

Technologieübersicht
 Änderungen vorschlagen
Änderungen vorschlagen
Dieser Abschnitt konzentriert sich auf den Technologieüberblick für OpenSource MLOps mit NetApp.
Künstliche Intelligenz
KI ist eine Disziplin der Informatik, in der Computer darauf trainiert werden, die kognitiven Funktionen des menschlichen Geistes nachzuahmen. KI-Entwickler trainieren Computer, auf eine Weise zu lernen und Probleme zu lösen, die der des Menschen ähnelt oder dieser sogar überlegen ist. Deep Learning und maschinelles Lernen sind Teilgebiete der KI. Organisationen setzen zunehmend KI, ML und DL ein, um ihre kritischen Geschäftsanforderungen zu unterstützen. Einige Beispiele sind wie folgt:
-
Analyse großer Datenmengen, um bisher unbekannte Geschäftserkenntnisse zu gewinnen
-
Direkte Interaktion mit Kunden durch die Verarbeitung natürlicher Sprache
-
Automatisierung verschiedener Geschäftsprozesse und -funktionen
Moderne KI-Trainings- und Inferenz-Workloads erfordern massiv parallele Rechenkapazitäten. Daher werden GPUs zunehmend zur Ausführung von KI-Operationen eingesetzt, da die Parallelverarbeitungskapazitäten von GPUs denen von Allzweck-CPUs weit überlegen sind.
Behälter
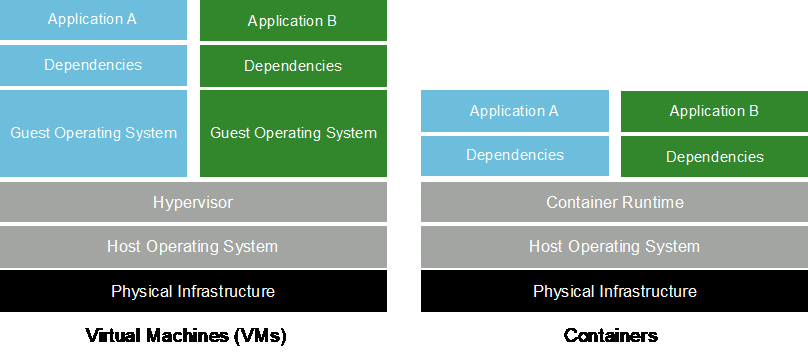
Container sind isolierte Benutzerbereichsinstanzen, die auf einem gemeinsam genutzten Host-Betriebssystemkernel ausgeführt werden. Die Nutzung von Containern nimmt rasant zu. Container bieten viele der gleichen Vorteile der Anwendungs-Sandboxing-Funktion wie virtuelle Maschinen (VMs). Da jedoch die Hypervisor- und Gastbetriebssystemebenen, auf die VMs angewiesen sind, eliminiert wurden, sind Container wesentlich leichter. Die folgende Abbildung zeigt eine Visualisierung von virtuellen Maschinen im Vergleich zu Containern.
Container ermöglichen außerdem die effiziente Verpackung von Anwendungsabhängigkeiten, Laufzeiten usw. direkt mit einer Anwendung. Das am häufigsten verwendete Container-Verpackungsformat ist der Docker-Container. Eine Anwendung, die im Docker-Containerformat containerisiert wurde, kann auf jedem Computer ausgeführt werden, auf dem Docker-Container ausgeführt werden können. Dies gilt auch dann, wenn die Abhängigkeiten der Anwendung nicht auf dem Computer vorhanden sind, da alle Abhängigkeiten im Container selbst verpackt sind. Weitere Informationen finden Sie im "Docker-Website" .
Kubernetes
Kubernetes ist eine Open-Source-Plattform zur verteilten Container-Orchestrierung, die ursprünglich von Google entwickelt wurde und jetzt von der Cloud Native Computing Foundation (CNCF) gepflegt wird. Kubernetes ermöglicht die Automatisierung von Bereitstellungs-, Verwaltungs- und Skalierungsfunktionen für containerisierte Anwendungen. In den letzten Jahren hat sich Kubernetes zur dominierenden Plattform für die Container-Orchestrierung entwickelt. Weitere Informationen finden Sie im "Kubernetes-Website" .
NetApp Trident
"Trident"ermöglicht die Nutzung und Verwaltung von Speicherressourcen auf allen gängigen NetApp Speicherplattformen, in der öffentlichen Cloud oder vor Ort, einschließlich ONTAP (AFF, FAS, Select, Cloud, Amazon FSx ONTAP), Azure NetApp Files Dienst und Google Cloud NetApp Volumes. Trident ist ein Container Storage Interface (CSI)-kompatibler dynamischer Speicher-Orchestrator, der nativ in Kubernetes integriert ist.
NetApp DataOps Toolkit
Der"NetApp DataOps Toolkit" ist ein Python-basiertes Tool, das die Verwaltung von Entwicklungs-/Schulungsarbeitsbereichen und Inferenzservern vereinfacht, die durch leistungsstarken, skalierbaren NetApp Speicher unterstützt werden. Zu den wichtigsten Funktionen gehören:
-
Stellen Sie schnell neue Arbeitsbereiche mit hoher Kapazität bereit, die durch leistungsstarken, skalierbaren NetApp Speicher unterstützt werden.
-
Klonen Sie Arbeitsbereiche mit hoher Kapazität nahezu sofort, um Experimente oder schnelle Iterationen zu ermöglichen.
-
Speichern Sie nahezu sofort Snapshots von Arbeitsbereichen mit hoher Kapazität für Backups und/oder zur Rückverfolgbarkeit/Baselining.
-
Stellen Sie Datenvolumes mit hoher Kapazität und hoher Leistung nahezu sofort bereit, klonen Sie sie und erstellen Sie Snapshots davon.
Apache Airflow
Apache Airflow ist eine Open-Source-Plattform für Workflow-Management, die die programmgesteuerte Erstellung, Planung und Überwachung komplexer Unternehmens-Workflows ermöglicht. Es wird häufig zur Automatisierung von ETL- und Datenpipeline-Workflows verwendet, ist jedoch nicht auf diese Arten von Workflows beschränkt. Das Airflow-Projekt wurde von Airbnb ins Leben gerufen, erfreut sich seitdem jedoch großer Beliebtheit in der Branche und steht nun unter der Schirmherrschaft der Apache Software Foundation. Airflow ist in Python geschrieben, Airflow-Workflows werden über Python-Skripte erstellt und Airflow ist nach dem Prinzip „Konfiguration als Code“ konzipiert. Viele Airflow-Benutzer in Unternehmen führen Airflow jetzt auf Kubernetes aus.
Gerichtete azyklische Graphen (DAGs)
In Airflow werden Workflows als gerichtete azyklische Graphen (DAGs) bezeichnet. DAGs bestehen aus Aufgaben, die je nach DAG-Definition nacheinander, parallel oder in einer Kombination aus beidem ausgeführt werden. Der Airflow-Scheduler führt einzelne Aufgaben auf einer Reihe von Workern aus und hält sich dabei an die in der DAG-Definition angegebenen Abhängigkeiten auf Aufgabenebene. DAGs werden über Python-Skripte definiert und erstellt.
Jupyter Notebook
Jupyter-Notebooks sind Wiki-ähnliche Dokumente, die sowohl Live-Code als auch beschreibenden Text enthalten. Jupyter Notebooks werden in der KI- und ML-Community häufig zum Dokumentieren, Speichern und Teilen von KI- und ML-Projekten verwendet. Weitere Informationen zu Jupyter Notebooks finden Sie auf der "Jupyter-Website" .
Jupyter Notebook Server
Ein Jupyter Notebook Server ist eine Open-Source-Webanwendung, mit der Benutzer Jupyter Notebooks erstellen können.
JupyterHub
JupyterHub ist eine Mehrbenutzeranwendung, die es einem einzelnen Benutzer ermöglicht, seinen eigenen Jupyter Notebook-Server bereitzustellen und darauf zuzugreifen. Weitere Informationen zu JupyterHub finden Sie auf der "JupyterHub-Website" .
MLflow
MLflow ist eine beliebte Open-Source-Plattform für das KI-Lebenszyklusmanagement. Zu den Hauptfunktionen von MLflow gehören die Verfolgung von KI/ML-Experimenten und ein KI/ML-Modell-Repository. Weitere Informationen zu MLflow finden Sie auf der "MLflow-Website" .
Kubeflow
Kubeflow ist ein Open-Source-KI- und ML-Toolkit für Kubernetes, das ursprünglich von Google entwickelt wurde. Das Kubeflow-Projekt macht die Bereitstellung von KI- und ML-Workflows auf Kubernetes einfach, portabel und skalierbar. Kubeflow abstrahiert die Feinheiten von Kubernetes und ermöglicht es Datenwissenschaftlern, sich auf das zu konzentrieren, was sie am besten können – Datenwissenschaft. Eine Visualisierung finden Sie in der folgenden Abbildung. Kubeflow ist eine gute Open-Source-Option für Organisationen, die eine All-in-One-MLOps-Plattform bevorzugen. Weitere Informationen finden Sie im "Kubeflow-Website" .
Kubeflow-Pipelines
Kubeflow-Pipelines sind eine Schlüsselkomponente von Kubeflow. Kubeflow Pipelines sind eine Plattform und ein Standard zum Definieren und Bereitstellen portabler und skalierbarer KI- und ML-Workflows. Weitere Informationen finden Sie im "offizielle Kubeflow-Dokumentation" .
Kubeflow-Notebooks
Kubeflow vereinfacht die Bereitstellung und Implementierung von Jupyter Notebook-Servern auf Kubernetes. Weitere Informationen zu Jupyter Notebooks im Kontext von Kubeflow finden Sie im "offizielle Kubeflow-Dokumentation" .
Katib
Katib ist ein Kubernetes-natives Projekt für automatisiertes maschinelles Lernen (AutoML). Katib unterstützt Hyperparameter-Tuning, Early Stopping und die Suche nach neuronalen Architekturen (NAS). Katib ist das Projekt, das unabhängig von Frameworks für maschinelles Lernen (ML) ist. Es kann Hyperparameter von Anwendungen optimieren, die in einer beliebigen Sprache der Wahl des Benutzers geschrieben sind, und unterstützt nativ viele ML-Frameworks wie TensorFlow, MXNet, PyTorch, XGBoost und andere. Katib unterstützt zahlreiche verschiedene AutoML-Algorithmen, wie etwa Bayes-Optimierung, Tree of Parzen-Schätzer, Zufallssuche, Covariance Matrix Adaptation Evolution Strategy, Hyperband, Efficient Neural Architecture Search, Differentiable Architecture Search und viele mehr. Weitere Informationen zu Jupyter Notebooks im Kontext von Kubeflow finden Sie im "offizielle Kubeflow-Dokumentation" .
NetApp ONTAP
ONTAP 9, die neueste Generation der Speicherverwaltungssoftware von NetApp, ermöglicht Unternehmen die Modernisierung ihrer Infrastruktur und den Übergang zu einem Cloud-fähigen Rechenzentrum. Durch die Nutzung branchenführender Datenverwaltungsfunktionen ermöglicht ONTAP die Verwaltung und den Schutz von Daten mit einem einzigen Satz von Tools, unabhängig davon, wo sich diese Daten befinden. Sie können Daten auch frei dorthin verschieben, wo sie benötigt werden: an den Rand, in den Kern oder in die Cloud. ONTAP 9 umfasst zahlreiche Funktionen, die die Datenverwaltung vereinfachen, kritische Daten beschleunigen und schützen und Infrastrukturfunktionen der nächsten Generation in Hybrid-Cloud-Architekturen ermöglichen.
Vereinfachen Sie die Datenverwaltung
Das Datenmanagement ist für den IT-Betrieb in Unternehmen und für Datenwissenschaftler von entscheidender Bedeutung, damit für KI-Anwendungen und das Training von KI/ML-Datensätzen die richtigen Ressourcen verwendet werden. Die folgenden zusätzlichen Informationen zu NetApp -Technologien fallen nicht in den Geltungsbereich dieser Validierung, können jedoch je nach Bereitstellung relevant sein.
Die ONTAP Datenmanagementsoftware umfasst die folgenden Funktionen zur Optimierung und Vereinfachung von Abläufen und zur Senkung Ihrer Gesamtbetriebskosten:
-
Inline-Datenkomprimierung und erweiterte Deduplizierung. Durch die Datenkomprimierung wird der verschwendete Speicherplatz in Speicherblöcken reduziert und durch die Deduplizierung wird die effektive Kapazität erheblich erhöht. Dies gilt für lokal gespeicherte Daten und für in der Cloud gespeicherte Daten.
-
Minimale, maximale und adaptive Dienstqualität (AQoS). Durch granulare Quality of Service (QoS)-Kontrollen wird die Aufrechterhaltung des Leistungsniveaus kritischer Anwendungen in Umgebungen mit hoher gemeinsamer Nutzung unterstützt.
-
NetApp FabricPool. Bietet automatisches Tiering von Cold Data für öffentliche und private Cloud-Speicheroptionen, einschließlich Amazon Web Services (AWS), Azure und der NetApp StorageGRID -Speicherlösung. Weitere Informationen zu FabricPool finden Sie unter "TR-4598: Best Practices für FabricPool" .
Beschleunigen und schützen Sie Daten
ONTAP bietet ein Höchstmaß an Leistung und Datenschutz und erweitert diese Funktionen auf folgende Weise:
-
Leistung und geringere Latenz. ONTAP bietet den höchstmöglichen Durchsatz bei der geringstmöglichen Latenz.
-
Datenschutz. ONTAP bietet integrierte Datenschutzfunktionen mit gemeinsamer Verwaltung auf allen Plattformen.
-
NetApp Volume Encryption (NVE). ONTAP bietet native Verschlüsselung auf Volume-Ebene mit Unterstützung für integriertes und externes Schlüsselmanagement.
-
Mandantenfähigkeit und Multifaktor-Authentifizierung. ONTAP ermöglicht die gemeinsame Nutzung von Infrastrukturressourcen mit höchster Sicherheit.
Zukunftssichere Infrastruktur
ONTAP unterstützt Sie mit den folgenden Funktionen bei der Erfüllung anspruchsvoller und sich ständig ändernder Geschäftsanforderungen:
-
Nahtlose Skalierung und unterbrechungsfreier Betrieb. ONTAP unterstützt die unterbrechungsfreie Kapazitätserweiterung bestehender Controller und Scale-Out-Cluster. Kunden können ohne kostspielige Datenmigrationen oder Ausfälle auf die neuesten Technologien upgraden.
-
Cloud-Verbindung. ONTAP ist die Speicherverwaltungssoftware mit der stärksten Cloud-Anbindung und bietet Optionen für softwaredefinierten Speicher und Cloud-native Instanzen in allen öffentlichen Clouds.
-
Integration mit neuen Anwendungen. ONTAP bietet Datendienste der Enterprise-Klasse für Plattformen und Anwendungen der nächsten Generation, wie etwa autonome Fahrzeuge, Smart Cities und Industrie 4.0, und nutzt dabei dieselbe Infrastruktur, die auch bestehende Unternehmens-Apps unterstützt.
NetApp Snapshot-Kopien
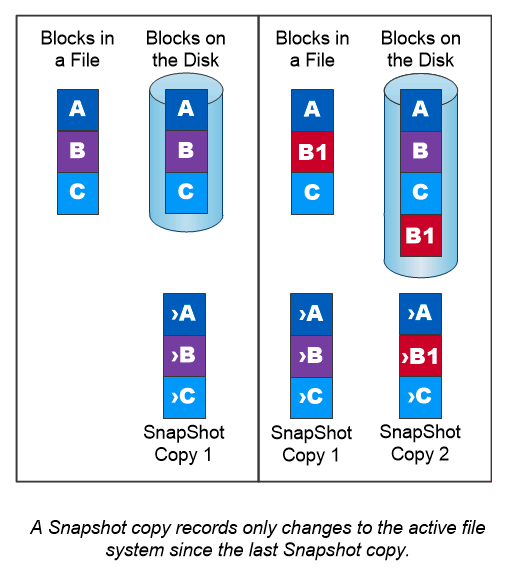
Eine NetApp Snapshot-Kopie ist ein schreibgeschütztes Point-in-Time-Image eines Volumes. Das Image verbraucht nur minimalen Speicherplatz und verursacht nur einen vernachlässigbaren Leistungsaufwand, da es nur Änderungen an Dateien aufzeichnet, die seit der letzten Snapshot-Kopie erstellt wurden, wie in der folgenden Abbildung dargestellt.
Ihre Effizienz verdanken Snapshot-Kopien der zentralen ONTAP Speichervirtualisierungstechnologie, dem Write Anywhere File Layout (WAFL). Wie eine Datenbank verwendet WAFL Metadaten, um auf tatsächliche Datenblöcke auf der Festplatte zu verweisen. Aber im Gegensatz zu einer Datenbank überschreibt WAFL keine vorhandenen Blöcke. Es schreibt aktualisierte Daten in einen neuen Block und ändert die Metadaten. Snapshot-Kopien sind deshalb so effizient, weil ONTAP beim Erstellen einer Snapshot-Kopie auf Metadaten verweist, anstatt Datenblöcke zu kopieren. Dadurch entfallen die Suchzeit, die bei anderen Systemen zum Auffinden der zu kopierenden Blöcke erforderlich ist, sowie die Kosten für die Erstellung der Kopie selbst.
Sie können eine Snapshot-Kopie verwenden, um einzelne Dateien oder LUNs wiederherzustellen oder den gesamten Inhalt eines Volumes wiederherzustellen. ONTAP vergleicht Zeigerinformationen in der Snapshot-Kopie mit Daten auf der Festplatte, um das fehlende oder beschädigte Objekt ohne Ausfallzeiten oder erhebliche Leistungseinbußen zu rekonstruieren.
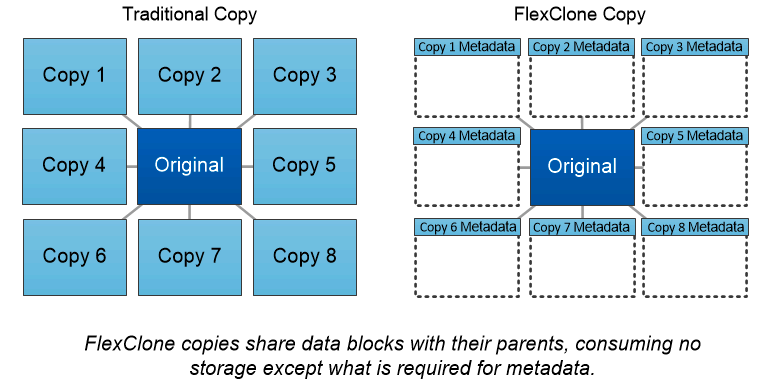
NetApp FlexClone -Technologie
Die NetApp FlexClone -Technologie referenziert Snapshot-Metadaten, um beschreibbare Point-in-Time-Kopien eines Volumes zu erstellen. Kopien teilen sich Datenblöcke mit ihren Eltern und verbrauchen keinen Speicherplatz außer dem, der für Metadaten benötigt wird, bis Änderungen in die Kopie geschrieben werden, wie in der folgenden Abbildung dargestellt. Während die Erstellung herkömmlicher Kopien Minuten oder sogar Stunden dauern kann, können Sie mit der FlexClone -Software selbst die größten Datensätze nahezu augenblicklich kopieren. Dadurch eignet es sich ideal für Situationen, in denen Sie mehrere Kopien identischer Datensätze (z. B. einen Entwicklungsarbeitsbereich) oder temporäre Kopien eines Datensatzes (Testen einer Anwendung anhand eines Produktionsdatensatzes) benötigen.
NetApp SnapMirror Datenreplikationstechnologie
Die NetApp SnapMirror -Software ist eine kostengünstige, benutzerfreundliche, einheitliche Replikationslösung für die gesamte Datenstruktur. Es repliziert Daten mit hoher Geschwindigkeit über LAN oder WAN. Es bietet Ihnen hohe Datenverfügbarkeit und schnelle Datenreplikation für Anwendungen aller Art, einschließlich geschäftskritischer Anwendungen in virtuellen und herkömmlichen Umgebungen. Wenn Sie Daten auf ein oder mehrere NetApp -Speichersysteme replizieren und die sekundären Daten kontinuierlich aktualisieren, bleiben Ihre Daten aktuell und stehen Ihnen jederzeit zur Verfügung. Es sind keine externen Replikationsserver erforderlich. In der folgenden Abbildung sehen Sie ein Beispiel für eine Architektur, die die SnapMirror -Technologie nutzt.
Die SnapMirror -Software nutzt die Speichereffizienz von NetApp ONTAP , indem sie nur geänderte Blöcke über das Netzwerk sendet. Die SnapMirror -Software verwendet außerdem eine integrierte Netzwerkkomprimierung, um die Datenübertragung zu beschleunigen und die Netzwerkbandbreitenauslastung um bis zu 70 % zu reduzieren. Mit der SnapMirror -Technologie können Sie einen Thin-Replication-Datenstrom nutzen, um ein einzelnes Repository zu erstellen, das sowohl den aktiven Spiegel als auch frühere Point-in-Time-Kopien verwaltet und so den Netzwerkverkehr um bis zu 50 % reduziert.
NetApp BlueXP Kopieren und Synchronisieren
"BlueXP Kopieren und Synchronisieren"ist ein NetApp -Dienst für die schnelle und sichere Datensynchronisierung. Unabhängig davon, ob Sie Dateien zwischen lokalen NFS- oder SMB-Dateifreigaben, NetApp StorageGRID, NetApp ONTAP S3, Google Cloud NetApp Volumes, Azure NetApp Files, AWS S3, AWS EFS, Azure Blob, Google Cloud Storage oder IBM Cloud Object Storage übertragen müssen, verschiebt BlueXP Copy and Sync die Dateien schnell und sicher dorthin, wo Sie sie benötigen.
Nachdem Ihre Daten übertragen wurden, stehen sie sowohl auf der Quelle als auch auf dem Ziel vollständig zur Verwendung zur Verfügung. BlueXP Copy and Sync kann Daten bei Bedarf synchronisieren, wenn ein Update ausgelöst wird, oder Daten kontinuierlich basierend auf einem vordefinierten Zeitplan synchronisieren. Unabhängig davon verschiebt BlueXP Copy and Sync nur die Deltas, sodass der Zeit- und Kostenaufwand für die Datenreplikation minimiert wird.
BlueXP Copy and Sync ist ein Software-as-a-Service-Tool (SaaS), das extrem einfach einzurichten und zu verwenden ist. Datenübertragungen, die durch BlueXP Copy and Sync ausgelöst werden, werden von Datenbrokern durchgeführt. BlueXP Copy and Sync-Datenbroker können in AWS, Azure, Google Cloud Platform oder vor Ort bereitgestellt werden.
NetApp XCP
"NetApp XCP"ist eine clientbasierte Software für Datenmigrationen von beliebigen zu NetApp und von NetApp zu NetApp sowie Einblicke in Dateisysteme. XCP ist auf Skalierbarkeit und maximale Leistung ausgelegt, indem alle verfügbaren Systemressourcen genutzt werden, um große Datensätze und leistungsstarke Migrationen zu verarbeiten. XCP hilft Ihnen, einen vollständigen Einblick in das Dateisystem zu erhalten und bietet die Möglichkeit, Berichte zu erstellen.
NetApp ONTAP FlexGroup Volumes
Ein Trainingsdatensatz kann eine Sammlung von potenziell Milliarden von Dateien sein. Dateien können Text, Audio, Video und andere Formen unstrukturierter Daten enthalten, die gespeichert und verarbeitet werden müssen, um parallel gelesen werden zu können. Das Speichersystem muss eine große Anzahl kleiner Dateien speichern und diese Dateien für sequenzielle und zufällige E/A-Vorgänge parallel lesen.
Ein FlexGroup -Volume ist ein einzelner Namespace, der aus mehreren Mitgliedsvolumes besteht, wie in der folgenden Abbildung dargestellt. Aus Sicht eines Speicheradministrators wird ein FlexGroup -Volume wie ein NetApp FlexVol volume verwaltet und verhält sich wie dieses. Dateien in einem FlexGroup -Volume werden einzelnen Mitgliedsvolumes zugewiesen und nicht über Volumes oder Knoten verteilt. Sie ermöglichen die folgenden Funktionen:
-
FlexGroup -Volumes bieten mehrere Petabyte an Kapazität und vorhersehbar niedrige Latenz für Workloads mit vielen Metadaten.
-
Sie unterstützen bis zu 400 Milliarden Dateien im selben Namespace.
-
Sie unterstützen parallelisierte Vorgänge in NAS-Workloads über CPUs, Knoten, Aggregate und einzelne FlexVol Volumes hinweg.
