

Vector-Datenbankschutz mit SnapCenter
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt wird beschrieben, wie Sie mit NetApp SnapCenter Datenschutz für die Vektordatenbank bereitstellen.
Vector-Datenbankschutz mit NetApp SnapCenter.
In der Filmproduktionsbranche beispielsweise verfügen Kunden häufig über kritische eingebettete Daten wie Video- und Audiodateien. Der Verlust dieser Daten aufgrund von Problemen wie Festplattenausfällen kann erhebliche Auswirkungen auf den Betrieb haben und möglicherweise Multimillionen-Dollar-Projekte gefährden. Wir sind auf Fälle gestoßen, in denen wertvolle Inhalte verloren gingen, was zu erheblichen Störungen und finanziellen Verlusten führte. Die Gewährleistung der Sicherheit und Integrität dieser wichtigen Daten ist daher in dieser Branche von größter Bedeutung. In diesem Abschnitt gehen wir näher darauf ein, wie SnapCenter die in ONTAP gespeicherten Vektordatenbankdaten und Milvus-Daten schützt. Für dieses Beispiel haben wir einen NAS-Bucket (milvusdbvol1) verwendet, der von einem NFS ONTAP Volume (vol1) für Kundendaten abgeleitet wurde, und ein separates NFS-Volume (vectordbpv) für Milvus-Cluster-Konfigurationsdaten. Bitte überprüfen Sie die"hier," für den Snapcenter-Backup-Workflow
-
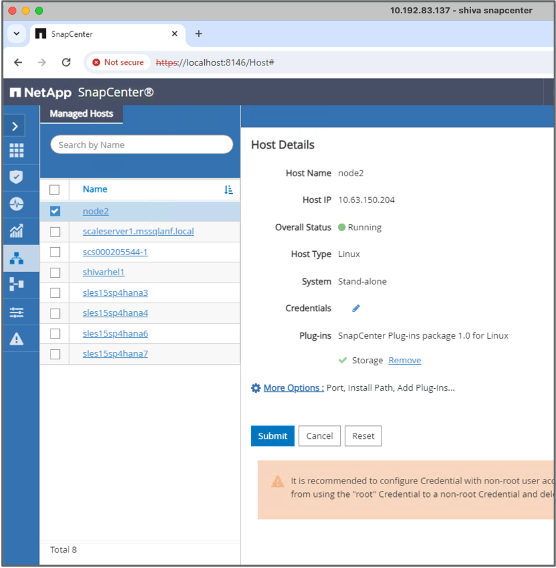
Richten Sie den Host ein, der zum Ausführen von SnapCenter -Befehlen verwendet wird.
-
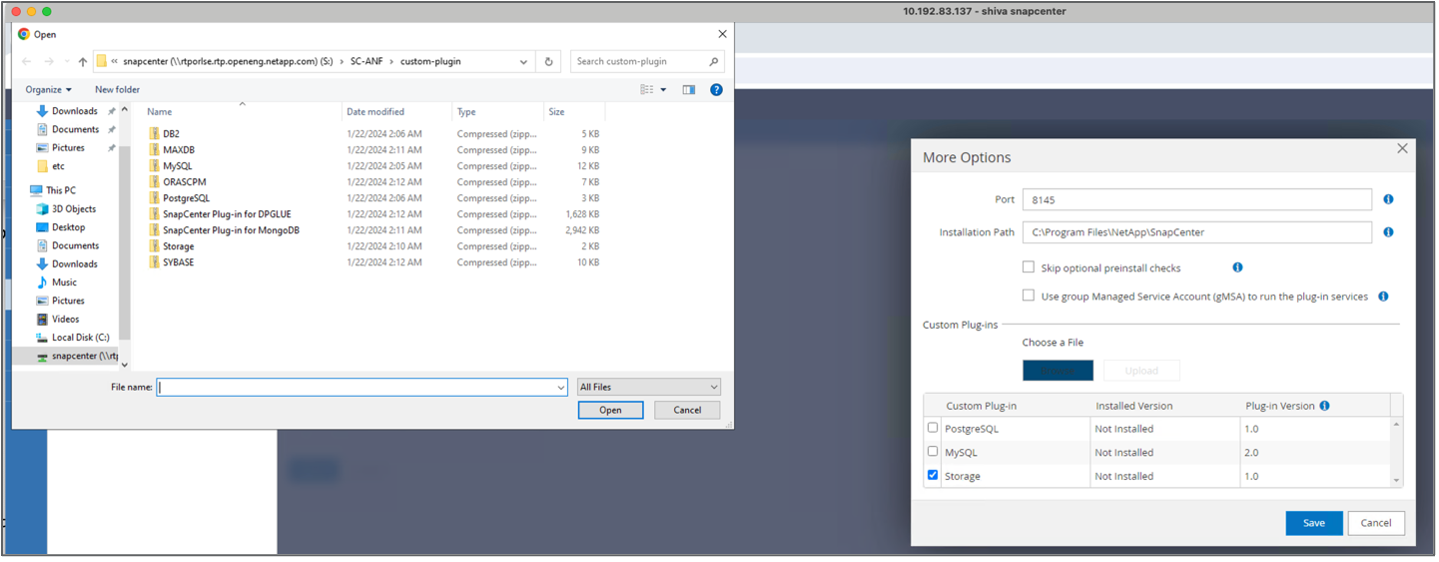
Installieren und konfigurieren Sie das Speicher-Plugin. Wählen Sie beim hinzugefügten Host „Weitere Optionen“ aus. Navigieren Sie zum heruntergeladenen Speicher-Plugin und wählen Sie es aus dem"NetApp Automation Store" . Installieren Sie das Plugin und speichern Sie die Konfiguration.
-
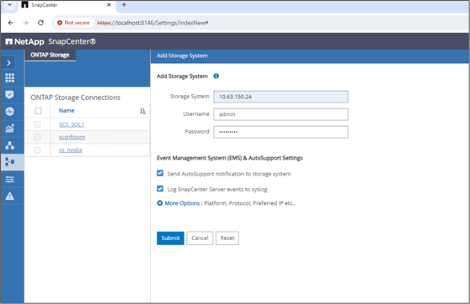
Richten Sie das Speichersystem und das Volume ein: Fügen Sie unter „Speichersystem“ das Speichersystem hinzu und wählen Sie die SVM (Storage Virtual Machine) aus. In diesem Beispiel haben wir „vs_nvidia“ gewählt.
-
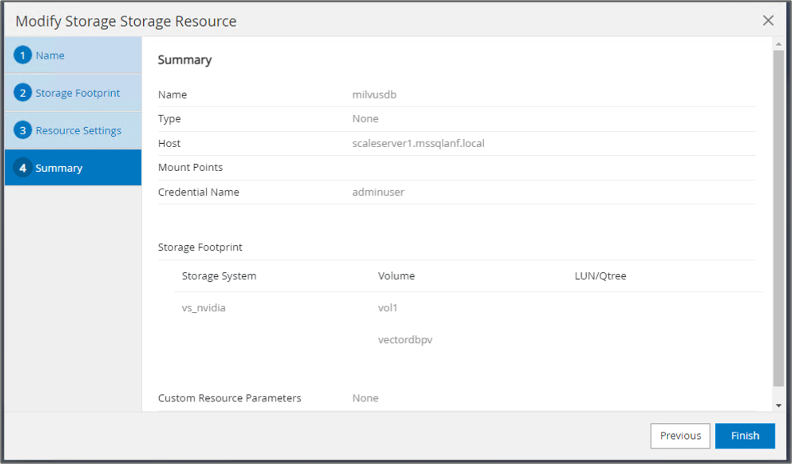
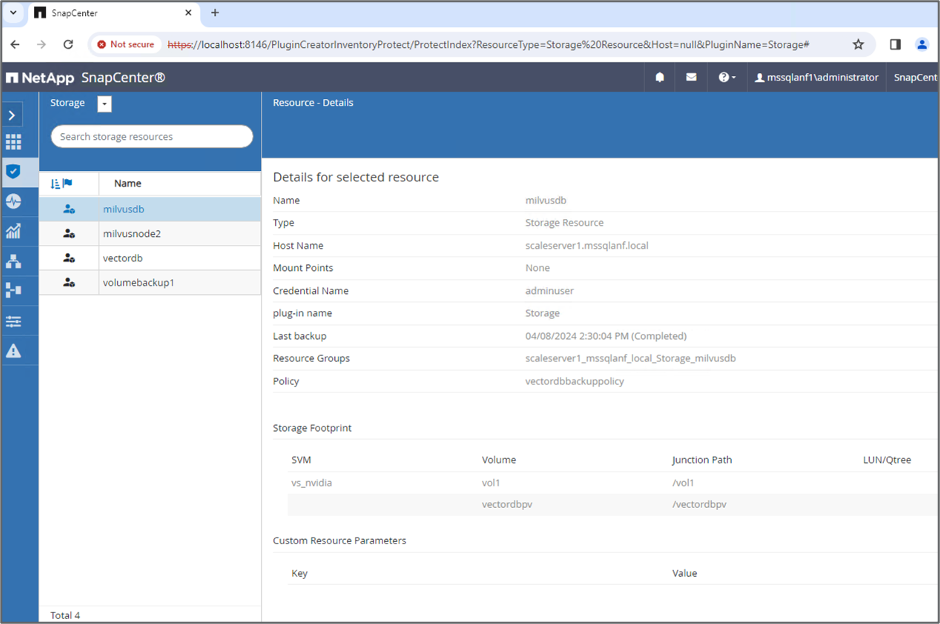
Richten Sie eine Ressource für die Vektordatenbank ein, die eine Sicherungsrichtlinie und einen benutzerdefinierten Snapshot-Namen enthält.
-
Aktivieren Sie die Konsistenzgruppensicherung mit Standardwerten und aktivieren Sie SnapCenter ohne Dateisystemkonsistenz.
-
Wählen Sie im Abschnitt „Speicherbedarf“ die Volumes aus, die mit den Kundendaten der Vektordatenbank und den Milvus-Clusterdaten verknüpft sind. In unserem Beispiel sind dies „vol1“ und „vectordbpv“.
-
Erstellen Sie eine Richtlinie zum Schutz der Vektordatenbank und schützen Sie die Vektordatenbankressource mithilfe der Richtlinie.
-
-
Fügen Sie mithilfe eines Python-Skripts Daten in den S3 NAS-Bucket ein. In unserem Fall haben wir das von Milvus bereitgestellte Sicherungsskript „prepare_data_netapp.py“ geändert und den Befehl „sync“ ausgeführt, um die Daten aus dem Betriebssystem zu löschen.
root@node2:~# python3 prepare_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_test exist in Milvus: False === Create collection `hello_milvus_netapp_sc_test` === === Start inserting entities === Number of entities in hello_milvus_netapp_sc_test: 3000 === Create collection `hello_milvus_netapp_sc_test2` === Number of entities in hello_milvus_netapp_sc_test2: 6000 root@node2:~# for i in 2 3 4 5 6 ; do ssh node$i "hostname; sync; echo 'sync executed';" ; done node2 sync executed node3 sync executed node4 sync executed node5 sync executed node6 sync executed root@node2:~# -
Überprüfen Sie die Daten im S3 NAS-Bucket. In unserem Beispiel wurden die Dateien mit dem Zeitstempel „2024-04-08 21:22“ vom Skript „prepare_data_netapp.py“ erstellt.
root@node2:~# aws s3 ls --profile ontaps3 s3://milvusdbvol1/ --recursive | grep '2024-04-08' <output content removed to save page space> 2024-04-08 21:18:14 5656 stats_log/448950615991000809/448950615991000810/448950615991001854/100/1 2024-04-08 21:18:12 5654 stats_log/448950615991000809/448950615991000810/448950615991001854/100/448950615990800869 2024-04-08 21:18:17 5656 stats_log/448950615991000809/448950615991000810/448950615991001872/100/1 2024-04-08 21:18:15 5654 stats_log/448950615991000809/448950615991000810/448950615991001872/100/448950615990800876 2024-04-08 21:22:46 5625 stats_log/448950615991003377/448950615991003378/448950615991003385/100/1 2024-04-08 21:22:45 5623 stats_log/448950615991003377/448950615991003378/448950615991003385/100/448950615990800899 2024-04-08 21:22:49 5656 stats_log/448950615991003408/448950615991003409/448950615991003416/100/1 2024-04-08 21:22:47 5654 stats_log/448950615991003408/448950615991003409/448950615991003416/100/448950615990800906 2024-04-08 21:22:52 5656 stats_log/448950615991003408/448950615991003409/448950615991003434/100/1 2024-04-08 21:22:50 5654 stats_log/448950615991003408/448950615991003409/448950615991003434/100/448950615990800913 root@node2:~# -
Starten Sie eine Sicherung mithilfe des Consistency Group (CG)-Snapshots aus der Ressource „milvusdb“.
-
Um die Sicherungsfunktionalität zu testen, haben wir nach dem Sicherungsvorgang entweder eine neue Tabelle hinzugefügt oder einige Daten aus dem NFS (S3 NAS-Bucket) entfernt.
Stellen Sie sich für diesen Test ein Szenario vor, in dem jemand nach der Sicherung eine neue, unnötige oder unangemessene Sammlung erstellt hat. In einem solchen Fall müssten wir die Vektordatenbank auf den Zustand vor dem Hinzufügen der neuen Sammlung zurücksetzen. Beispielsweise wurden neue Sammlungen wie „hello_milvus_netapp_sc_testnew“ und „hello_milvus_netapp_sc_testnew2“ eingefügt.
root@node2:~# python3 prepare_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_testnew exist in Milvus: False === Create collection `hello_milvus_netapp_sc_testnew` === === Start inserting entities === Number of entities in hello_milvus_netapp_sc_testnew: 3000 === Create collection `hello_milvus_netapp_sc_testnew2` === Number of entities in hello_milvus_netapp_sc_testnew2: 6000 root@node2:~# -
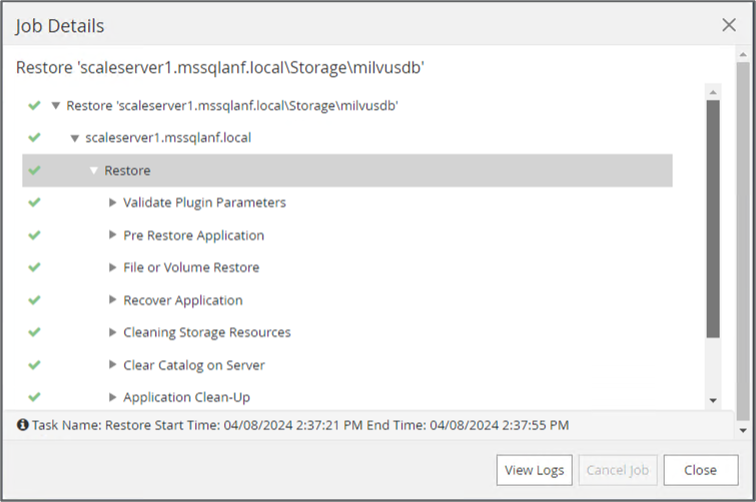
Führen Sie eine vollständige Wiederherstellung des S3 NAS-Buckets aus dem vorherigen Snapshot durch.
-
Verwenden Sie ein Python-Skript, um die Daten aus den Sammlungen „hello_milvus_netapp_sc_test“ und „hello_milvus_netapp_sc_test2“ zu überprüfen.
root@node2:~# python3 verify_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_test exist in Milvus: True {'auto_id': False, 'description': 'hello_milvus_netapp_sc_test', 'fields': [{'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': False}, {'name': 'random', 'description': '', 'type': <DataType.DOUBLE: 11>}, {'name': 'var', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}, {'name': 'embeddings', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 8}}]} Number of entities in Milvus: hello_milvus_netapp_sc_test : 3000 === Start Creating index IVF_FLAT === === Start loading === === Start searching based on vector similarity === hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911 hit: id: 1262, distance: 0.08883658051490784, entity: {'random': 0.2978858685751561}, random field: 0.2978858685751561 hit: id: 1265, distance: 0.09590047597885132, entity: {'random': 0.3042039939240304}, random field: 0.3042039939240304 hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482 hit: id: 1580, distance: 0.05628091096878052, entity: {'random': 0.3855988746044062}, random field: 0.3855988746044062 hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368 search latency = 0.2832s === Start querying with `random > 0.5` === query result: -{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': 0} search latency = 0.2257s === Start hybrid searching with `random > 0.5` === hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911 hit: id: 747, distance: 0.14606499671936035, entity: {'random': 0.5648774800635661}, random field: 0.5648774800635661 hit: id: 2527, distance: 0.1530652642250061, entity: {'random': 0.8928974315571507}, random field: 0.8928974315571507 hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368 hit: id: 2034, distance: 0.20354536175727844, entity: {'random': 0.5526117606328499}, random field: 0.5526117606328499 hit: id: 958, distance: 0.21908017992973328, entity: {'random': 0.6647383716417955}, random field: 0.6647383716417955 search latency = 0.5480s Does collection hello_milvus_netapp_sc_test2 exist in Milvus: True {'auto_id': True, 'description': 'hello_milvus_netapp_sc_test2', 'fields': [{'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'random', 'description': '', 'type': <DataType.DOUBLE: 11>}, {'name': 'var', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}, {'name': 'embeddings', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 8}}]} Number of entities in Milvus: hello_milvus_netapp_sc_test2 : 6000 === Start Creating index IVF_FLAT === === Start loading === === Start searching based on vector similarity === hit: id: 448950615990642008, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990645009, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990640618, distance: 0.13562293350696564, entity: {'random': 0.7864676926688837}, random field: 0.7864676926688837 hit: id: 448950615990642314, distance: 0.10414951294660568, entity: {'random': 0.2209597460821181}, random field: 0.2209597460821181 hit: id: 448950615990645315, distance: 0.10414951294660568, entity: {'random': 0.2209597460821181}, random field: 0.2209597460821181 hit: id: 448950615990640004, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 search latency = 0.2381s === Start querying with `random > 0.5` === query result: -{'embeddings': [0.15983285, 0.72214717, 0.7414838, 0.44471496, 0.50356466, 0.8750043, 0.316556, 0.7871702], 'pk': 448950615990639798, 'random': 0.7820620141382767} search latency = 0.3106s === Start hybrid searching with `random > 0.5` === hit: id: 448950615990642008, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990645009, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990640618, distance: 0.13562293350696564, entity: {'random': 0.7864676926688837}, random field: 0.7864676926688837 hit: id: 448950615990640004, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 hit: id: 448950615990643005, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 hit: id: 448950615990640402, distance: 0.13665105402469635, entity: {'random': 0.9742541034109935}, random field: 0.9742541034109935 search latency = 0.4906s root@node2:~# -
Stellen Sie sicher, dass die unnötige oder unangemessene Sammlung nicht mehr in der Datenbank vorhanden ist.
root@node2:~# python3 verify_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_testnew exist in Milvus: False Traceback (most recent call last): File "/root/verify_data_netapp.py", line 37, in <module> recover_collection = Collection(recover_collection_name) File "/usr/local/lib/python3.10/dist-packages/pymilvus/orm/collection.py", line 137, in __init__ raise SchemaNotReadyException( pymilvus.exceptions.SchemaNotReadyException: <SchemaNotReadyException: (code=1, message=Collection 'hello_milvus_netapp_sc_testnew' not exist, or you can pass in schema to create one.)> root@node2:~#
Zusammenfassend lässt sich sagen, dass die Verwendung von NetApp SnapCenter zum Schutz von Vektordatenbankdaten und Milvus-Daten in ONTAP den Kunden erhebliche Vorteile bietet, insbesondere in Branchen, in denen die Datenintegrität von größter Bedeutung ist, wie beispielsweise in der Filmproduktion. Die Fähigkeit von SnapCenter, konsistente Backups zu erstellen und vollständige Datenwiederherstellungen durchzuführen, stellt sicher, dass kritische Daten wie eingebettete Video- und Audiodateien vor Verlust durch Festplattenausfälle oder andere Probleme geschützt sind. Dadurch werden nicht nur Betriebsstörungen vermieden, sondern auch erhebliche finanzielle Verluste vermieden.
In diesem Abschnitt haben wir gezeigt, wie SnapCenter zum Schutz von in ONTAP gespeicherten Daten konfiguriert werden kann, einschließlich der Einrichtung von Hosts, der Installation und Konfiguration von Speicher-Plugins und der Erstellung einer Ressource für die Vektordatenbank mit einem benutzerdefinierten Snapshot-Namen. Wir haben auch gezeigt, wie man mithilfe des Consistency Group-Snapshots ein Backup durchführt und die Daten im S3 NAS-Bucket überprüft.
Darüber hinaus haben wir ein Szenario simuliert, in dem nach der Sicherung eine unnötige oder unangemessene Sammlung erstellt wurde. In solchen Fällen stellt die Fähigkeit von SnapCenter, eine vollständige Wiederherstellung von einem vorherigen Snapshot durchzuführen, sicher, dass die Vektordatenbank in den Zustand vor dem Hinzufügen der neuen Sammlung zurückgesetzt werden kann, wodurch die Integrität der Datenbank gewahrt bleibt. Diese Möglichkeit, Daten zu einem bestimmten Zeitpunkt wiederherzustellen, ist für Kunden von unschätzbarem Wert, da sie ihnen die Gewissheit gibt, dass ihre Daten nicht nur sicher, sondern auch ordnungsgemäß verwaltet werden. Somit bietet das SnapCenter -Produkt von NetApp Kunden eine robuste und zuverlässige Lösung für Datenschutz und -verwaltung.