

DR mit BlueXP DRaaS für VMFS-Datenspeicher
 Änderungen vorschlagen
Änderungen vorschlagen
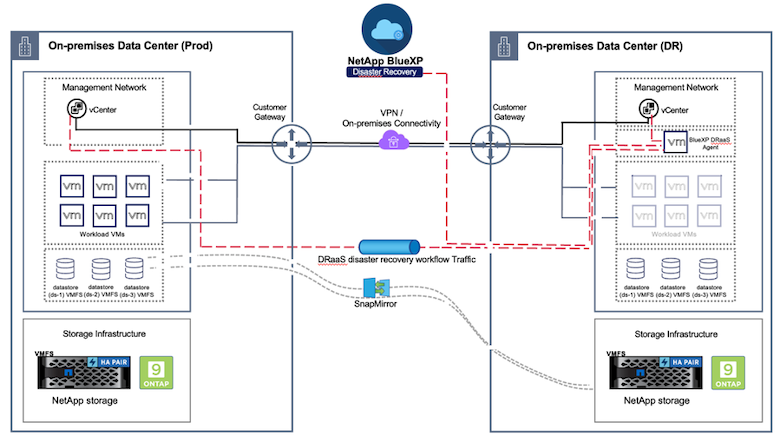
Die Notfallwiederherstellung mithilfe der Blockebenenreplikation vom Produktionsstandort zum Notfallwiederherstellungsstandort ist eine robuste und kostengünstige Möglichkeit, die Workloads vor Standortausfällen und Datenbeschädigungen wie Ransomware-Angriffen zu schützen. Mit der NetApp SnapMirror Replikation können VMware-Workloads, die auf lokalen ONTAP -Systemen mit VMFS-Datenspeicher ausgeführt werden, auf ein anderes ONTAP Speichersystem in einem dafür vorgesehenen Wiederherstellungs-Rechenzentrum repliziert werden, in dem sich VMware befindet.
In diesem Abschnitt des Dokuments wird die Konfiguration von BlueXP DRaaS zum Einrichten der Notfallwiederherstellung für lokale VMware-VMs an einem anderen bestimmten Standort beschrieben. Als Teil dieser Einrichtung werden das BlueXP -Konto, der BlueXP Connector und die ONTAP Arrays im BlueXP Arbeitsbereich hinzugefügt, die für die Kommunikation von VMware vCenter mit dem ONTAP Speicher erforderlich sind. Darüber hinaus wird in diesem Dokument detailliert beschrieben, wie die Replikation zwischen Standorten konfiguriert wird und wie ein Wiederherstellungsplan eingerichtet und getestet wird. Der letzte Abschnitt enthält Anweisungen zum Durchführen eines vollständigen Site-Failovers und zum Failback, wenn die primäre Site wiederhergestellt und online gestellt wurde.
Mithilfe des BlueXP disaster recovery -Dienstes, der in die NetApp BlueXP Konsole integriert ist, können Kunden ihre lokalen VMware vCenter zusammen mit ONTAP Speicher ermitteln, Ressourcengruppierungen erstellen, einen Disaster-Recovery-Plan erstellen, ihn mit Ressourcengruppen verknüpfen und Failover und Failback testen oder ausführen. SnapMirror bietet Blockreplikation auf Speicherebene, um die beiden Sites mit inkrementellen Änderungen auf dem neuesten Stand zu halten, was zu einem RPO von bis zu 5 Minuten führt. Darüber hinaus ist es möglich, DR-Verfahren als reguläre Übung zu simulieren, ohne die Produktion und die replizierten Datenspeicher zu beeinträchtigen oder zusätzliche Speicherkosten zu verursachen. Die BlueXP disaster recovery nutzt die FlexClone -Technologie von ONTAP, um eine platzsparende Kopie des VMFS-Datenspeichers aus dem letzten replizierten Snapshot auf der DR-Site zu erstellen. Sobald der DR-Test abgeschlossen ist, können Kunden die Testumgebung einfach löschen, wiederum ohne Auswirkungen auf die tatsächlich replizierten Produktionsressourcen. Wenn ein tatsächlicher Failover (geplant oder ungeplant) erforderlich ist, orchestriert der BlueXP disaster recovery mit wenigen Klicks alle erforderlichen Schritte, um die geschützten virtuellen Maschinen automatisch am vorgesehenen Notfallwiederherstellungsstandort hochzufahren. Der Dienst kehrt außerdem die SnapMirror -Beziehung zum primären Standort um und repliziert bei Bedarf alle Änderungen vom sekundären zum primären Standort für einen Failback-Vorgang. All dies kann im Vergleich zu anderen bekannten Alternativen zu einem Bruchteil der Kosten erreicht werden.
Erste Schritte
Um mit der BlueXP disaster recovery zu beginnen, verwenden Sie die BlueXP -Konsole und greifen Sie dann auf den Dienst zu.
-
Melden Sie sich bei BlueXP an.
-
Wählen Sie in der linken Navigationsleiste von BlueXP „Schutz“ > „Notfallwiederherstellung“ aus.
-
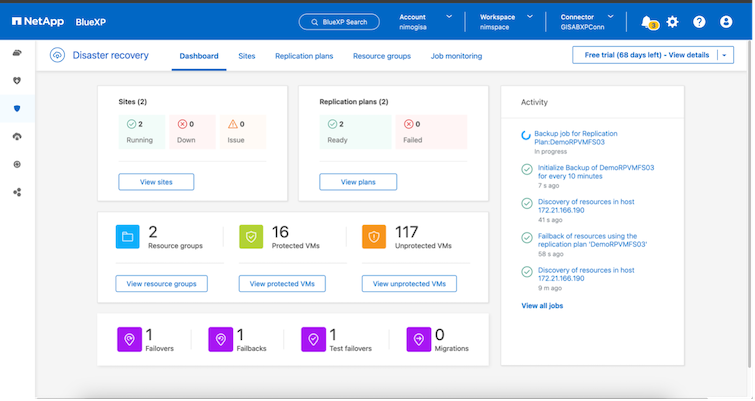
Das BlueXP disaster recovery wird angezeigt.
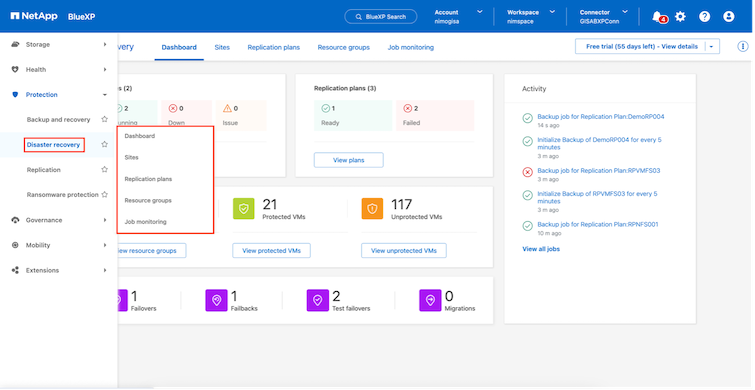
Stellen Sie vor der Konfiguration des Notfallwiederherstellungsplans sicher, dass die folgenden Voraussetzungen erfüllt sind:
-
BlueXP Connector wird in NetApp BlueXP eingerichtet. Der Connector sollte in AWS VPC bereitgestellt werden.
-
Die BlueXP Connector-Instanz verfügt über eine Verbindung zum Quell- und Ziel-vCenter und den Speichersystemen.
-
In BlueXP werden lokale NetApp -Speichersysteme hinzugefügt, die VMFS-Datenspeicher für VMware hosten.
-
Bei der Verwendung von DNS-Namen sollte eine DNS-Auflösung vorhanden sein. Andernfalls verwenden Sie IP-Adressen für das vCenter.
-
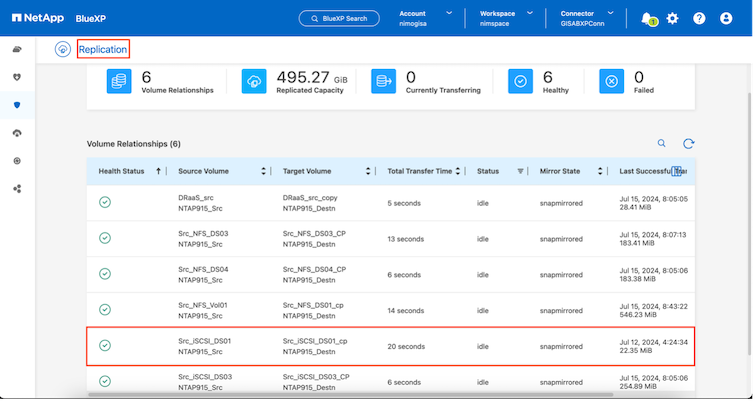
Die SnapMirror Replikation ist für die angegebenen VMFS-basierten Datenspeichervolumes konfiguriert.
Sobald die Verbindung zwischen Quell- und Zielstandort hergestellt ist, fahren Sie mit den Konfigurationsschritten fort. Dies sollte etwa 3 bis 5 Minuten dauern.

|
NetApp empfiehlt, den BlueXP Connector am Disaster-Recovery-Standort oder an einem dritten Standort bereitzustellen, damit der BlueXP Connector bei tatsächlichen Ausfällen oder Naturkatastrophen über das Netzwerk mit Quell- und Zielressourcen kommunizieren kann. |
|
|
Die Unterstützung für lokale VMFS-Datenspeicher befindet sich beim Schreiben dieses Dokuments in der Technologievorschau. Die Funktion wird sowohl mit FC- als auch mit ISCSI-Protokoll-basierten VMFS-Datenspeichern unterstützt. |
BlueXP disaster recovery
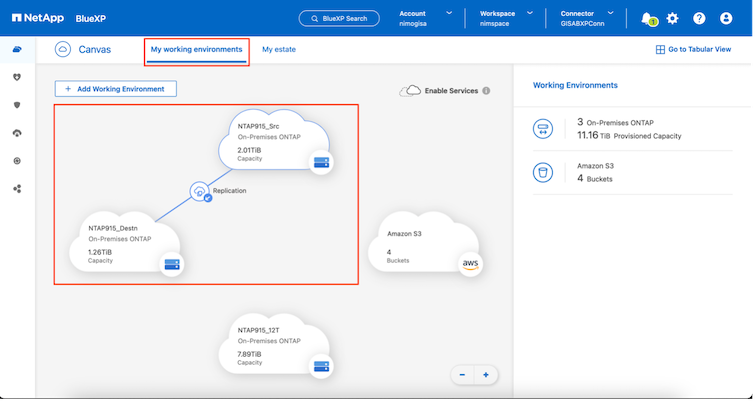
Der erste Schritt bei der Vorbereitung der Notfallwiederherstellung besteht darin, die lokalen vCenter- und Speicherressourcen zu ermitteln und zur BlueXP disaster recovery hinzuzufügen.
|
|
Stellen Sie sicher, dass die ONTAP Speichersysteme der Arbeitsumgebung innerhalb des Canvas hinzugefügt werden. Öffnen Sie die BlueXP -Konsole und wählen Sie in der linken Navigation Schutz > Notfallwiederherstellung. Wählen Sie vCenter-Server ermitteln oder verwenden Sie das Hauptmenü. Wählen Sie Sites > Hinzufügen > vCenter hinzufügen. |
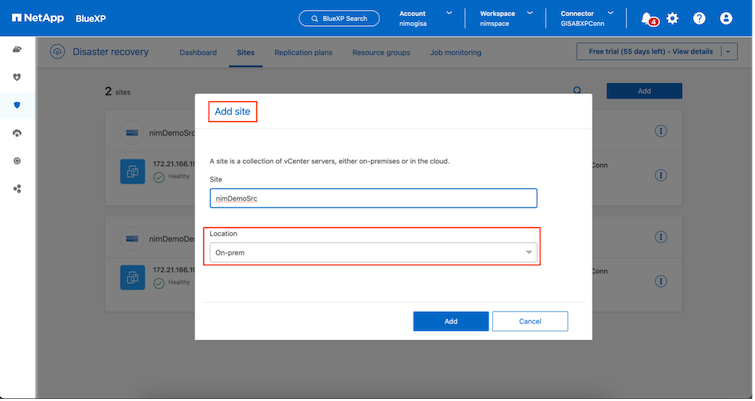
Fügen Sie die folgenden Plattformen hinzu:
-
Quelle. Lokales vCenter.
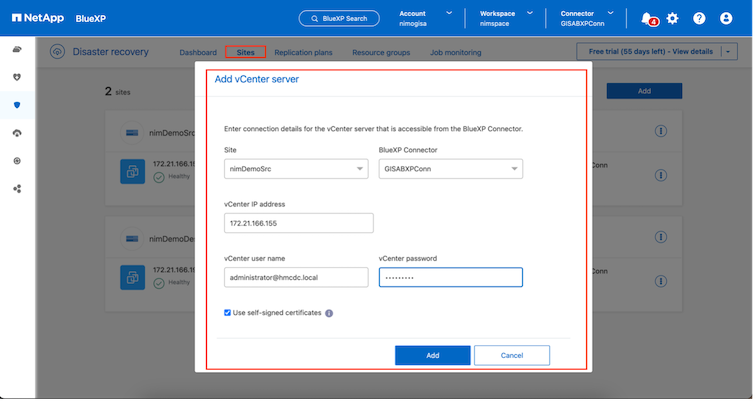
-
Ziel. VMC SDDC vCenter.
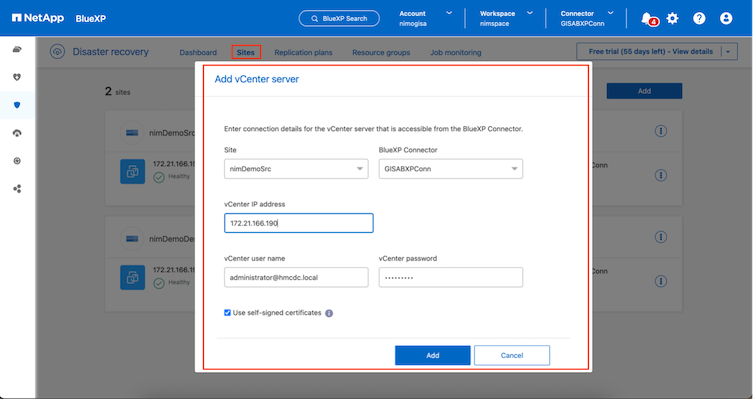
Sobald die vCenter hinzugefügt wurden, wird die automatische Erkennung ausgelöst.
Konfigurieren der Speicherreplikation zwischen Quell- und Zielstandort
SnapMirror nutzt ONTAP -Snapshots, um die Datenübertragung von einem Ort zum anderen zu verwalten. Zunächst wird eine vollständige Kopie basierend auf einem Snapshot des Quellvolumes auf das Ziel kopiert, um eine Basissynchronisierung durchzuführen. Wenn an der Quelle Datenänderungen auftreten, wird ein neuer Snapshot erstellt und mit dem Basis-Snapshot verglichen. Die Blöcke, bei denen Änderungen festgestellt wurden, werden dann zum Ziel repliziert, wobei der neuere Snapshot zur aktuellen Basislinie oder zum neuesten gemeinsamen Snapshot wird. Dadurch kann der Vorgang wiederholt und inkrementelle Updates an das Ziel gesendet werden.
Wenn eine SnapMirror -Beziehung hergestellt wurde, befindet sich das Zielvolume in einem schreibgeschützten Online-Zustand und ist daher weiterhin zugänglich. SnapMirror arbeitet mit physischen Speicherblöcken und nicht auf Datei- oder anderer logischer Ebene. Dies bedeutet, dass das Zielvolume eine identische Replik des Quellvolumes ist, einschließlich Snapshots, Volumeeinstellungen usw. Wenn ONTAP Speicherplatzeffizienzfunktionen wie Datenkomprimierung und Datendeduplizierung vom Quellvolume verwendet werden, behält das replizierte Volume diese Optimierungen bei.
Durch das Aufheben der SnapMirror Beziehung wird das Zielvolume beschreibbar und wird normalerweise zum Durchführen eines Failovers verwendet, wenn SnapMirror zum Synchronisieren von Daten mit einer DR-Umgebung verwendet wird. SnapMirror ist so ausgereift, dass die am Failover-Standort geänderten Daten effizient mit dem primären System resynchronisiert werden können, falls dieses später wieder online geht. Anschließend kann die ursprüngliche SnapMirror Beziehung wiederhergestellt werden.
So richten Sie es für VMware Disaster Recovery ein
Der Vorgang zum Erstellen der SnapMirror Replikation bleibt für jede Anwendung derselbe. Der Vorgang kann manuell oder automatisiert erfolgen. Am einfachsten ist es, BlueXP zu nutzen, um die SnapMirror -Replikation zu konfigurieren. Dazu ziehen Sie das Quell ONTAP -System in der Umgebung einfach per Drag & Drop auf das Ziel, um den Assistenten zu starten, der Sie durch den Rest des Prozesses führt.
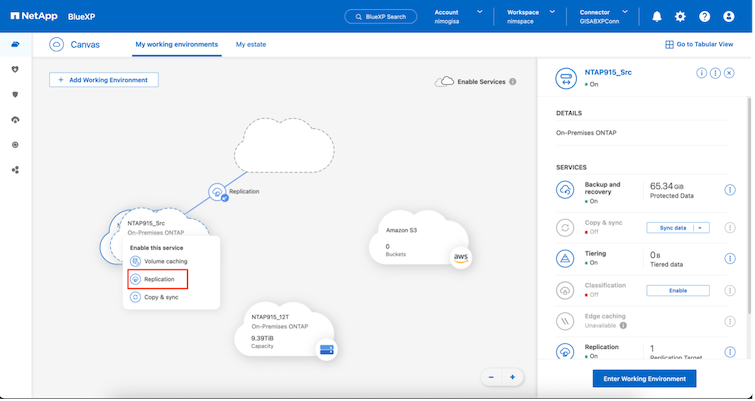
BlueXP DRaaS kann dies auch automatisieren, sofern die folgenden beiden Kriterien erfüllt sind:
-
Quell- und Zielcluster haben eine Peer-Beziehung.
-
Quell-SVM und Ziel-SVM haben eine Peer-Beziehung.
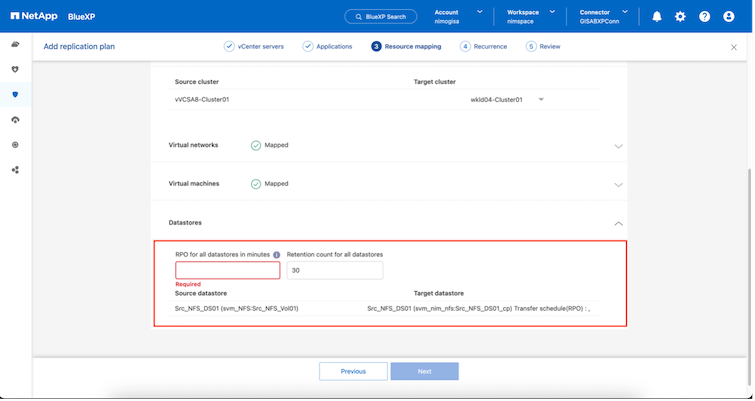
|
|
Wenn die SnapMirror -Beziehung für das Volume bereits über die CLI konfiguriert ist, übernimmt BlueXP DRaaS die Beziehung und fährt mit den restlichen Workflow-Vorgängen fort. |
|
|
Abgesehen von den oben genannten Ansätzen kann die SnapMirror Replikation auch über ONTAP CLI oder System Manager erstellt werden. Unabhängig vom Ansatz, der zum Synchronisieren der Daten mit SnapMirror verwendet wird, orchestriert BlueXP DRaaS den Workflow für nahtlose und effiziente Disaster-Recovery-Vorgänge. |
Was kann BlueXP disaster recovery für Sie tun?
Nachdem die Quell- und Zielsites hinzugefügt wurden, führt die BlueXP disaster recovery eine automatische Tiefenerkennung durch und zeigt die VMs zusammen mit den zugehörigen Metadaten an. Die BlueXP disaster recovery erkennt außerdem automatisch die von den VMs verwendeten Netzwerke und Portgruppen und füllt sie.
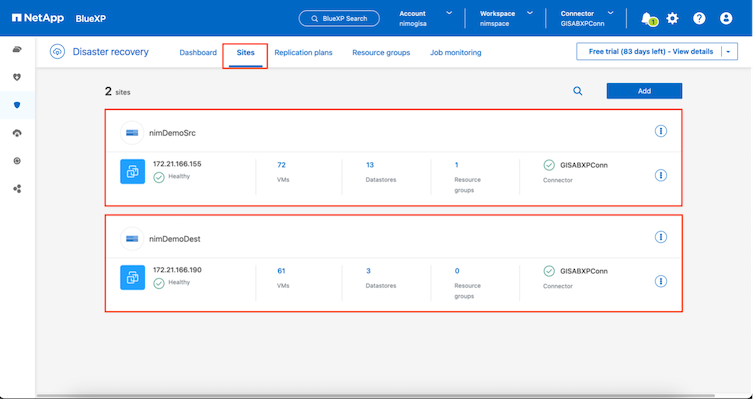
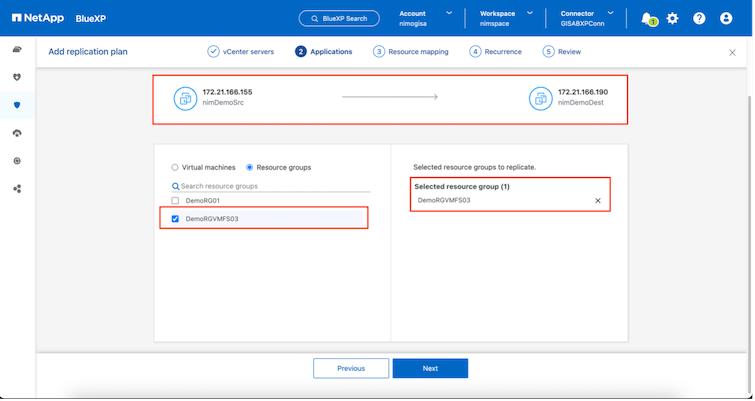
Nachdem die Sites hinzugefügt wurden, können VMs in Ressourcengruppen gruppiert werden. Mit den BlueXP disaster recovery können Sie eine Reihe abhängiger VMs in logische Gruppen gruppieren, die ihre Startreihenfolgen und Startverzögerungen enthalten, die bei der Wiederherstellung ausgeführt werden können. Um mit der Erstellung von Ressourcengruppen zu beginnen, navigieren Sie zu Ressourcengruppen und klicken Sie auf Neue Ressourcengruppe erstellen.
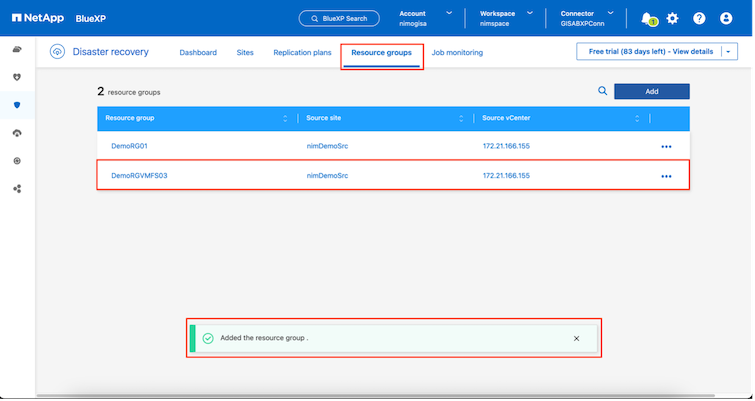
|
|
Die Ressourcengruppe kann auch beim Erstellen eines Replikationsplans erstellt werden. |
Die Startreihenfolge der VMs kann während der Erstellung von Ressourcengruppen mithilfe eines einfachen Drag-and-Drop-Mechanismus definiert oder geändert werden.
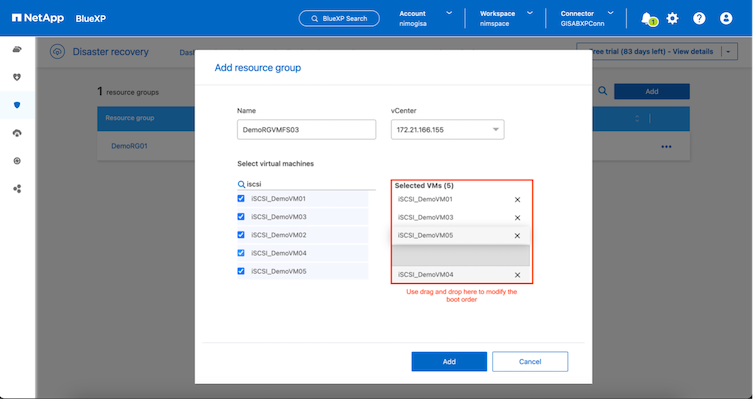
Sobald die Ressourcengruppen erstellt sind, besteht der nächste Schritt darin, den Ausführungsentwurf oder einen Plan zur Wiederherstellung virtueller Maschinen und Anwendungen im Katastrophenfall zu erstellen. Wie in den Voraussetzungen erwähnt, kann die SnapMirror Replikation im Voraus konfiguriert werden, oder DRaaS kann sie mithilfe des RPO und der Aufbewahrungsanzahl konfigurieren, die bei der Erstellung des Replikationsplans angegeben wurden.
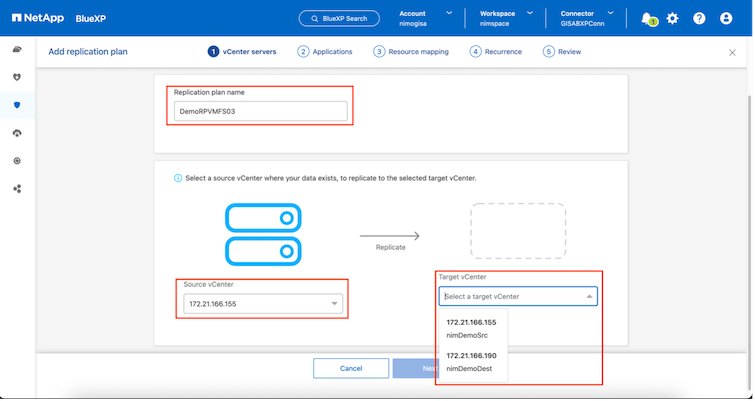
Konfigurieren Sie den Replikationsplan, indem Sie die Quell- und Ziel-vCenter-Plattformen aus der Dropdown-Liste auswählen und die Ressourcengruppen auswählen, die in den Plan aufgenommen werden sollen, zusammen mit der Gruppierung, wie Anwendungen wiederhergestellt und eingeschaltet werden sollen, und der Zuordnung von Clustern und Netzwerken. Um den Wiederherstellungsplan zu definieren, navigieren Sie zur Registerkarte Replikationsplan und klicken Sie auf Plan hinzufügen.
Wählen Sie zuerst das Quell-vCenter und dann das Ziel-vCenter aus.
Der nächste Schritt besteht darin, vorhandene Ressourcengruppen auszuwählen. Wenn keine Ressourcengruppen erstellt wurden, hilft der Assistent dabei, die erforderlichen virtuellen Maschinen basierend auf den Wiederherstellungszielen zu gruppieren (im Wesentlichen funktionale Ressourcengruppen zu erstellen). Dies hilft auch dabei, die Vorgangsreihenfolge für die Wiederherstellung virtueller Anwendungsmaschinen zu definieren.
|
|
Die Ressourcengruppe ermöglicht das Festlegen der Startreihenfolge per Drag-and-Drop-Funktion. Damit lässt sich die Reihenfolge, in der die VMs während des Wiederherstellungsprozesses eingeschaltet werden, einfach ändern. |
|
|
Jede virtuelle Maschine innerhalb einer Ressourcengruppe wird der Reihe nach basierend auf der Reihenfolge gestartet. Zwei Ressourcengruppen werden parallel gestartet. |
Der folgende Screenshot zeigt die Option zum Filtern virtueller Maschinen oder bestimmter Datenspeicher basierend auf organisatorischen Anforderungen, wenn nicht zuvor Ressourcengruppen erstellt wurden.
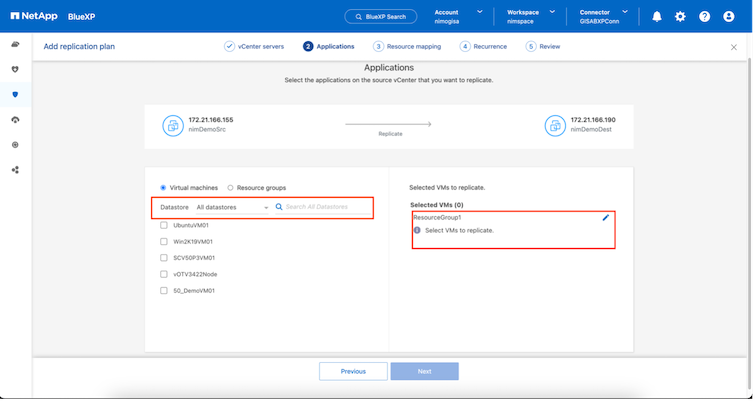
Sobald die Ressourcengruppen ausgewählt sind, erstellen Sie die Failover-Zuordnungen. Geben Sie in diesem Schritt an, wie die Ressourcen aus der Quellumgebung dem Ziel zugeordnet werden. Dazu gehören Rechenressourcen und virtuelle Netzwerke. IP-Anpassung, Pre- und Post-Skripte, Boot-Verzögerungen, Anwendungskonsistenz und so weiter. Ausführliche Informationen finden Sie unter"Erstellen eines Replikationsplans" .
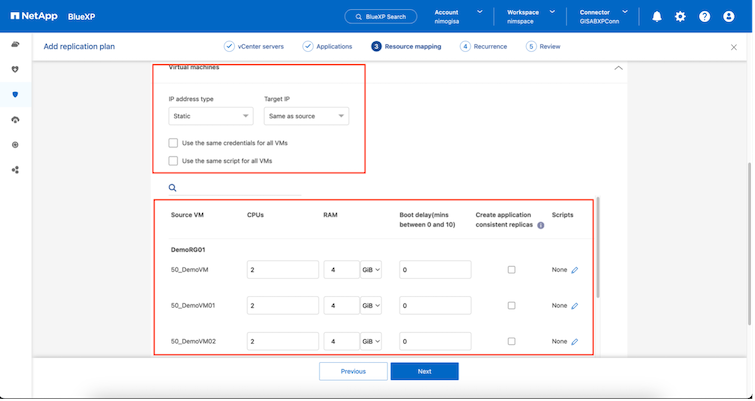
|
|
Standardmäßig werden für Test- und Failovervorgänge dieselben Zuordnungsparameter verwendet. Um verschiedene Zuordnungen für die Testumgebung anzuwenden, wählen Sie die Option „Testzuordnung“ aus, nachdem Sie das Kontrollkästchen wie unten gezeigt deaktiviert haben: |
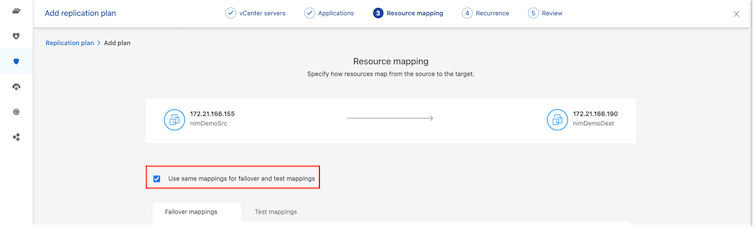
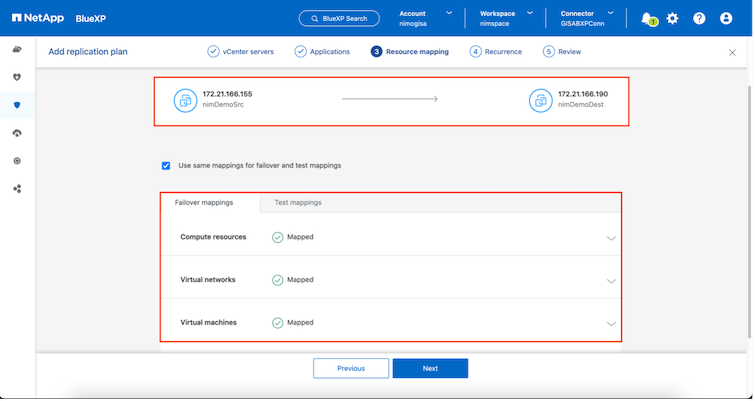
Klicken Sie nach Abschluss der Ressourcenzuordnung auf „Weiter“.
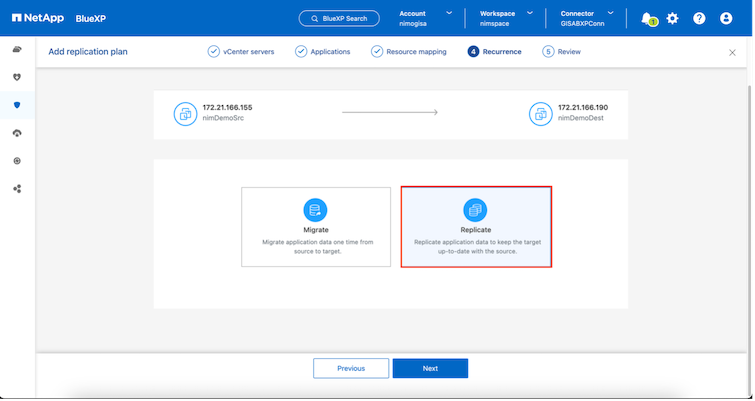
Wählen Sie den Wiederholungstyp aus. Einfach ausgedrückt: Wählen Sie „Migrieren“ (einmalige Migration mit Failover) oder die Option „Wiederkehrende kontinuierliche Replikation“. In dieser exemplarischen Vorgehensweise ist die Option „Replizieren“ ausgewählt.
Überprüfen Sie anschließend die erstellten Zuordnungen und klicken Sie dann auf „Plan hinzufügen“.
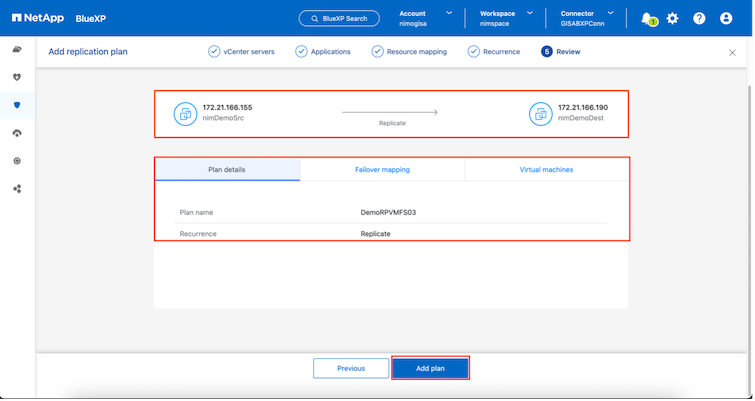
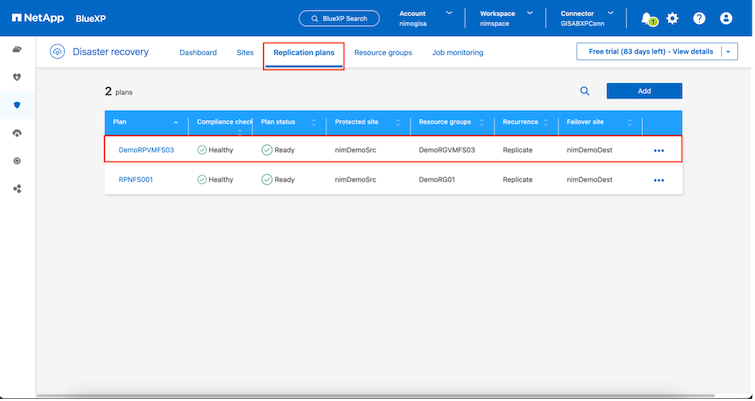
Sobald der Replikationsplan erstellt ist, kann je nach Bedarf ein Failover durchgeführt werden, indem die Failover-Option, die Test-Failover-Option oder die Migrationsoption ausgewählt wird. BlueXP disaster recovery stellt sicher, dass der Replikationsprozess planmäßig alle 30 Minuten ausgeführt wird. Während der Failover- und Test-Failover-Optionen können Sie die aktuellste SnapMirror -Snapshot-Kopie verwenden oder eine bestimmte Snapshot-Kopie aus einer Point-in-Time-Snapshot-Kopie auswählen (gemäß der Aufbewahrungsrichtlinie von SnapMirror). Die Point-in-Time-Option kann sehr hilfreich sein, wenn es zu einem Korruptionsereignis wie Ransomware kommt, bei dem die aktuellsten Replikate bereits kompromittiert oder verschlüsselt sind. BlueXP disaster recovery zeigt alle verfügbaren Wiederherstellungspunkte an.
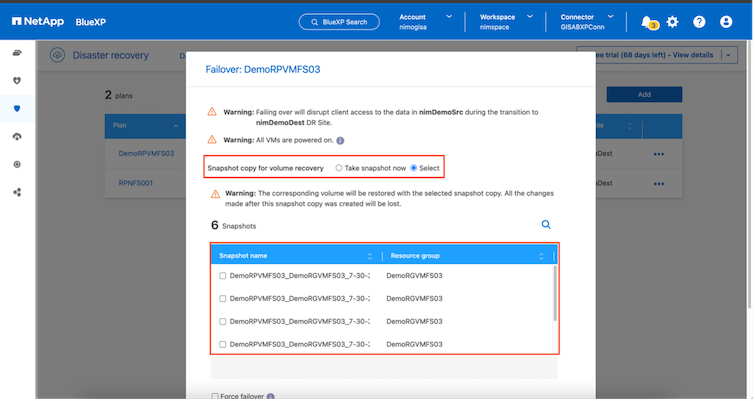
Um ein Failover oder ein Test-Failover mit der im Replikationsplan angegebenen Konfiguration auszulösen, klicken Sie auf Failover oder Test-Failover.
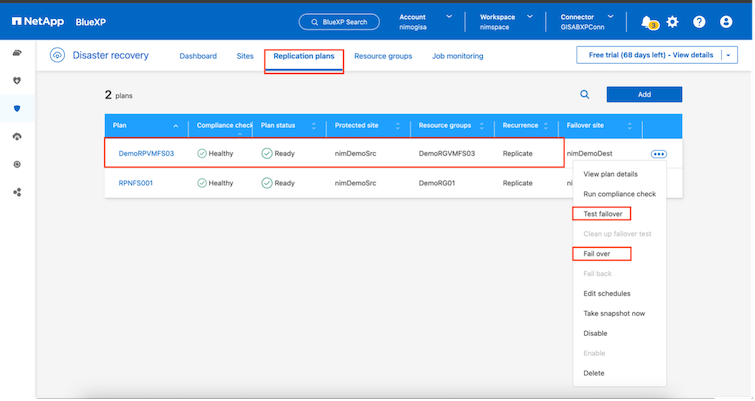
Was passiert während eines Failovers oder Test-Failover-Vorgangs?
Während eines Test-Failover-Vorgangs erstellt die BlueXP disaster recovery mithilfe der neuesten Snapshot-Kopie oder eines ausgewählten Snapshots des Ziel-Volumes ein FlexClone -Volume auf dem Ziel ONTAP -Speichersystem.
|
|
Ein Test-Failover-Vorgang erstellt ein geklontes Volume auf dem Ziel ONTAP -Speichersystem. |
|
|
Das Ausführen eines Testwiederherstellungsvorgangs hat keine Auswirkungen auf die SnapMirror Replikation. |
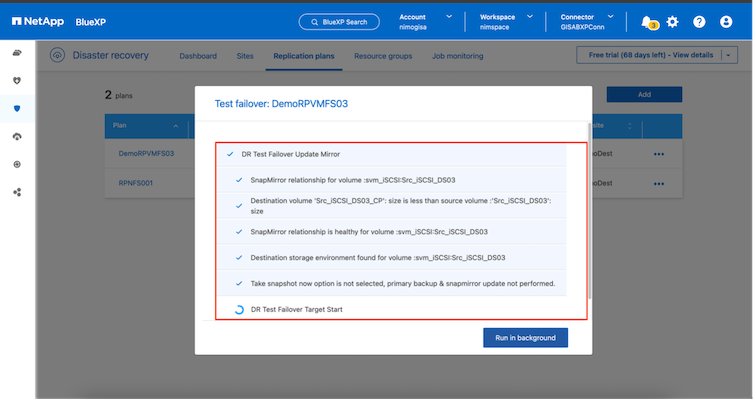
Während des Vorgangs ordnet BlueXP disaster recovery das ursprüngliche Zielvolume nicht zu. Stattdessen wird aus dem ausgewählten Snapshot ein neues FlexClone Volume erstellt und ein temporärer Datenspeicher, der das FlexClone Volume unterstützt, wird den ESXi-Hosts zugeordnet.
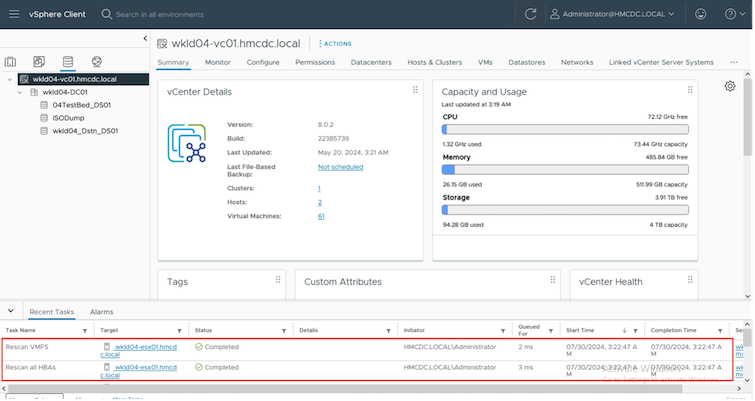
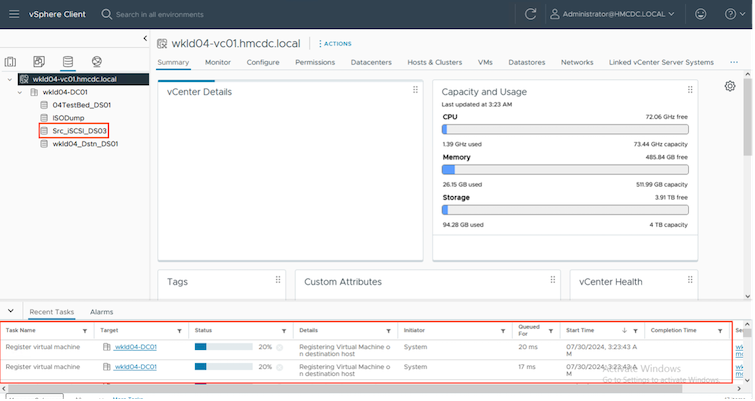
Wenn der Test-Failover-Vorgang abgeschlossen ist, kann der Bereinigungsvorgang mit "Failover-Test bereinigen" ausgelöst werden. Während dieses Vorgangs zerstört die BlueXP disaster recovery das FlexClone -Volume, das bei diesem Vorgang verwendet wurde.
Im Falle eines echten Katastrophenfalls führt die BlueXP disaster recovery die folgenden Schritte aus:
-
Bricht die SnapMirror -Beziehung zwischen den Sites ab.
-
Mountet das VMFS-Datenspeichervolume nach der Neusignierung zur sofortigen Verwendung.
-
Registrieren der VMs
-
VMs einschalten
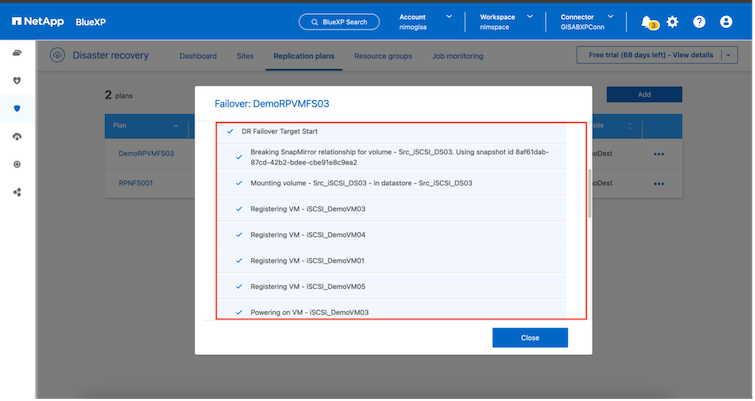
Sobald die primäre Site betriebsbereit ist, ermöglicht die BlueXP disaster recovery die umgekehrte Neusynchronisierung für SnapMirror und ermöglicht ein Failback, das ebenfalls per Mausklick ausgeführt werden kann.
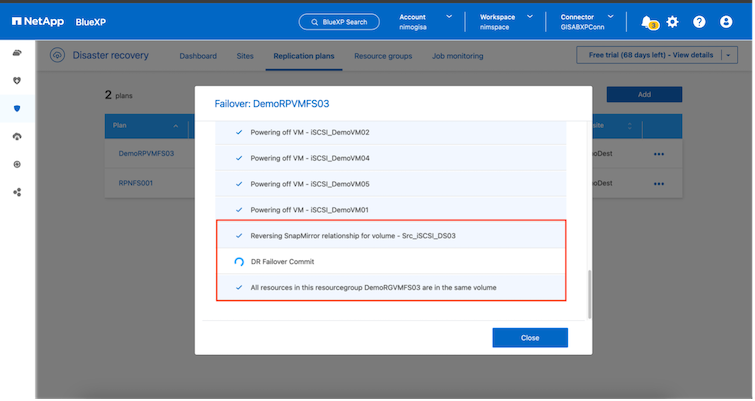
Und wenn die Migrationsoption gewählt wird, wird dies als geplantes Failover-Ereignis betrachtet. In diesem Fall wird ein zusätzlicher Schritt ausgelöst, der darin besteht, die virtuellen Maschinen am Quellstandort herunterzufahren. Die restlichen Schritte bleiben dieselben wie beim Failover-Ereignis.
Von BlueXP oder der ONTAP CLI aus können Sie den Replikationszustand für die entsprechenden Datenspeichervolumes überwachen und den Status eines Failovers oder Testfailovers über die Jobüberwachung verfolgen.
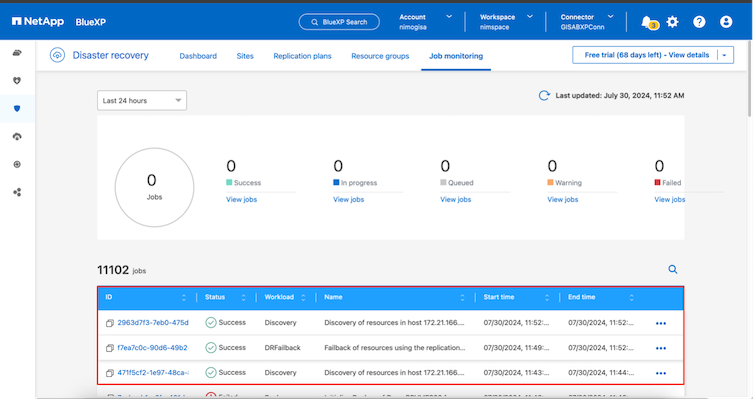
Dies bietet eine leistungsstarke Lösung zur Handhabung eines maßgeschneiderten und individuellen Notfallwiederherstellungsplans. Das Failover kann als geplantes Failover oder per Mausklick erfolgen, wenn ein Notfall eintritt und die Entscheidung zur Aktivierung der DR-Site getroffen wird.
Um mehr über diesen Prozess zu erfahren, können Sie sich gerne das ausführliche Walkthrough-Video ansehen oder die"Lösungssimulator" .