

Beispiel-Anwendungsfall – TensorFlow-Trainingsjob
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt werden die Aufgaben beschrieben, die ausgeführt werden müssen, um einen TensorFlow-Trainingsjob in einer NVIDIA AI Enterprise-Umgebung auszuführen.
Voraussetzungen
Bevor Sie die in diesem Abschnitt beschriebenen Schritte ausführen, gehen wir davon aus, dass Sie bereits eine Gast-VM-Vorlage erstellt haben, indem Sie die Anweisungen auf der"Aufstellen" Seite.
Gast-VM aus Vorlage erstellen
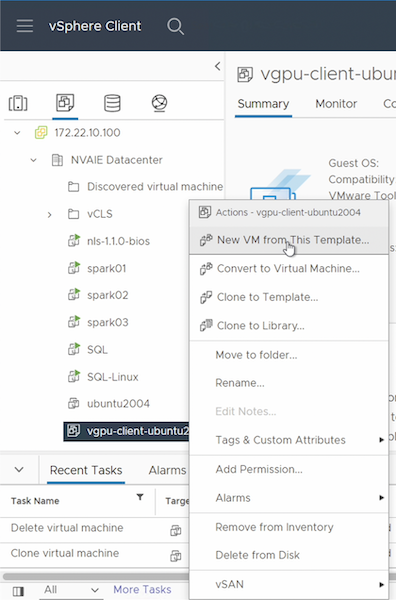
Zuerst müssen Sie eine neue Gast-VM aus der Vorlage erstellen, die Sie im vorherigen Abschnitt erstellt haben. Um eine neue Gast-VM aus Ihrer Vorlage zu erstellen, melden Sie sich bei VMware vSphere an, klicken Sie mit der rechten Maustaste auf den Vorlagennamen, wählen Sie „Neue VM aus dieser Vorlage …“ und folgen Sie dann dem Assistenten.
Datenvolume erstellen und bereitstellen
Als Nächstes müssen Sie ein neues Datenvolumen erstellen, auf dem Sie Ihren Trainingsdatensatz speichern. Mit dem NetApp DataOps Toolkit können Sie schnell ein neues Datenvolumen erstellen. Der folgende Beispielbefehl zeigt die Erstellung eines Volumes namens „imagenet“ mit einer Kapazität von 2 TB.
$ netapp_dataops_cli.py create vol -n imagenet -s 2TB
Bevor Sie Ihr Datenvolumen mit Daten füllen können, müssen Sie es in der Gast-VM mounten. Mit dem NetApp DataOps Toolkit können Sie schnell ein Datenvolumen bereitstellen. Der folgende Beispielbefehl zeigt das Mounten des im vorherigen Schritt erstellten Volumes.
$ sudo -E netapp_dataops_cli.py mount vol -n imagenet -m ~/imagenet
Datenvolumen auffüllen
Nachdem das neue Volume bereitgestellt und gemountet wurde, kann der Trainingsdatensatz vom Quellspeicherort abgerufen und auf dem neuen Volume platziert werden. Dies beinhaltet normalerweise das Abrufen der Daten aus einem S3- oder Hadoop-Datensee und manchmal die Unterstützung eines Dateningenieurs.
TensorFlow-Trainingsjob ausführen
Jetzt können Sie Ihren TensorFlow-Trainingsjob ausführen. Führen Sie die folgenden Aufgaben aus, um Ihren TensorFlow-Trainingsjob auszuführen.
-
Rufen Sie das NVIDIA NGC Enterprise TensorFlow-Containerimage ab.
$ sudo docker pull nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Starten Sie eine Instanz des NVIDIA NGC Enterprise TensorFlow-Containers. Verwenden Sie die Option „-v“, um Ihr Datenvolumen an den Container anzuhängen.
$ sudo docker run --gpus all -v ~/imagenet:/imagenet -it --rm nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Führen Sie Ihr TensorFlow-Trainingsprogramm innerhalb des Containers aus. Der folgende Beispielbefehl zeigt die Ausführung eines beispielhaften ResNet-50-Trainingsprogramms, das im Container-Image enthalten ist.
$ python ./nvidia-examples/cnn/resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16 --data_dir /imagenet/data