

Testverfahren
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt werden die Aufgaben beschrieben, die zum Abschließen der Validierung erforderlich sind.
Voraussetzungen
Um die in diesem Abschnitt beschriebenen Aufgaben auszuführen, müssen Sie Zugriff auf einen Linux- oder macOS-Host haben, auf dem die folgenden Tools installiert und konfiguriert sind:
Szenario 1 – On-Demand-Inferenz in JupyterLab
-
Erstellen Sie einen Kubernetes-Namespace für AI/ML-Inferenz-Workloads.
$ kubectl create namespace inference namespace/inference created
-
Verwenden Sie das NetApp DataOps Toolkit, um ein persistentes Volume zum Speichern der Daten bereitzustellen, auf denen Sie die Inferenz durchführen.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Verwenden Sie das NetApp DataOps Toolkit, um einen neuen JupyterLab-Arbeitsbereich zu erstellen. Mounten Sie das im vorherigen Schritt erstellte persistente Volume mithilfe des
--mount- pvcOption. Weisen Sie dem Arbeitsbereich nach Bedarf NVIDIA -GPUs zu, indem Sie die-- nvidia-gpuOption.Im folgenden Beispiel wird das persistente Volume
inference-datawird im JupyterLab-Arbeitsbereichscontainer unter/home/jovyan/data. Bei Verwendung offizieller Project Jupyter-Container-Images/home/jovyanwird als oberstes Verzeichnis innerhalb der JupyterLab-Weboberfläche angezeigt.$ netapp_dataops_k8s_cli.py create jupyterlab --namespace=inference --workspace-name=live-inference --size=50Gi --nvidia-gpu=2 --mount-pvc=inference-data:/home/jovyan/data Set workspace password (this password will be required in order to access the workspace): Re-enter password: Creating persistent volume for workspace... Creating PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Creating Service 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Service successfully created. Attaching Additional PVC: 'inference-data' at mount_path: '/home/jovyan/data'. Creating Deployment 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Deployment 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Deployment 'ntap-dsutil-jupyterlab-live-inference' to reach Ready state. Deployment successfully created. Workspace successfully created. To access workspace, navigate to http://192.168.0.152:32721
-
Greifen Sie auf den JupyterLab-Arbeitsbereich zu, indem Sie die URL verwenden, die in der Ausgabe des
create jupyterlabBefehl. Das Datenverzeichnis stellt das persistente Volume dar, das im Arbeitsbereich bereitgestellt wurde.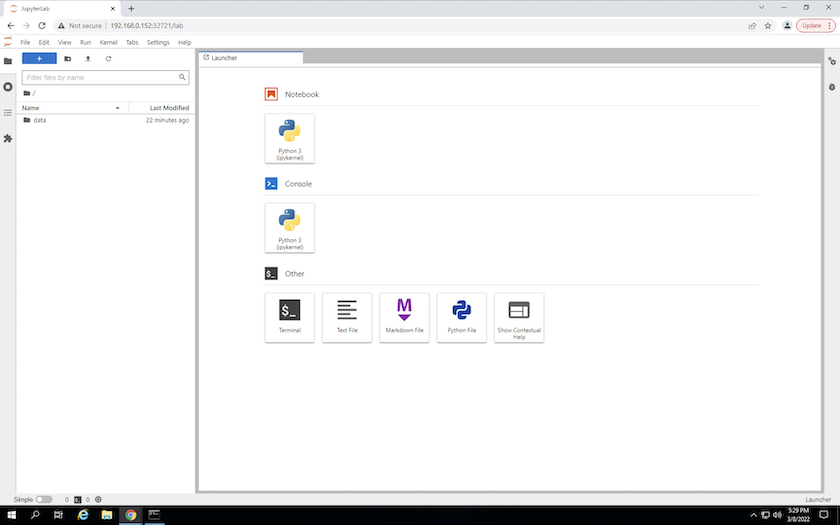
-
Öffnen Sie die
dataVerzeichnis und laden Sie die Dateien hoch, für die die Inferenz durchgeführt werden soll. Wenn Dateien in das Datenverzeichnis hochgeladen werden, werden sie automatisch auf dem persistenten Volume gespeichert, das im Arbeitsbereich bereitgestellt wurde. Um Dateien hochzuladen, klicken Sie auf das Symbol „Dateien hochladen“, wie im folgenden Bild gezeigt.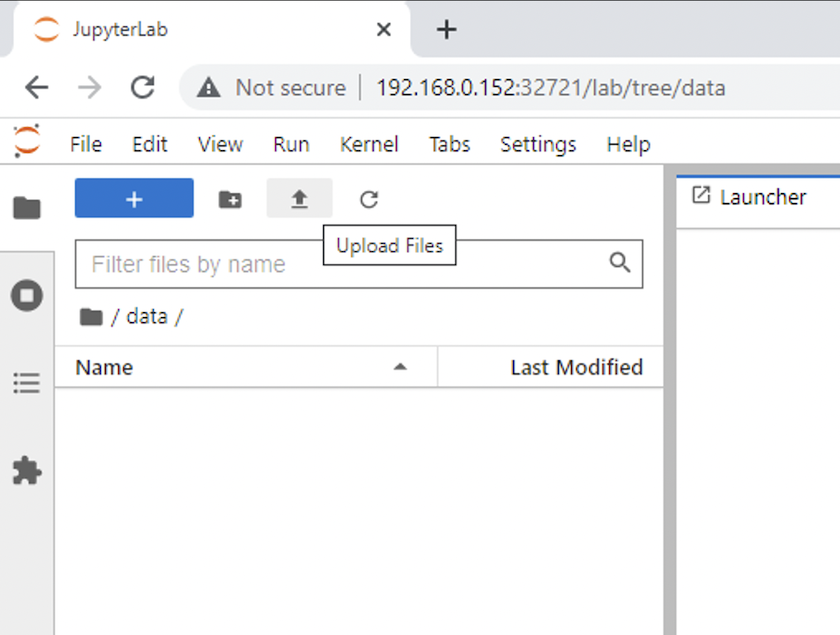
-
Kehren Sie zum obersten Verzeichnis zurück und erstellen Sie ein neues Notizbuch.
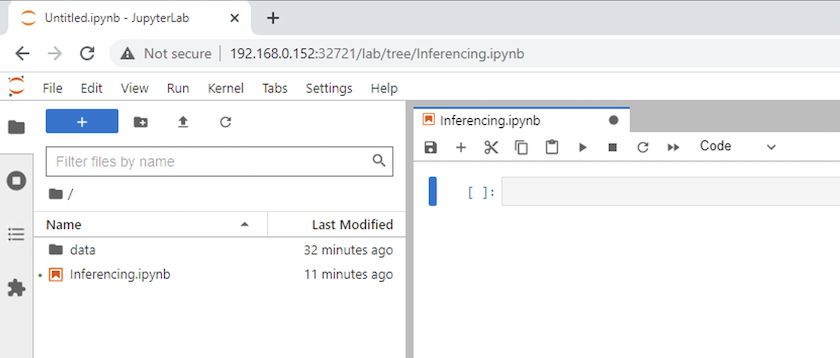
-
Fügen Sie dem Notebook Inferenzcode hinzu. Das folgende Beispiel zeigt Inferenzcode für einen Anwendungsfall zur Bilderkennung.
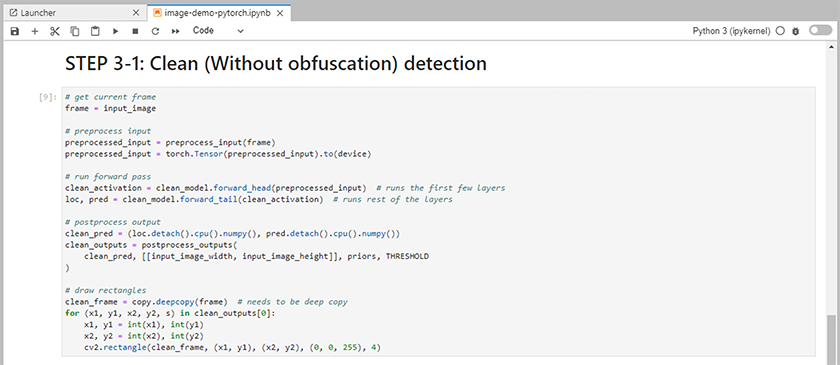
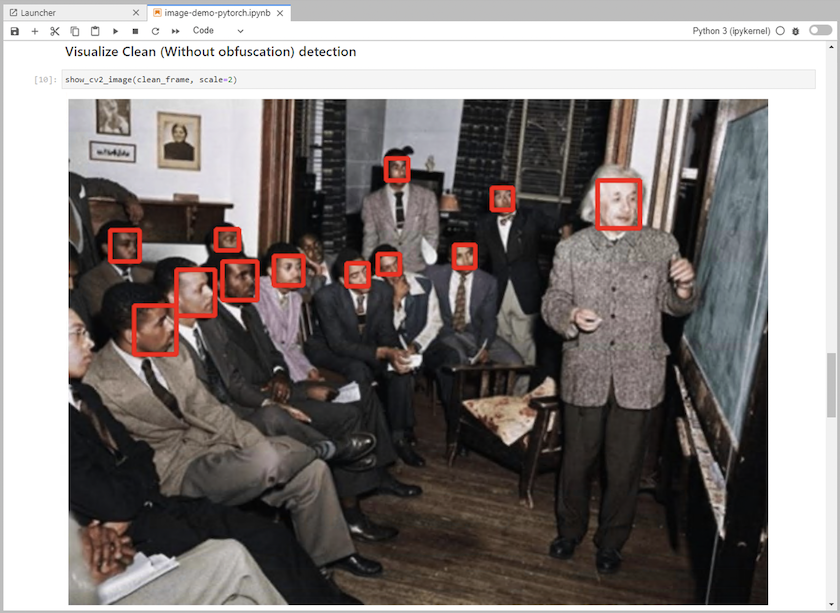
-
Fügen Sie Ihrem Inferenzcode die Protopia-Verschleierung hinzu. Protopia arbeitet direkt mit Kunden zusammen, um anwendungsfallspezifische Dokumentation bereitzustellen, und liegt außerhalb des Geltungsbereichs dieses technischen Berichts. Das folgende Beispiel zeigt Inferenzcode für einen Anwendungsfall zur Bilderkennung mit hinzugefügter Protopia-Verschleierung.
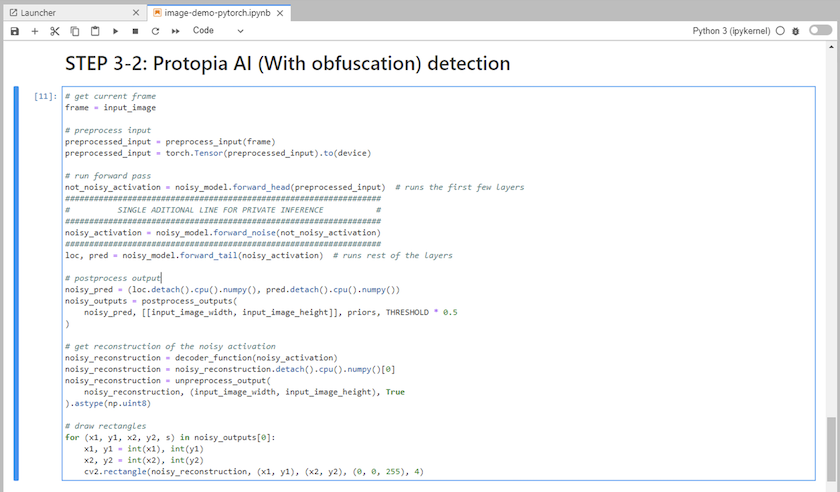
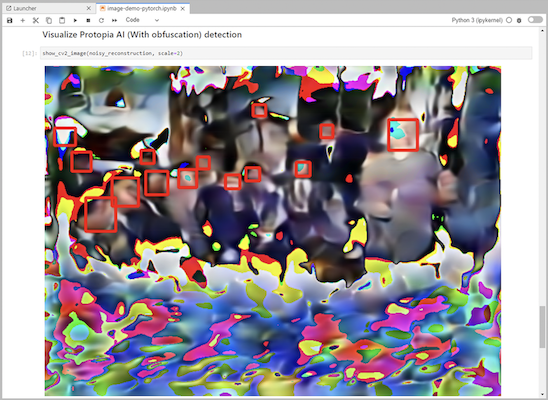
Szenario 2 – Batch-Inferenz auf Kubernetes
-
Erstellen Sie einen Kubernetes-Namespace für AI/ML-Inferenz-Workloads.
$ kubectl create namespace inference namespace/inference created
-
Verwenden Sie das NetApp DataOps Toolkit, um ein persistentes Volume zum Speichern der Daten bereitzustellen, auf denen Sie die Inferenz durchführen.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Füllen Sie das neue persistente Volume mit den Daten, für die Sie die Inferenz durchführen möchten.
Es gibt mehrere Methoden zum Laden von Daten auf ein PVC. Wenn Ihre Daten derzeit in einer S3-kompatiblen Objektspeicherplattform wie NetApp StorageGRID oder Amazon S3 gespeichert sind, können Sie "NetApp DataOps Toolkit S3 Data Mover-Funktionen" . Eine weitere einfache Methode besteht darin, einen JupyterLab-Arbeitsbereich zu erstellen und dann Dateien über die JupyterLab-Weboberfläche hochzuladen, wie in den Schritten 3 bis 5 im Abschnitt „Szenario 1 – On-Demand-Inferenz in JupyterLab ."
-
Erstellen Sie einen Kubernetes-Job für Ihre Batch-Inferenzaufgabe. Das folgende Beispiel zeigt einen Batch-Inferenzjob für einen Anwendungsfall zur Bilderkennung. Dieser Job führt für jedes Bild in einem Satz von Bildern eine Inferenz durch und schreibt Metriken zur Inferenzgenauigkeit in die Standardausgabe.
$ vi inference-job-raw.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-raw namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-raw.yaml job.batch/netapp-inference-raw created -
Bestätigen Sie, dass der Inferenzauftrag erfolgreich abgeschlossen wurde.
$ kubectl -n inference logs netapp-inference-raw-255sp 100%|██████████| 89/89 [00:52<00:00, 1.68it/s] Reading Predictions : 100%|██████████| 10/10 [00:01<00:00, 6.23it/s] Predicting ... : 100%|██████████| 10/10 [00:16<00:00, 1.64s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.9491256561145955 FDDB-fold-2 Val AP: 0.9205024466101926 FDDB-fold-3 Val AP: 0.9253013871078468 FDDB-fold-4 Val AP: 0.9399781485863011 FDDB-fold-5 Val AP: 0.9504280149478732 FDDB-fold-6 Val AP: 0.9416473519339292 FDDB-fold-7 Val AP: 0.9241631566241117 FDDB-fold-8 Val AP: 0.9072663297546659 FDDB-fold-9 Val AP: 0.9339648715035469 FDDB-fold-10 Val AP: 0.9447707905560152 FDDB Dataset Average AP: 0.9337148153739079 ================================================= mAP: 0.9337148153739079
-
Fügen Sie Ihrem Inferenzjob die Protopia-Verschleierung hinzu. Anwendungsfallspezifische Anweisungen zum Hinzufügen der Protopia-Verschleierung finden Sie direkt bei Protopia, was jedoch nicht in den Rahmen dieses technischen Berichts fällt. Das folgende Beispiel zeigt einen Batch-Inferenzjob für einen Anwendungsfall zur Gesichtserkennung mit hinzugefügter Protopia-Verschleierung unter Verwendung eines ALPHA-Werts von 0,8. Dieser Job wendet die Protopia-Verschleierung an, bevor er für jedes Bild in einem Satz von Bildern eine Inferenz durchführt, und schreibt dann die Inferenzgenauigkeitsmetriken in die Standardausgabe.
Wir haben diesen Schritt für die ALPHA-Werte 0,05, 0,1, 0,2, 0,4, 0,6, 0,8, 0,9 und 0,95 wiederholt. Die Ergebnisse können Sie in"Vergleich der Inferenzgenauigkeit."
$ vi inference-job-protopia-0.8.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-protopia-0.8 namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent env: - name: ALPHA value: "0.8" command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB", "--alpha", "$(ALPHA)", "--noisy"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-protopia-0.8.yaml job.batch/netapp-inference-protopia-0.8 created -
Bestätigen Sie, dass der Inferenzauftrag erfolgreich abgeschlossen wurde.
$ kubectl -n inference logs netapp-inference-protopia-0.8-b4dkz 100%|██████████| 89/89 [01:05<00:00, 1.37it/s] Reading Predictions : 100%|██████████| 10/10 [00:02<00:00, 3.67it/s] Predicting ... : 100%|██████████| 10/10 [00:22<00:00, 2.24s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.8953066115834589 FDDB-fold-2 Val AP: 0.8819580264029936 FDDB-fold-3 Val AP: 0.8781107458462862 FDDB-fold-4 Val AP: 0.9085731346308461 FDDB-fold-5 Val AP: 0.9166445508275378 FDDB-fold-6 Val AP: 0.9101178994188819 FDDB-fold-7 Val AP: 0.8383443678423771 FDDB-fold-8 Val AP: 0.8476311547659464 FDDB-fold-9 Val AP: 0.8739624502111121 FDDB-fold-10 Val AP: 0.8905468076424851 FDDB Dataset Average AP: 0.8841195749171925 ================================================= mAP: 0.8841195749171925
Szenario 3 – NVIDIA Triton Inference Server
-
Erstellen Sie einen Kubernetes-Namespace für AI/ML-Inferenz-Workloads.
$ kubectl create namespace inference namespace/inference created
-
Verwenden Sie das NetApp DataOps Toolkit, um ein persistentes Volume bereitzustellen, das als Modell-Repository für den NVIDIA Triton Inference Server verwendet werden kann.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=triton-model-repo --size=100Gi Creating PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'. PersistentVolumeClaim (PVC) 'triton-model-repo' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'.
-
Speichern Sie Ihr Modell auf dem neuen persistenten Datenträger in einem "Format" das vom NVIDIA Triton Inference Server erkannt wird.
Es gibt mehrere Methoden zum Laden von Daten auf ein PVC. Eine einfache Methode besteht darin, einen JupyterLab-Arbeitsbereich zu erstellen und dann Dateien über die JupyterLab-Weboberfläche hochzuladen, wie in den Schritten 3 bis 5 in "Szenario 1 – On-Demand-Inferenz in JupyterLab . "
-
Verwenden Sie das NetApp DataOps Toolkit, um eine neue NVIDIA Triton Inference Server-Instanz bereitzustellen.
$ netapp_dataops_k8s_cli.py create triton-server --namespace=inference --server-name=netapp-inference --model-repo-pvc-name=triton-model-repo Creating Service 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Service successfully created. Creating Deployment 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Deployment 'ntap-dsutil-triton-netapp-inference' created. Waiting for Deployment 'ntap-dsutil-triton-netapp-inference' to reach Ready state. Deployment successfully created. Server successfully created. Server endpoints: http: 192.168.0.152: 31208 grpc: 192.168.0.152: 32736 metrics: 192.168.0.152: 30009/metrics
-
Verwenden Sie ein Triton-Client-SDK, um eine Inferenzaufgabe auszuführen. Der folgende Python-Codeauszug verwendet das Triton Python-Client-SDK, um eine Inferenzaufgabe für einen Anwendungsfall zur Gesichtserkennung auszuführen. Dieses Beispiel ruft die Triton-API auf und übergibt ein Bild zur Inferenz. Der Triton Inference Server empfängt dann die Anfrage, ruft das Modell auf und gibt die Inferenzausgabe als Teil der API-Ergebnisse zurück.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass clean_activation = clean_model_head(preprocessed_input) # runs the first few layers ###################################################################################### # pass clean image to Triton Inference Server API for inferencing # ###################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_base" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(clean_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ###################################################################################### # postprocess output clean_pred = (loc_numpy, pred_numpy) clean_outputs = postprocess_outputs( clean_pred, [[input_image_width, input_image_height]], priors, THRESHOLD ) # draw rectangles clean_frame = copy.deepcopy(frame) # needs to be deep copy for (x1, y1, x2, y2, s) in clean_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(clean_frame, (x1, y1), (x2, y2), (0, 0, 255), 4) -
Fügen Sie Ihrem Inferenzcode die Protopia-Verschleierung hinzu. Anwendungsfallspezifische Anweisungen zum Hinzufügen der Protopia-Verschleierung finden Sie direkt von Protopia aus. Dieser Vorgang liegt jedoch außerhalb des Rahmens dieses technischen Berichts. Das folgende Beispiel zeigt denselben Python-Code wie im vorherigen Schritt 5, jedoch mit hinzugefügter Protopia-Verschleierung.
Beachten Sie, dass die Protopia-Verschleierung auf das Bild angewendet wird, bevor es an die Triton-API übergeben wird. Somit verlässt das nicht verschleierte Bild nie die lokale Maschine. Nur das verschleierte Bild wird über das Netzwerk übertragen. Dieser Workflow ist auf Anwendungsfälle anwendbar, in denen Daten innerhalb einer vertrauenswürdigen Zone erfasst werden, dann aber zur Inferenz außerhalb dieser vertrauenswürdigen Zone weitergeleitet werden müssen. Ohne die Verschleierung durch Protopia ist es nicht möglich, diese Art von Workflow zu implementieren, ohne dass vertrauliche Daten jemals die vertrauenswürdige Zone verlassen.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass not_noisy_activation = noisy_model_head(preprocessed_input) # runs the first few layers ################################################################## # obfuscate image locally prior to inferencing # # SINGLE ADITIONAL LINE FOR PRIVATE INFERENCE # ################################################################## noisy_activation = noisy_model_noise(not_noisy_activation) ################################################################## ########################################################################################### # pass obfuscated image to Triton Inference Server API for inferencing # ########################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_noisy" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(noisy_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ########################################################################################### # postprocess output noisy_pred = (loc_numpy, pred_numpy) noisy_outputs = postprocess_outputs( noisy_pred, [[input_image_width, input_image_height]], priors, THRESHOLD * 0.5 ) # get reconstruction of the noisy activation noisy_reconstruction = decoder_function(noisy_activation) noisy_reconstruction = noisy_reconstruction.detach().cpu().numpy()[0] noisy_reconstruction = unpreprocess_output( noisy_reconstruction, (input_image_width, input_image_height), True ).astype(np.uint8) # draw rectangles for (x1, y1, x2, y2, s) in noisy_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(noisy_reconstruction, (x1, y1), (x2, y2), (0, 0, 255), 4)