

Vektordatenbank
 Änderungen vorschlagen
Änderungen vorschlagen
Dieser Abschnitt behandelt die Definition und Verwendung einer Vektordatenbank in NetApp KI-Lösungen.
Vektordatenbank
Eine Vektordatenbank ist ein spezialisierter Datenbanktyp, der für die Verarbeitung, Indizierung und Suche unstrukturierter Daten mithilfe von Einbettungen aus Modellen des maschinellen Lernens konzipiert ist. Anstatt Daten in einem herkömmlichen Tabellenformat zu organisieren, werden sie als hochdimensionale Vektoren angeordnet, die auch als Vektoreinbettungen bezeichnet werden. Diese einzigartige Struktur ermöglicht es der Datenbank, komplexe, mehrdimensionale Daten effizienter und genauer zu verarbeiten.
Eine der wichtigsten Fähigkeiten einer Vektordatenbank ist die Verwendung generativer KI zur Durchführung von Analysen. Hierzu gehören Ähnlichkeitssuchen, bei denen die Datenbank Datenpunkte identifiziert, die einer bestimmten Eingabe ähneln, und die Anomalieerkennung, bei der sie Datenpunkte erkennen kann, die erheblich von der Norm abweichen.
Darüber hinaus eignen sich Vektordatenbanken gut für die Verarbeitung zeitlicher Daten oder mit Zeitstempeln versehener Daten. Diese Art von Daten liefert Informationen darüber, „was“ passiert ist und wann es passiert ist, in der Reihenfolge und im Verhältnis zu allen anderen Ereignissen innerhalb eines bestimmten IT-Systems. Diese Fähigkeit, zeitliche Daten zu verarbeiten und zu analysieren, macht Vektordatenbanken besonders nützlich für Anwendungen, die ein Verständnis von Ereignissen im Zeitverlauf erfordern.
Vorteile der Vektordatenbank für ML und KI:
-
Hochdimensionale Suche: Vektordatenbanken eignen sich hervorragend zum Verwalten und Abrufen hochdimensionaler Daten, die häufig in KI- und ML-Anwendungen generiert werden.
-
Skalierbarkeit: Sie können effizient skaliert werden, um große Datenmengen zu verarbeiten und so das Wachstum und die Expansion von KI- und ML-Projekten zu unterstützen.
-
Flexibilität: Vektordatenbanken bieten ein hohes Maß an Flexibilität und ermöglichen die Aufnahme unterschiedlicher Datentypen und -strukturen.
-
Leistung: Sie bieten leistungsstarkes Datenmanagement und -abruf, was für die Geschwindigkeit und Effizienz von KI- und ML-Operationen entscheidend ist.
-
Anpassbare Indizierung: Vector-Datenbanken bieten anpassbare Indizierungsoptionen, die eine optimierte Datenorganisation und -abfrage basierend auf spezifischen Anforderungen ermöglichen.
Vektordatenbanken und Anwendungsfälle.
Dieser Abschnitt enthält verschiedene Vektordatenbanken und Einzelheiten zu ihren Anwendungsfällen.
Faiss und ScaNN
Es handelt sich um Bibliotheken, die als wichtige Werkzeuge im Bereich der Vektorsuche dienen. Diese Bibliotheken bieten Funktionen, die für die Verwaltung und Suche in Vektordaten von entscheidender Bedeutung sind, und stellen somit unschätzbare Ressourcen in diesem speziellen Bereich der Datenverwaltung dar.
Elasticsearch
Es handelt sich um eine weit verbreitete Such- und Analyse-Engine, die seit kurzem auch über eine Vektorsuchfunktion verfügt. Diese neue Funktion erweitert die Funktionalität und ermöglicht eine effektivere Verarbeitung und Suche in Vektordaten.
Tannenzapfen
Es handelt sich um eine robuste Vektordatenbank mit einem einzigartigen Funktionsumfang. Es unterstützt in seiner Indexierungsfunktionalität sowohl dichte als auch spärliche Vektoren, was seine Flexibilität und Anpassungsfähigkeit verbessert. Eine seiner Hauptstärken liegt in der Fähigkeit, traditionelle Suchmethoden mit KI-basierter dichter Vektorsuche zu kombinieren und so einen hybriden Suchansatz zu schaffen, der das Beste aus beiden Welten nutzt.
Pinecone ist hauptsächlich cloudbasiert, für Anwendungen des maschinellen Lernens konzipiert und lässt sich gut in eine Vielzahl von Plattformen integrieren, darunter GCP, AWS, Open AI, GPT-3, GPT-3.5, GPT-4, Catgut Plus, Elasticsearch, Haystack und mehr. Es ist wichtig zu beachten, dass Pinecone eine Closed-Source-Plattform ist und als Software-as-a-Service-Angebot (SaaS) verfügbar ist.
Aufgrund seiner erweiterten Funktionen eignet sich Pinecone besonders gut für die Cybersicherheitsbranche, wo seine hochdimensionalen Such- und Hybridsuchfunktionen effektiv genutzt werden können, um Bedrohungen zu erkennen und darauf zu reagieren.
Chroma
Es handelt sich um eine Vektordatenbank mit einer Core-API mit vier Hauptfunktionen, von denen eine einen In-Memory-Dokumentenvektorspeicher umfasst. Es nutzt außerdem die Face Transformers-Bibliothek zum Vektorisieren von Dokumenten und verbessert so seine Funktionalität und Vielseitigkeit. Chroma ist für den Betrieb sowohl in der Cloud als auch vor Ort konzipiert und bietet Flexibilität basierend auf den Benutzeranforderungen. Es zeichnet sich insbesondere bei Audioanwendungen aus und ist daher eine ausgezeichnete Wahl für audiobasierte Suchmaschinen, Musikempfehlungssysteme und andere audiobezogene Anwendungsfälle.
Weaviate
Es handelt sich um eine vielseitige Vektordatenbank, die es Benutzern ermöglicht, ihre Inhalte entweder mithilfe der integrierten oder benutzerdefinierten Module zu vektorisieren und so Flexibilität basierend auf spezifischen Anforderungen zu bieten. Es bietet sowohl vollständig verwaltete als auch selbst gehostete Lösungen und berücksichtigt dabei eine Vielzahl von Bereitstellungspräferenzen.
Eine der Hauptfunktionen von Weaviate ist die Fähigkeit, sowohl Vektoren als auch Objekte zu speichern, wodurch die Datenverarbeitungsfunktionen verbessert werden. Es wird häufig für eine Reihe von Anwendungen verwendet, darunter semantische Suche und Datenklassifizierung in ERP-Systemen. Im E-Commerce-Sektor treibt es Such- und Empfehlungsmaschinen an. Weaviate wird auch für die Bildsuche, Anomalieerkennung, automatisierte Datenharmonisierung und Cybersicherheitsbedrohungsanalyse verwendet und zeigt damit seine Vielseitigkeit in mehreren Bereichen.
Redis
Redis ist eine leistungsstarke Vektordatenbank, die für ihre schnelle In-Memory-Speicherung bekannt ist und eine geringe Latenz für Lese-/Schreibvorgänge bietet. Dies macht es zu einer ausgezeichneten Wahl für Empfehlungssysteme, Suchmaschinen und Datenanalyseanwendungen, die einen schnellen Datenzugriff erfordern.
Redis unterstützt verschiedene Datenstrukturen für Vektoren, einschließlich Listen, Mengen und sortierte Mengen. Es bietet auch Vektoroperationen wie das Berechnen von Abständen zwischen Vektoren oder das Finden von Schnittpunkten und Vereinigungen. Diese Funktionen sind besonders nützlich für die Ähnlichkeitssuche, Clustering und inhaltsbasierte Empfehlungssysteme.
In Bezug auf Skalierbarkeit und Verfügbarkeit zeichnet sich Redis durch die Verarbeitung von Workloads mit hohem Durchsatz aus und bietet Datenreplikation. Es lässt sich auch gut in andere Datentypen integrieren, einschließlich herkömmlicher relationaler Datenbanken (RDBMS). Redis enthält eine Publish/Subscribe-Funktion (Pub/Sub) für Echtzeit-Updates, die für die Verwaltung von Echtzeit-Vektoren von Vorteil ist. Darüber hinaus ist Redis leichtgewichtig und einfach zu verwenden, was es zu einer benutzerfreundlichen Lösung für die Verwaltung von Vektordaten macht.
Milvus
Es handelt sich um eine vielseitige Vektordatenbank, die eine API wie einen Dokumentenspeicher bietet, ähnlich wie MongoDB. Es zeichnet sich durch die Unterstützung einer Vielzahl von Datentypen aus und ist daher eine beliebte Wahl in den Bereichen Datenwissenschaft und maschinelles Lernen.
Eine der einzigartigen Funktionen von Milvus ist die Multivektorisierungsfunktion, die es Benutzern ermöglicht, zur Laufzeit den für die Suche zu verwendenden Vektortyp anzugeben. Darüber hinaus nutzt es Knowwhere, eine Bibliothek, die auf anderen Bibliotheken wie Faiss aufbaut, um die Kommunikation zwischen Abfragen und den Vektorsuchalgorithmen zu verwalten.
Dank seiner Kompatibilität mit PyTorch und TensorFlow bietet Milvus außerdem eine nahtlose Integration in Machine-Learning-Workflows. Dies macht es zu einem hervorragenden Tool für eine Reihe von Anwendungen, darunter E-Commerce, Bild- und Videoanalyse, Objekterkennung, Bildähnlichkeitssuche und inhaltsbasierte Bildabfrage. Im Bereich der natürlichen Sprachverarbeitung wird Milvus für die Dokumentenclusterung, semantische Suche und Frage-Antwort-Systeme verwendet.
Für diese Lösung haben wir Milvus zur Lösungsvalidierung ausgewählt. Aus Leistungsgründen haben wir sowohl Milvus als auch Postgres (pgvecto.rs) verwendet.
Warum haben wir uns für diese Lösung für Milvus entschieden?
-
Open Source: Milvus ist eine Open-Source-Vektordatenbank, die eine von der Community gesteuerte Entwicklung und Verbesserung fördert.
-
KI-Integration: Es nutzt die Einbettung von Ähnlichkeitssuchen und KI-Anwendungen, um die Funktionalität der Vektordatenbank zu verbessern.
-
Handhabung großer Datenmengen: Milvus verfügt über die Kapazität, über eine Milliarde Einbettungsvektoren zu speichern, zu indizieren und zu verwalten, die von Deep Neural Networks (DNN) und Machine Learning (ML)-Modellen generiert werden.
-
Benutzerfreundlich: Die Verwendung ist einfach, die Einrichtung dauert weniger als eine Minute. Milvus bietet auch SDKs für verschiedene Programmiersprachen an.
-
Geschwindigkeit: Es bietet blitzschnelle Abrufgeschwindigkeiten, bis zu 10-mal schneller als einige Alternativen.
-
Skalierbarkeit und Verfügbarkeit: Milvus ist hochgradig skalierbar und bietet Optionen zur Skalierung nach oben und unten nach Bedarf.
-
Funktionsreich: Es unterstützt verschiedene Datentypen, Attributfilterung, benutzerdefinierte Funktionen (UDF), konfigurierbare Konsistenzstufen und Reisezeiten und ist somit ein vielseitiges Tool für verschiedene Anwendungen.
Milvus-Architekturübersicht
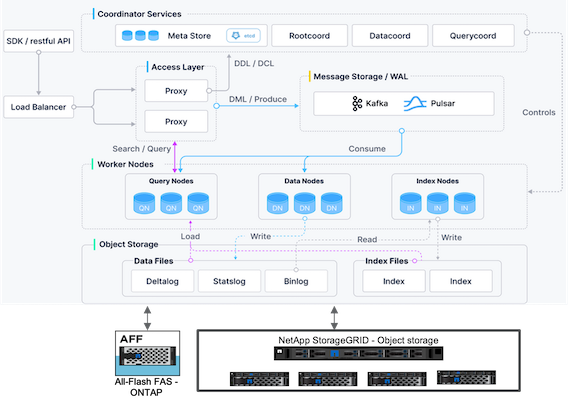
Dieser Abschnitt stellt Komponenten und Dienste höherer Ebene bereit, die in der Milvus-Architektur verwendet werden. * Zugriffsebene – Sie besteht aus einer Gruppe zustandsloser Proxys und dient als Frontebene des Systems und Endpunkt für Benutzer. * Koordinatordienst – er weist die Aufgaben den Arbeitsknoten zu und fungiert als Gehirn des Systems. Es gibt drei Koordinatortypen: Stammkoordinate, Datenkoordinate und Abfragekoordinate. * Worker-Knoten: Es folgt den Anweisungen des Koordinatordienstes und führt vom Benutzer ausgelöste DML/DDL-Befehle aus. Es gibt drei Arten von Worker-Knoten, nämlich Abfrageknoten, Datenknoten und Indexknoten. * Speicher: Er ist für die Datenpersistenz verantwortlich. Es umfasst Metaspeicher, Log Broker und Objektspeicher. NetApp Speicher wie ONTAP und StorageGRID bieten Milvus Objektspeicher und dateibasierten Speicher sowohl für Kundendaten als auch für Vektordatenbankdaten.