

TR-4928: Verantwortungsvolle KI und vertrauliche Inferenz – NetApp KI mit Protopia Image- und Datentransformation
 Änderungen vorschlagen
Änderungen vorschlagen
Sathish Thyagarajan, Michael Oglesby, NetApp Byung Hoon Ahn, Jennifer Cwagenberg, Protopia
Visuelle Interpretationen sind mit dem Aufkommen der Bilderfassung und Bildverarbeitung zu einem integralen Bestandteil der Kommunikation geworden. Künstliche Intelligenz (KI) in der digitalen Bildverarbeitung eröffnet neue Geschäftsmöglichkeiten, etwa im medizinischen Bereich zur Erkennung von Krebs und anderen Krankheiten, in der georäumlichen visuellen Analyse zur Untersuchung von Umweltgefahren, in der Mustererkennung, in der Videoverarbeitung zur Verbrechensbekämpfung usw. Allerdings bringt diese Chance auch außergewöhnliche Verantwortung mit sich.
Je mehr Entscheidungen Unternehmen in die Hände von KI legen, desto mehr Risiken gehen sie hinsichtlich Datenschutz und -sicherheit sowie rechtlicher, ethischer und regulatorischer Fragen ein. Verantwortungsvolle KI ermöglicht eine Praxis, die es Unternehmen und Regierungsorganisationen erlaubt, Vertrauen und Governance aufzubauen, was für KI im großen Maßstab in großen Unternehmen von entscheidender Bedeutung ist. Dieses Dokument beschreibt eine von NetApp in drei verschiedenen Szenarien validierte KI-Inferenzlösung. Dabei kommen NetApp Datenverwaltungstechnologien mit der Datenverschleierungssoftware Protopia zum Einsatz, um sensible Daten zu privatisieren und Risiken und ethische Bedenken zu reduzieren.
Täglich werden von Verbrauchern und Unternehmen mit verschiedenen digitalen Geräten Millionen von Bildern erstellt. Die daraus resultierende massive Explosion der Datenmengen und der Rechenlast führt dazu, dass Unternehmen aus Gründen der Skalierbarkeit und Effizienz auf Cloud-Computing-Plattformen zurückgreifen. Gleichzeitig treten bei der Übertragung in eine öffentliche Cloud Datenschutzbedenken hinsichtlich der in den Bilddaten enthaltenen sensiblen Informationen auf. Der Mangel an Sicherheits- und Datenschutzgarantien wird zum Haupthindernis für den Einsatz von KI-Systemen zur Bildverarbeitung.
Darüber hinaus gibt es die "Recht auf Löschung" durch die DSGVO das Recht einer Einzelperson, von einer Organisation die Löschung aller ihrer personenbezogenen Daten zu verlangen. Es gibt auch die "Datenschutzgesetz" , das einen Kodex für faire Informationspraktiken festlegt. Digitale Bilder wie Fotos können personenbezogene Daten im Sinne der DSGVO darstellen, die regelt, wie Daten erhoben, verarbeitet und gelöscht werden müssen. Andernfalls verstoßen Sie gegen die DSGVO und können wegen Verstößen gegen die Vorschriften mit hohen Geldstrafen belegt werden, die für Unternehmen ernsthaften Schaden verursachen können. Datenschutzgrundsätze bilden das Rückgrat der Implementierung verantwortungsvoller KI, die Fairness bei den Modellvorhersagen für maschinelles Lernen (ML) und Deep Learning (DL) gewährleisten und die mit der Verletzung des Datenschutzes oder der Einhaltung gesetzlicher Vorschriften verbundenen Risiken senken.
Dieses Dokument beschreibt eine validierte Designlösung für drei verschiedene Szenarien mit und ohne Bildverschleierung, die für den Schutz der Privatsphäre und die Bereitstellung einer verantwortungsvollen KI-Lösung relevant sind:
-
Szenario 1. On-Demand-Inferenz innerhalb des Jupyter-Notebooks.
-
Szenario 2. Batch-Inferenz auf Kubernetes.
-
Szenario 3. NVIDIA Triton-Inferenzserver.
Für diese Lösung verwenden wir den Face Detection Data Set and Benchmark (FDDB), einen Datensatz von Gesichtsregionen, der für die Untersuchung des Problems der uneingeschränkten Gesichtserkennung entwickelt wurde, kombiniert mit dem PyTorch-Framework für maschinelles Lernen zur Implementierung von FaceBoxes. Dieser Datensatz enthält die Anmerkungen zu 5171 Gesichtern in einem Satz von 2845 Bildern mit unterschiedlichen Auflösungen. Darüber hinaus stellt dieser technische Bericht einige der Lösungsbereiche und relevanten Anwendungsfälle vor, die von NetApp -Kunden und Außendiensttechnikern in Situationen gesammelt wurden, in denen diese Lösung anwendbar ist.
Zielgruppe
Dieser technische Bericht richtet sich an folgende Zielgruppen:
-
Führungskräfte und Unternehmensarchitekten, die verantwortungsvolle KI entwickeln und einsetzen und sich mit Datenschutz- und Privatsphäreproblemen im Zusammenhang mit der Gesichtsbildverarbeitung im öffentlichen Raum befassen möchten.
-
Datenwissenschaftler, Dateningenieure, KI-/Maschinelles-Lernen-(ML-)Forscher und Entwickler von KI-/ML-Systemen, die den Schutz und die Wahrung der Privatsphäre zum Ziel haben.
-
Unternehmensarchitekten, die Datenverschleierungslösungen für KI/ML-Modelle und -Anwendungen entwerfen, die regulatorischen Standards wie der DSGVO, dem CCPA oder dem Datenschutzgesetz des Verteidigungsministeriums (DoD) und von Regierungsorganisationen entsprechen.
-
Datenwissenschaftler und KI-Ingenieure suchen nach effizienten Möglichkeiten zum Einsatz von Deep Learning (DL) und KI/ML/DL-Inferenzmodellen, die vertrauliche Informationen schützen.
-
Edge-Gerätemanager und Edge-Server-Administratoren, die für die Bereitstellung und Verwaltung von Edge-Inferenzmodellen verantwortlich sind.
Lösungsarchitektur
Diese Lösung ist für die Verarbeitung von KI-Workloads mit Echtzeit- und Batch-Inferenz auf großen Datensätzen konzipiert, indem sie die Verarbeitungsleistung von GPUs neben herkömmlichen CPUs nutzt. Diese Validierung demonstriert die datenschutzkonforme Schlussfolgerung für ML und optimales Datenmanagement, die für Organisationen erforderlich sind, die verantwortungsvolle KI-Bereitstellungen anstreben. Diese Lösung bietet eine Architektur, die für eine Kubernetes-Plattform mit einem oder mehreren Knoten für Edge- und Cloud-Computing geeignet ist, die mit NetApp ONTAP AI im Kern vor Ort, NetApp DataOps Toolkit und Protopia-Verschleierungssoftware unter Verwendung von Jupyter Lab und CLI-Schnittstellen verbunden ist. Die folgende Abbildung zeigt die Übersicht über die logische Architektur des Data Fabric, das von NetApp mit DataOps Toolkit und Protopia betrieben wird.
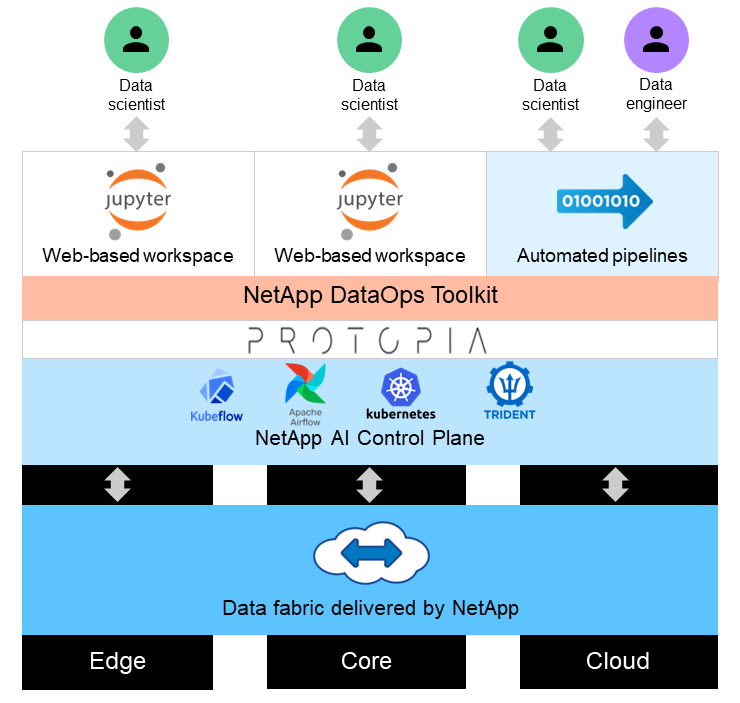
Die Verschleierungssoftware Protopia läuft nahtlos auf dem NetApp DataOps Toolkit und transformiert die Daten, bevor sie den Speicherserver verlassen.