserver pro Knoten verwendet und die Anzahl der Epochen auf die gleiche Anzahl wie beim Einzelknotenlauf eingestellt. Wir haben dies getan, weil verteiltes Training aufgrund einer unvollständigen Synchronisierung zwischen Prozessen oft mehr Epochen benötigt. Die unterschiedliche Anzahl von Epochen kann Vergleiche zwischen Einzelknoten- und verteilten Fällen verzerren.
Datenlesegeschwindigkeit: Lokaler Speicher im Vergleich zum Netzwerkspeicher
Die Lesegeschwindigkeit wurde getestet mit dem dd Befehl für eine der Dateien für den ImageNet-Datensatz. Insbesondere haben wir die folgenden Befehle sowohl für lokale als auch für Netzwerkdaten ausgeführt:
sync ; sudo /sbin/sysctl vm.drop_caches=3dd if=/a400-100g/netapp-ra/resnet/data/preprocessed_data/train.rec of=/dev/null bs=512k count=2048Results (average of 5 runs): Local storage: 1.7 GB/s Network storage: 1.5 GB/s.
Beide Werte sind ähnlich und zeigen, dass der Netzwerkspeicher Daten mit einer ähnlichen Geschwindigkeit wie der lokale Speicher liefern kann.
Gemeinsamer Anwendungsfall: Mehrere, unabhängige, gleichzeitige Jobs
Dieser Test simulierte den erwarteten Anwendungsfall für diese Lösung: KI-Training für mehrere Jobs und mehrere Benutzer. Jeder Knoten führte sein eigenes Training durch und nutzte dabei den gemeinsam genutzten Netzwerkspeicher. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Sie zeigt, dass der Lösungsfall eine hervorragende Leistung lieferte, wobei alle Jobs im Wesentlichen mit der gleichen Geschwindigkeit wie die einzelnen Jobs ausgeführt wurden. Der Gesamtdurchsatz skaliert linear mit der Anzahl der Knoten.
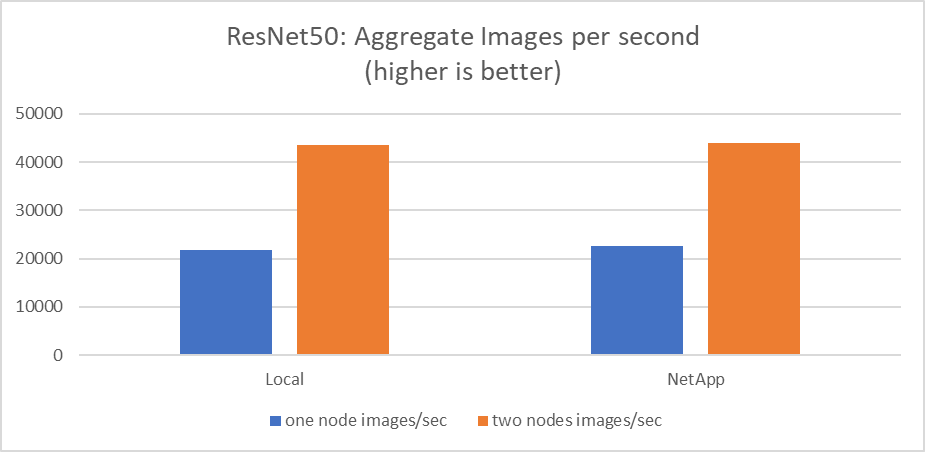
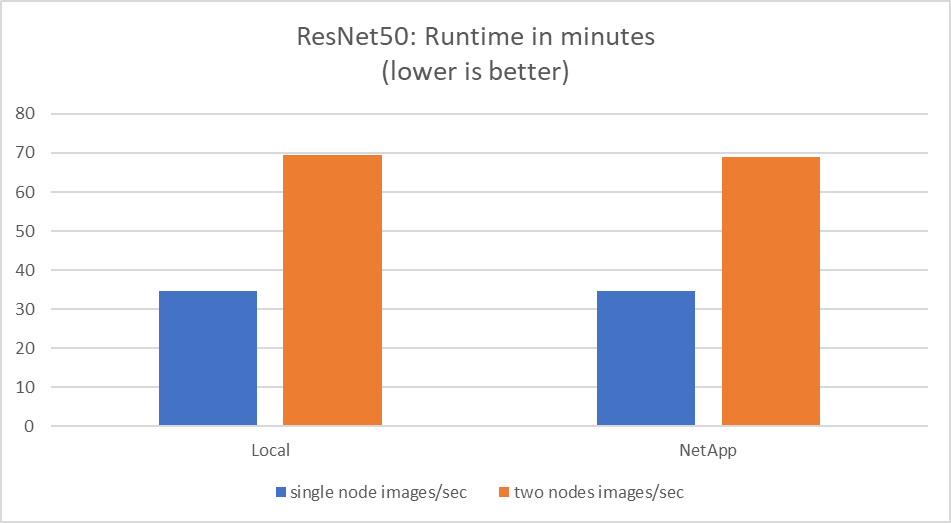
Diese Diagramme stellen die Laufzeit in Minuten und die aggregierten Bilder pro Sekunde für Rechenknoten dar, die acht GPUs von jedem Server in einem 100-GbE-Clientnetzwerk verwendeten und sowohl das gleichzeitige Trainingsmodell als auch das Einzeltrainingsmodell kombinierten. Die durchschnittliche Laufzeit des Trainingsmodells betrug 35 Minuten und 9 Sekunden. Die einzelnen Laufzeiten betrugen 34 Minuten und 32 Sekunden, 36 Minuten und 21 Sekunden, 34 Minuten und 37 Sekunden, 35 Minuten und 25 Sekunden sowie 34 Minuten und 31 Sekunden. Die durchschnittliche Anzahl an Bildern pro Sekunde für das Trainingsmodell betrug 22.573 und die Anzahl an Einzelbildern pro Sekunde betrug 21.764, 23.438, 22.556, 22.564 und 22.547.
Basierend auf unserer Validierung betrug die Laufzeit eines unabhängigen Trainingsmodells mit NetApp -Daten 34 Minuten und 54 Sekunden bei 22.231 Bildern/Sek. Ein unabhängiges Trainingsmodell mit lokalen Daten (DAS) benötigte eine Laufzeit von 34 Minuten und 21 Sekunden bei 22.102 Bildern/Sek. Während dieser Läufe lag die durchschnittliche GPU-Auslastung bei 96 %, wie auf nvidia-smi beobachtet. Beachten Sie, dass dieser Durchschnitt die Testphase umfasst, in der keine GPUs verwendet wurden, während die CPU-Auslastung laut mpstat-Messung 40 % betrug. Dies zeigt, dass die Datenübermittlungsrate in jedem Fall ausreichend ist.