

Ausführen einer synchronen verteilten KI-Workload
 Änderungen vorschlagen
Änderungen vorschlagen
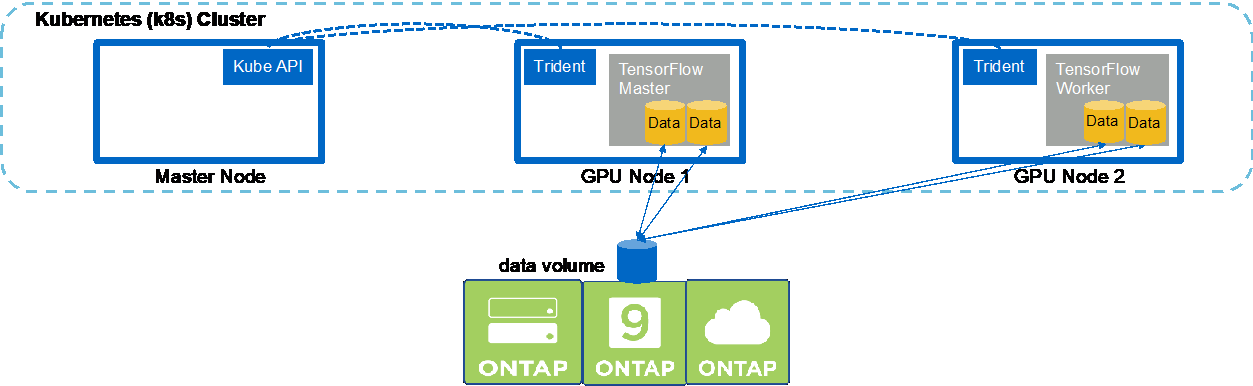
Um einen synchronen Multinode-KI- und ML-Job in Ihrem Kubernetes-Cluster auszuführen, führen Sie die folgenden Aufgaben auf dem Bereitstellungs-Jump-Host aus. Mit diesem Prozess können Sie die auf einem NetApp -Volume gespeicherten Daten nutzen und mehr GPUs verwenden, als ein einzelner Worker-Knoten bereitstellen kann. In der folgenden Abbildung sehen Sie eine Darstellung eines synchronen verteilten KI-Jobs.

|
Synchron verteilte Jobs können im Vergleich zu asynchron verteilten Jobs dazu beitragen, die Leistung und Trainingsgenauigkeit zu verbessern. Eine Diskussion der Vor- und Nachteile synchroner Jobs gegenüber asynchronen Jobs geht über den Rahmen dieses Dokuments hinaus. |
-
Die folgenden Beispielbefehle zeigen die Erstellung eines Workers, der an der synchronen verteilten Ausführung desselben TensorFlow-Benchmark-Jobs teilnimmt, der im Beispiel im Abschnitt auf einem einzelnen Knoten ausgeführt wurde."Ausführen einer Single-Node-KI-Workload" . In diesem speziellen Beispiel wird nur ein einziger Worker bereitgestellt, da der Job auf zwei Worker-Knoten ausgeführt wird.
Dieses Beispiel einer Worker-Bereitstellung erfordert acht GPUs und kann daher auf einem einzelnen GPU-Worker-Knoten ausgeführt werden, der über acht oder mehr GPUs verfügt. Wenn Ihre GPU-Workerknoten über mehr als acht GPUs verfügen, sollten Sie diese Zahl zur Leistungsmaximierung erhöhen, sodass sie der Anzahl der GPUs Ihrer Workerknoten entspricht. Weitere Informationen zu Kubernetes-Bereitstellungen finden Sie im "offizielle Kubernetes-Dokumentation" .
In diesem Beispiel wird eine Kubernetes-Bereitstellung erstellt, da dieser spezielle Container-Worker von alleine nie fertig werden würde. Daher ist es nicht sinnvoll, es mithilfe der Kubernetes-Jobkonstruktion bereitzustellen. Wenn Ihr Worker so konzipiert oder geschrieben ist, dass er die Aufgabe selbstständig erledigt, kann es sinnvoll sein, zum Bereitstellen Ihres Workers die Jobkonstruktion zu verwenden.
Der in dieser Beispiel-Bereitstellungsspezifikation angegebene Pod erhält eine
hostNetworkWert vontrue. Dieser Wert bedeutet, dass der Pod den Netzwerkstapel des Host-Workerknotens anstelle des virtuellen Netzwerkstapels verwendet, den Kubernetes normalerweise für jeden Pod erstellt. Diese Anmerkung wird in diesem Fall verwendet, da die spezifische Arbeitslast auf Open MPI, NCCL und Horovod angewiesen ist, um die Arbeitslast synchron und verteilt auszuführen. Daher ist Zugriff auf den Host-Netzwerkstapel erforderlich. Eine Diskussion über Open MPI, NCCL und Horovod geht über den Rahmen dieses Dokuments hinaus. Ob dieshostNetwork: trueOb eine Annotation erforderlich ist, hängt von den Anforderungen der spezifischen Arbeitslast ab, die Sie ausführen. Weitere Informationen zumhostNetworkFeld finden Sie im "offizielle Kubernetes-Dokumentation" .$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
Bestätigen Sie, dass die in Schritt 1 erstellte Worker-Bereitstellung erfolgreich gestartet wurde. Die folgenden Beispielbefehle bestätigen, dass ein einzelner Worker-Pod für die Bereitstellung erstellt wurde, wie in der Bereitstellungsdefinition angegeben, und dass dieser Pod derzeit auf einem der GPU-Worker-Knoten ausgeführt wird.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
Erstellen Sie einen Kubernetes-Job für einen Master, der den synchronen Multinode-Job startet, daran teilnimmt und seine Ausführung verfolgt. Die folgenden Beispielbefehle erstellen einen Master, der die synchrone verteilte Ausführung desselben TensorFlow-Benchmark-Jobs startet, daran teilnimmt und verfolgt, der im Beispiel im Abschnitt auf einem einzelnen Knoten ausgeführt wurde."Ausführen einer Single-Node-KI-Workload" .
Dieser beispielhafte Masterjob fordert acht GPUs an und kann daher auf einem einzelnen GPU-Workerknoten ausgeführt werden, der über acht oder mehr GPUs verfügt. Wenn Ihre GPU-Workerknoten über mehr als acht GPUs verfügen, sollten Sie diese Zahl zur Leistungsmaximierung erhöhen, sodass sie der Anzahl der GPUs Ihrer Workerknoten entspricht.
Der in dieser Beispiel-Jobdefinition angegebene Master-Pod erhält einen
hostNetworkWert vontrue, genau wie die Arbeiterkapsel einehostNetworkWert vontruein Schritt 1. Einzelheiten dazu, warum dieser Wert erforderlich ist, finden Sie in Schritt 1.$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
Bestätigen Sie, dass der in Schritt 3 erstellte Masterjob ordnungsgemäß ausgeführt wird. Der folgende Beispielbefehl bestätigt, dass für den Job ein einzelner Master-Pod erstellt wurde, wie in der Jobdefinition angegeben, und dass dieser Pod derzeit auf einem der GPU-Worker-Knoten ausgeführt wird. Sie sollten auch sehen, dass der Worker-Pod, den Sie ursprünglich in Schritt 1 gesehen haben, noch ausgeführt wird und dass die Master- und Worker-Pods auf verschiedenen Knoten ausgeführt werden.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
Bestätigen Sie, dass der in Schritt 3 erstellte Masterjob erfolgreich abgeschlossen wurde. Die folgenden Beispielbefehle bestätigen, dass der Auftrag erfolgreich abgeschlossen wurde.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
Löschen Sie die Worker-Bereitstellung, wenn Sie sie nicht mehr benötigen. Die folgenden Beispielbefehle zeigen das Löschen des in Schritt 1 erstellten Worker-Bereitstellungsobjekts.
Wenn Sie das Worker-Bereitstellungsobjekt löschen, löscht Kubernetes automatisch alle zugehörigen Worker-Pods.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
Optional: Bereinigen Sie die Master-Job-Artefakte. Die folgenden Beispielbefehle zeigen das Löschen des in Schritt 3 erstellten Master-Job-Objekts.
Wenn Sie das Master-Job-Objekt löschen, löscht Kubernetes automatisch alle zugehörigen Master-Pods.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.