

Open Source MLOps mit NetApp
 Änderungen vorschlagen
Änderungen vorschlagen
Mike Oglesby, NetApp Sufian Ahmad, NetApp Rick Huang, NetApp Mohan Acharya, NetApp
Unternehmen und Organisationen aller Größen und aus vielen Branchen setzen auf künstliche Intelligenz (KI), um reale Probleme zu lösen, innovative Produkte und Dienstleistungen anzubieten und sich auf einem zunehmend wettbewerbsorientierten Markt einen Vorteil zu verschaffen. Viele Organisationen greifen auf Open-Source-MLOps-Tools zurück, um mit dem rasanten Innovationstempo in der Branche Schritt zu halten. Diese Open-Source-Tools bieten erweiterte Funktionen und hochmoderne Features, berücksichtigen jedoch häufig nicht die Datenverfügbarkeit und Datensicherheit. Leider bedeutet dies, dass hochqualifizierte Datenwissenschaftler viel Zeit damit verbringen müssen, auf den Zugriff auf Daten zu warten oder auf die Fertigstellung grundlegender datenbezogener Vorgänge. Durch die Kombination beliebter Open-Source-MLOps-Tools mit einer intelligenten Dateninfrastruktur von NetApp können Unternehmen ihre Datenpipelines beschleunigen, was wiederum ihre KI-Initiativen beschleunigt. Sie können den Wert ihrer Daten erschließen und gleichzeitig sicherstellen, dass diese geschützt und sicher bleiben. Diese Lösung demonstriert die Kombination von NetApp Datenverwaltungsfunktionen mit mehreren gängigen Open-Source-Tools und -Frameworks, um diese Herausforderungen zu bewältigen.
Die folgende Liste hebt einige wichtige Funktionen hervor, die durch diese Lösung ermöglicht werden:
-
Benutzer können schnell neue Datenvolumes mit hoher Kapazität und Entwicklungsarbeitsbereiche bereitstellen, die durch leistungsstarken, skalierbaren NetApp Speicher unterstützt werden.
-
Benutzer können Datenvolumes und Entwicklungsarbeitsbereiche mit hoher Kapazität nahezu augenblicklich klonen, um Experimente oder schnelle Iterationen zu ermöglichen.
-
Benutzer können Snapshots von Datenvolumes mit hoher Kapazität und Entwicklungsarbeitsbereichen nahezu augenblicklich für Backups und/oder zur Rückverfolgbarkeit/Baselining speichern.
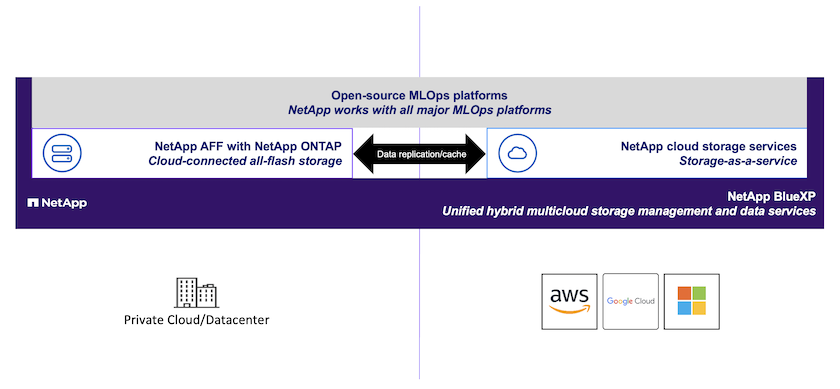
Ein typischer MLOps-Workflow umfasst Entwicklungsarbeitsbereiche, in der Regel in Form von"Jupyter-Notebooks" ; Experimentverfolgung; automatisierte Trainingspipelines; Datenpipelines; und Inferenz/Bereitstellung. Diese Lösung hebt mehrere verschiedene Tools und Frameworks hervor, die unabhängig oder zusammen verwendet werden können, um die verschiedenen Aspekte des Workflows zu berücksichtigen. Wir demonstrieren außerdem die Kombination der NetApp Datenverwaltungsfunktionen mit jedem dieser Tools. Diese Lösung soll Bausteine bieten, aus denen eine Organisation einen benutzerdefinierten MLOps-Workflow erstellen kann, der speziell auf ihre Anwendungsfälle und Anforderungen zugeschnitten ist.
Die folgenden Tools/Frameworks sind in dieser Lösung enthalten:
In der folgenden Liste werden gängige Muster für die unabhängige oder kombinierte Bereitstellung dieser Tools beschrieben.
-
Stellen Sie JupyterHub, MLflow und Apache Airflow gemeinsam bereit – JupyterHub für"Jupyter-Notebooks" , MLflow für die Experimentverfolgung und Apache Airflow für automatisiertes Training und Datenpipelines.
-
Stellen Sie Kubeflow und Apache Airflow gemeinsam bereit – Kubeflow für"Jupyter-Notebooks" , Experimentverfolgung, automatisierte Trainingspipelines und Inferenz; und Apache Airflow für Datenpipelines.
-
Stellen Sie Kubeflow als All-in-One-MLOps-Plattformlösung bereit für"Jupyter-Notebooks" , Experimentverfolgung, automatisiertes Training und Datenpipelines sowie Inferenz.