

TR-4923: SQL Server auf AWS EC2 mit Amazon FSx ONTAP
 Änderungen vorschlagen
Änderungen vorschlagen
Diese Lösung umfasst die Bereitstellung von SQL Server auf AWS EC2 unter Verwendung von Amazon FSx ONTAP.
Einführung
Viele Unternehmen, die Anwendungen von lokalen Speichersystemen in die Cloud migrieren möchten, stellen fest, dass dies durch die unterschiedlichen Funktionen lokaler Speichersysteme und Cloud-Speicherdienste erschwert wird. Diese Lücke hat die Migration von Unternehmensanwendungen wie Microsoft SQL Server deutlich problematischer gemacht. Insbesondere Lücken bei den Diensten, die zum Ausführen einer Unternehmensanwendung erforderlich sind, wie etwa robuste Snapshots, Speichereffizienzfunktionen, hohe Verfügbarkeit, Zuverlässigkeit und konstante Leistung, haben Kunden gezwungen, Kompromisse beim Design einzugehen oder auf eine Anwendungsmigration zu verzichten. Mit FSx ONTAP müssen Kunden keine Kompromisse mehr eingehen. FSx ONTAP ist ein nativer (1st-Party-)AWS-Dienst, der von AWS verkauft, unterstützt, in Rechnung gestellt und vollständig verwaltet wird. Es nutzt die Leistungsfähigkeit von NetApp ONTAP , um dieselben Speicher- und Datenverwaltungsfunktionen der Enterprise-Klasse bereitzustellen, die NetApp seit drei Jahrzehnten vor Ort in AWS als Managed Service bereitstellt.
Mit SQL Server auf EC2-Instanzen können Datenbankadministratoren auf ihre Datenbankumgebung und das zugrunde liegende Betriebssystem zugreifen und diese anpassen. Eine SQL Server auf EC2-Instanz in Kombination mit "AWS FSx ONTAP" zum Speichern der Datenbankdateien, ermöglicht hohe Leistung, Datenverwaltung und einen einfachen und unkomplizierten Migrationspfad durch Replikation auf Blockebene. Daher können Sie Ihre komplexe Datenbank mit einem einfachen Lift-and-Shift-Ansatz, weniger Klicks und ohne Schemakonvertierungen auf AWS VPC ausführen.
Vorteile der Verwendung von Amazon FSx ONTAP mit SQL Server
Amazon FSx ONTAP ist der ideale Dateispeicher für SQL Server-Bereitstellungen in AWS. Zu den Vorteilen gehören:
-
Konstant hohe Leistung und Durchsatz bei geringer Latenz
-
Intelligentes Caching mit NVMe-Cache zur Leistungssteigerung
-
Flexible Dimensionierung, sodass Sie Kapazität, Durchsatz und IOPs im Handumdrehen erhöhen oder verringern können
-
Effiziente Blockreplikation von On-Premises zu AWS
-
Die Verwendung von iSCSI, einem bekannten Protokoll für die Datenbankumgebung
-
Speichereffizienzfunktionen wie Thin Provisioning und Zero-Footprint-Klone
-
Reduzierung der Backup-Zeit von Stunden auf Minuten, wodurch die RTO reduziert wird
-
Granulare Sicherung und Wiederherstellung von SQL-Datenbanken mit der intuitiven NetApp SnapCenter -Benutzeroberfläche
-
Die Möglichkeit, vor der eigentlichen Migration mehrere Testmigrationen durchzuführen
-
Kürzere Ausfallzeiten während der Migration und Überwindung von Migrationsproblemen durch Kopieren auf Datei- oder E/A-Ebene
-
Reduzieren der MTTR durch Auffinden der Grundursache nach einer Hauptversion oder einem Patch-Update
Die Bereitstellung von SQL Server-Datenbanken auf FSx ONTAP mit dem iSCSI-Protokoll, wie es üblicherweise vor Ort verwendet wird, bietet eine ideale Datenbankspeicherumgebung mit überlegener Leistung, Speichereffizienz und Datenverwaltungsfunktionen. Bei Verwendung mehrerer iSCSI-Sitzungen und einer angenommenen Arbeitssatzgröße von 5 % liefert die Einbindung eines Flash-Cache über 100.000 IOPs mit dem FSx ONTAP Dienst. Diese Konfiguration bietet vollständige Kontrolle über die Leistung für die anspruchsvollsten Anwendungen. SQL Server, der auf kleineren EC2-Instanzen ausgeführt wird, die mit FSx ONTAP verbunden sind, kann die gleiche Leistung erbringen wie SQL Server, der auf einer viel größeren EC2-Instanz ausgeführt wird, da für FSx ONTAP nur Netzwerkbandbreitenbeschränkungen gelten. Durch die Reduzierung der Instanzgröße werden auch die Rechenkosten gesenkt, was eine TCO-optimierte Bereitstellung ermöglicht. Die Kombination von SQL unter Verwendung von iSCSI, SMB3.0 mit Multichannel- und kontinuierlichen Verfügbarkeitsanteilen auf FSx ONTAP bietet große Vorteile für SQL-Workloads.
Bevor Sie beginnen
Die Kombination aus Amazon FSx ONTAP und SQL Server auf einer EC2-Instance ermöglicht die Erstellung von Datenbankspeicherdesigns auf Unternehmensebene, die den anspruchsvollsten Anwendungsanforderungen von heute gerecht werden. Um beide Technologien zu optimieren, ist es wichtig, die E/A-Muster und -Eigenschaften von SQL Server zu verstehen. Ein gut konzipiertes Speicherlayout für eine SQL Server-Datenbank unterstützt die Leistung von SQL Server und die Verwaltung der SQL Server-Infrastruktur. Ein gutes Speicherlayout ermöglicht außerdem eine erfolgreiche Erstbereitstellung und ein reibungsloses Wachstum der Umgebung im Laufe der Zeit, wenn Ihr Unternehmen wächst.
Voraussetzungen
Bevor Sie die Schritte in diesem Dokument ausführen, sollten Sie über die folgenden Voraussetzungen verfügen:
-
Ein AWS-Konto
-
Geeignete IAM-Rollen zur Bereitstellung von EC2 und FSx ONTAP
-
Eine Windows Active Directory-Domäne auf EC2
-
Alle SQL Server-Knoten müssen miteinander kommunizieren können
-
Stellen Sie sicher, dass die DNS-Auflösung funktioniert und Hostnamen aufgelöst werden können. Wenn nicht, verwenden Sie den Host-Dateieintrag.
-
Allgemeine Kenntnisse zur SQL Server-Installation
Beachten Sie außerdem die NetApp Best Practices für SQL Server-Umgebungen, um die beste Speicherkonfiguration sicherzustellen.
Best Practice-Konfigurationen für SQL Server-Umgebungen auf EC2
Mit FSx ONTAP ist die Beschaffung von Speicher die einfachste Aufgabe und kann durch Aktualisieren des Dateisystems durchgeführt werden. Dieser einfache Prozess ermöglicht eine dynamische Kosten- und Leistungsoptimierung nach Bedarf, trägt zum Ausgleich der SQL-Arbeitslast bei und ist außerdem eine hervorragende Voraussetzung für Thin Provisioning. FSx ONTAP Thin Provisioning ist darauf ausgelegt, EC2-Instanzen mit SQL Server mehr logischen Speicher bereitzustellen, als im Dateisystem bereitgestellt wird. Anstatt Speicherplatz im Voraus zuzuweisen, wird Speicherplatz jedem Volume oder LUN dynamisch zugewiesen, während Daten geschrieben werden. In den meisten Konfigurationen wird freier Speicherplatz auch dann freigegeben, wenn Daten im Volume oder LUN gelöscht werden (und nicht von Snapshot-Kopien belegt werden). Die folgende Tabelle enthält Konfigurationseinstellungen für die dynamische Speicherzuweisung.
Einstellung |
Konfiguration |
Volumengarantie |
Keine (standardmäßig eingestellt) |
LUN-Reservierung |
Ermöglicht |
Teilreserve |
0 % (standardmäßig eingestellt) |
snap_reserve |
0 % |
Automatisches Löschen |
Volumen / älteste_zuerst |
Automatische Größe |
Ein |
Versuchen Sie es zuerst |
Automatisches Wachstum |
Volume-Tiering-Richtlinie |
Nur Schnappschuss |
Snapshot-Richtlinie |
Keine |
Bei dieser Konfiguration kann die Gesamtgröße der Volumes größer sein als der tatsächlich im Dateisystem verfügbare Speicher. Wenn die LUNs oder Snapshot-Kopien mehr Speicherplatz benötigen, als auf dem Volume verfügbar ist, wachsen die Volumes automatisch und beanspruchen mehr Speicherplatz vom enthaltenen Dateisystem. Mit Autogrow kann FSx ONTAP die Größe des Volumes automatisch auf eine von Ihnen vorab festgelegte Maximalgröße erhöhen. Im enthaltenen Dateisystem muss Speicherplatz verfügbar sein, um das automatische Wachstum des Volumes zu unterstützen. Wenn die automatische Vergrößerung aktiviert ist, sollten Sie daher den freien Speicherplatz im enthaltenen Dateisystem überwachen und das Dateisystem bei Bedarf aktualisieren.
Stellen Sie außerdem die "Platzzuweisung" Option auf LUN, damit FSx ONTAP den EC2-Host benachrichtigt, wenn der Speicherplatz auf dem Volume erschöpft ist und die LUN im Volume keine Schreibvorgänge annehmen kann. Außerdem ermöglicht diese Option FSx ONTAP , automatisch Speicherplatz freizugeben, wenn der SQL Server auf dem EC2-Host Daten löscht. Die Option zur Speicherplatzzuweisung ist standardmäßig deaktiviert.

|
Wenn eine LUN mit reserviertem Speicherplatz in einem nicht garantierten Volume erstellt wird, verhält sich die LUN genauso wie eine LUN mit nicht reserviertem Speicherplatz. Dies liegt daran, dass ein nicht garantiertes Volume keinen Speicherplatz hat, der der LUN zugewiesen werden kann. Das Volume selbst kann aufgrund seiner fehlenden Garantie nur Speicherplatz zuweisen, wenn darauf geschrieben wird. |
Mit dieser Konfiguration können FSx ONTAP -Administratoren das Volume im Allgemeinen so dimensionieren, dass sie den verwendeten Speicherplatz in der LUN auf der Hostseite und im Dateisystem verwalten und überwachen müssen.
|
|
NetApp empfiehlt die Verwendung eines separaten Dateisystems für SQL-Server-Workloads. Wenn das Dateisystem für mehrere Anwendungen verwendet wird, überwachen Sie die Speicherplatznutzung sowohl des Dateisystems als auch der Volumes innerhalb des Dateisystems, um sicherzustellen, dass die Volumes nicht um den verfügbaren Speicherplatz konkurrieren. |
|
|
Snapshot-Kopien, die zum Erstellen von FlexClone Volumes verwendet werden, werden durch die Autodelete-Option nicht gelöscht. |
|
|
Bei unternehmenskritischen Anwendungen wie SQL Servern, bei denen selbst minimale Ausfälle nicht toleriert werden können, muss eine Überbelegung des Speichers sorgfältig abgewogen und verwaltet werden. In einem solchen Fall empfiehlt es sich, die Trends beim Speicherverbrauch zu überwachen, um zu ermitteln, wie viel Überbelegung (wenn überhaupt) akzeptabel ist. |
Bewährte Vorgehensweisen
-
Um eine optimale Speicherleistung zu erzielen, stellen Sie eine Dateisystemkapazität bereit, die 1,35-mal so groß ist wie die gesamte Datenbanknutzung.
-
Um Anwendungsausfallzeiten zu vermeiden, ist bei der Verwendung von Thin Provisioning eine entsprechende Überwachung in Verbindung mit einem wirksamen Aktionsplan erforderlich.
-
Stellen Sie sicher, dass Sie Warnmeldungen für Cloudwatch und andere Überwachungstools einrichten, damit die Leute rechtzeitig kontaktiert werden, um zu reagieren, wenn der Speicher voll ist.
Konfigurieren Sie den Speicher für SQL Server und stellen Sie Snapcenter für Sicherungs-, Wiederherstellungs- und Klonvorgänge bereit
Um SQL-Server-Operationen mit SnapCenter durchzuführen, müssen Sie zunächst Volumes und LUNs für den SQL-Server erstellen.
Erstellen von Volumes und LUNs für SQL Server
Führen Sie die folgenden Schritte aus, um Volumes und LUNs für SQL Server zu erstellen:
-
Öffnen Sie die Amazon FSx Konsole unter https://console.aws.amazon.com/fsx/
-
Erstellen Sie ein Amazon FSx für das NetApp ONTAP Dateisystem mit der Option „Standarderstellung“ unter „Erstellungsmethode“. Auf diese Weise können Sie FSxadmin- und vsadmin-Anmeldeinformationen definieren.
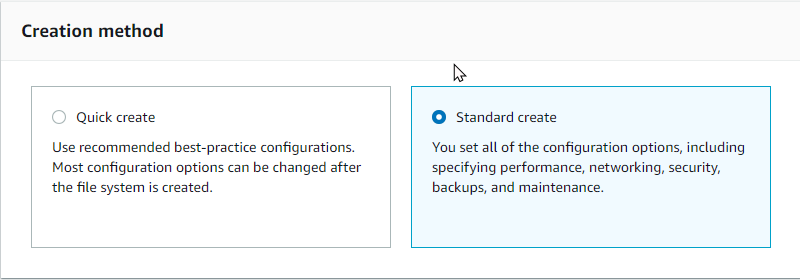
-
Geben Sie das Passwort für fsxadmin an.
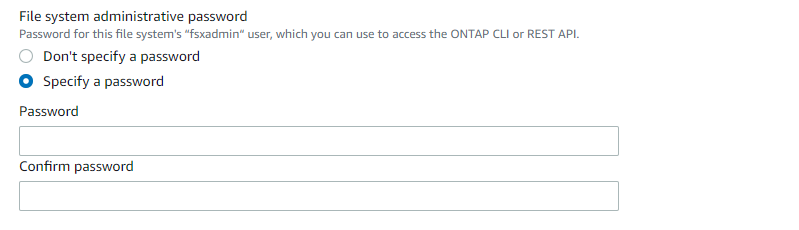
-
Geben Sie das Kennwort für SVMs an.
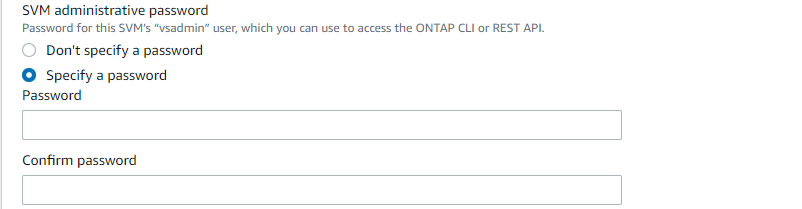
-
Erstellen Sie Volumes, indem Sie die Schritte in "Erstellen eines Volumes auf FSx ONTAP" .
Bewährte Methoden
-
Deaktivieren Sie die Zeitpläne und Aufbewahrungsrichtlinien für das Kopieren von Speicher-Snapshots. Verwenden Sie stattdessen NetApp SnapCenter , um Snapshot-Kopien der SQL Server-Daten und Protokollvolumes zu koordinieren.
-
Konfigurieren Sie Datenbanken auf einzelnen LUNs auf separaten Volumes, um die schnelle und granulare Wiederherstellungsfunktionalität zu nutzen.
-
Platzieren Sie Benutzerdatendateien (.mdf) auf separaten Datenträgern, da es sich um zufällige Lese-/Schreib-Workloads handelt. Es ist üblich, Transaktionsprotokollsicherungen häufiger zu erstellen als Datenbanksicherungen. Aus diesem Grund sollten Sie Transaktionsprotokolldateien (.ldf) auf einem anderen Datenträger als die Datendateien platzieren, sodass für beide Dateien unabhängige Sicherungspläne erstellt werden können. Diese Trennung isoliert auch den sequenziellen Schreib-E/A der Protokolldateien vom zufälligen Lese-/Schreib-E/A der Datendateien und verbessert die SQL Server-Leistung erheblich.
-
Tempdb ist eine Systemdatenbank, die von Microsoft SQL Server als temporärer Arbeitsbereich verwendet wird, insbesondere für E/A-intensive DBCC CHECKDB-Operationen. Platzieren Sie diese Datenbank daher auf einem dedizierten Volume. In großen Umgebungen, in denen die Anzahl der Volumes eine Herausforderung darstellt, können Sie tempdb nach sorgfältiger Planung auf weniger Volumes konsolidieren und auf demselben Volume wie andere Systemdatenbanken speichern. Der Datenschutz für Tempdb hat keine hohe Priorität, da diese Datenbank bei jedem Neustart von Microsoft SQL Server neu erstellt wird.
-
-
Verwenden Sie den folgenden SSH-Befehl, um Volumes zu erstellen:
vol create -vserver svm001 -volume vol_awssqlprod01_data -aggregate aggr1 -size 800GB -state online -tiering-policy snapshot-only -percent-snapshot-space 0 -autosize-mode grow -snapshot-policy none -security-style ntfs volume modify -vserver svm001 -volume vol_awssqlprod01_data -fractional-reserve 0 volume modify -vserver svm001 -volume vol_awssqlprod01_data -space-mgmt-try-first vol_grow volume snapshot autodelete modify -vserver svm001 -volume vol_awssqlprod01_data -delete-order oldest_first
-
Starten Sie den iSCSI-Dienst mit PowerShell unter Verwendung erhöhter Berechtigungen auf Windows-Servern.
Start-service -Name msiscsi Set-Service -Name msiscsi -StartupType Automatic
-
Installieren Sie Multipath-IO mit PowerShell unter Verwendung erhöhter Berechtigungen auf Windows-Servern.
Install-WindowsFeature -name Multipath-IO -Restart
-
Suchen Sie den Windows-Initiatornamen mit PowerShell unter Verwendung erhöhter Berechtigungen in Windows-Servern.
Get-InitiatorPort | select NodeAddress

-
Stellen Sie mithilfe von Putty eine Verbindung zu Storage Virtual Machines (SVM) her und erstellen Sie eine iGroup.
igroup create -igroup igrp_ws2019sql1 -protocol iscsi -ostype windows -initiator iqn.1991-05.com.microsoft:ws2019-sql1.contoso.net
-
Verwenden Sie den folgenden SSH-Befehl, um LUNs zu erstellen:
lun create -path /vol/vol_awssqlprod01_data/lun_awssqlprod01_data -size 700GB -ostype windows_2008 -space-allocation enabled lun create -path /vol/vol_awssqlprod01_log/lun_awssqlprod01_log -size 100GB -ostype windows_2008 -space-allocation enabled
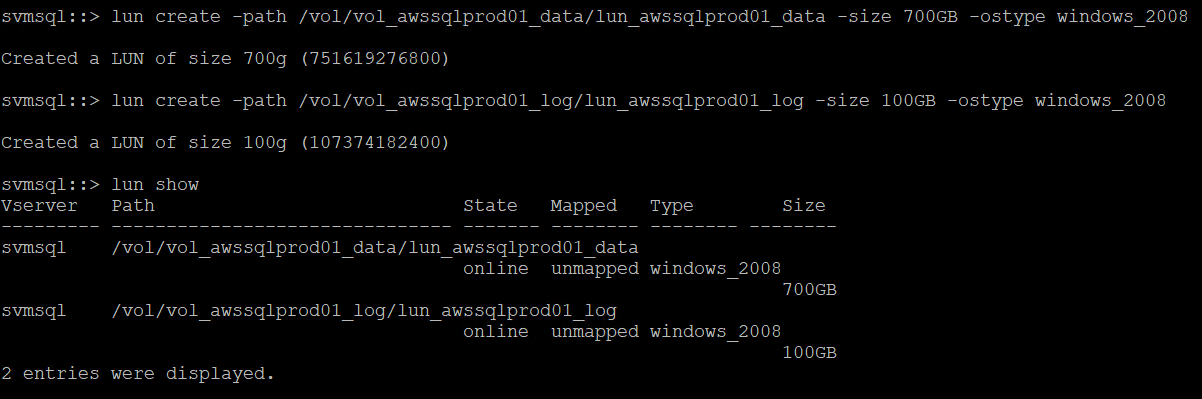
-
Um eine E/A-Ausrichtung mit dem Partitionierungsschema des Betriebssystems zu erreichen, verwenden Sie „windows_2008“ als empfohlenen LUN-Typ. Verweisen "hier," für weitere Informationen.
-
Verwenden Sie den folgenden SSH-Befehl, um die igroup den LUNs zuzuordnen, die Sie gerade erstellt haben.
lun show lun map -path /vol/vol_awssqlprod01_data/lun_awssqlprod01_data -igroup igrp_awssqlprod01lun map -path /vol/vol_awssqlprod01_log/lun_awssqlprod01_log -igroup igrp_awssqlprod01
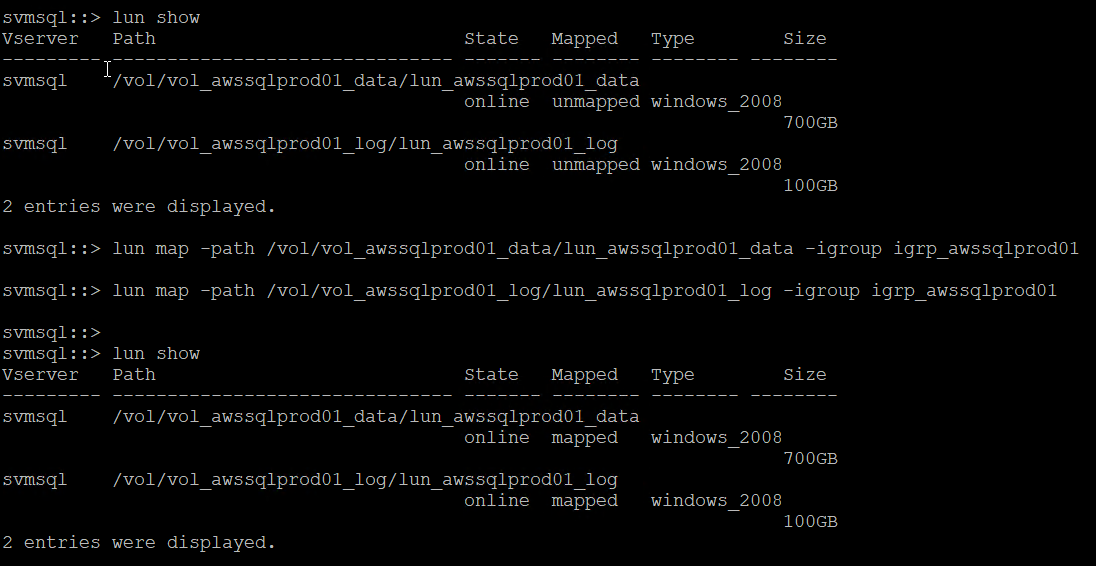
-
Führen Sie für eine freigegebene Festplatte, die den Windows-Failovercluster verwendet, einen SSH-Befehl aus, um dieselbe LUN der Igroup zuzuordnen, die zu allen Servern gehört, die am Windows-Failovercluster teilnehmen.
-
Verbinden Sie Windows Server mit einem SVM mit einem iSCSI-Ziel. Suchen Sie die Ziel-IP-Adresse im AWS-Portal.
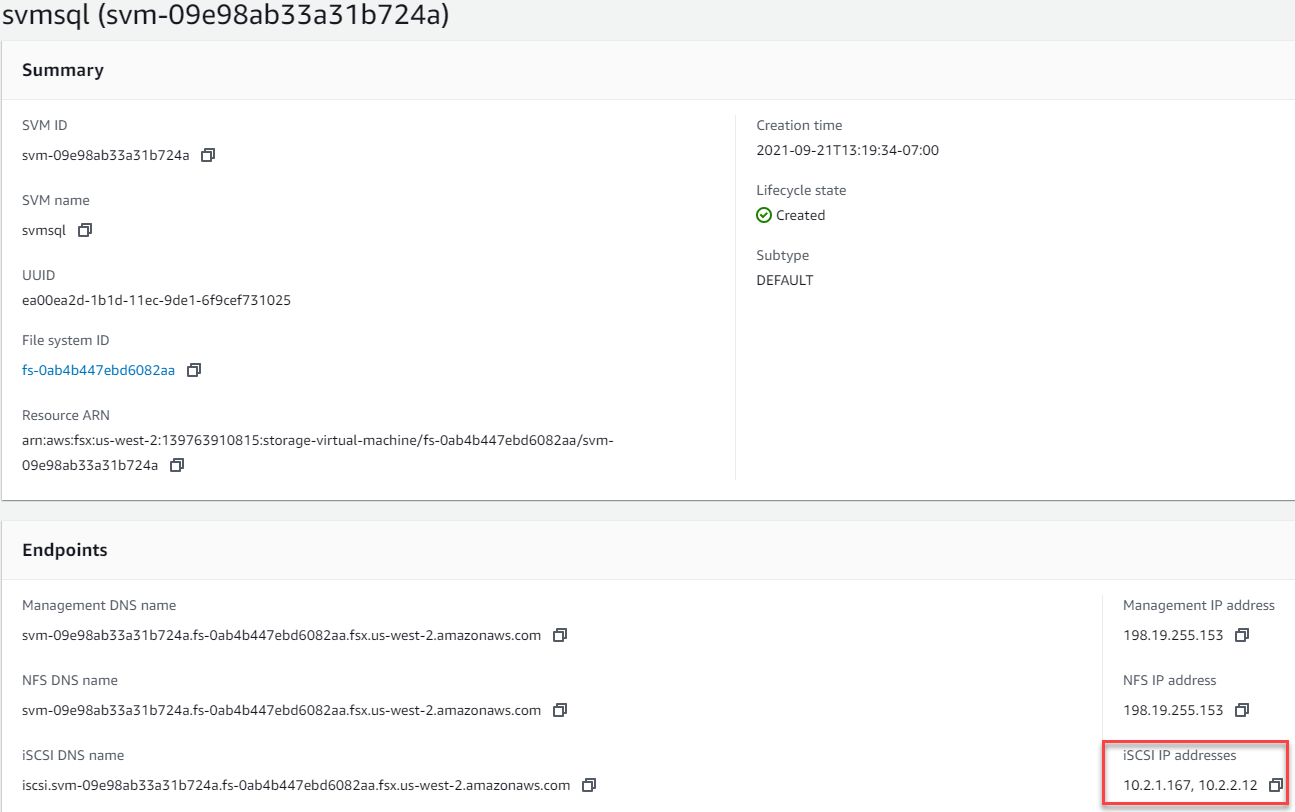
-
Wählen Sie im Server-Manager und im Menü „Tools“ den iSCSI-Initiator aus. Wählen Sie die Registerkarte „Erkennung“ und dann „Portal entdecken“ aus. Geben Sie die iSCSI-IP-Adresse aus dem vorherigen Schritt ein und wählen Sie „Erweitert“ aus. Wählen Sie unter „Lokaler Adapter“ den Microsoft iSCSI-Initiator aus. Wählen Sie unter „Initiator-IP“ die IP des Servers aus. Wählen Sie dann OK, um alle Fenster zu schließen.
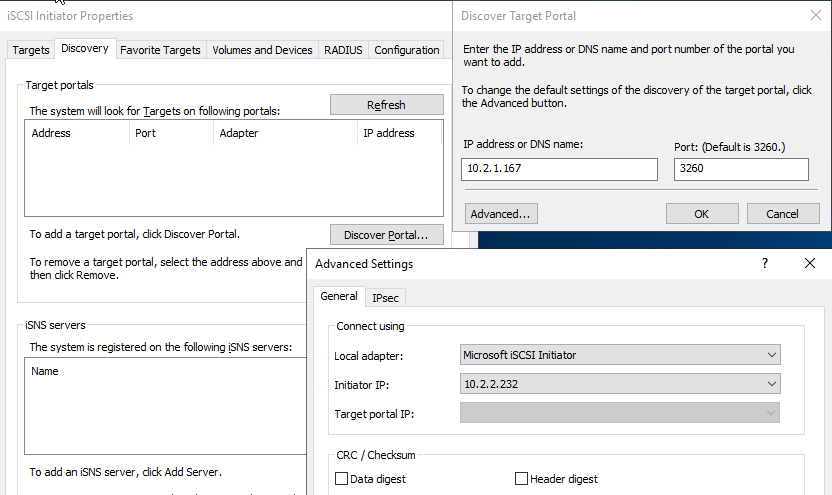
-
Wiederholen Sie Schritt 12 für die zweite iSCSI-IP vom SVM.
-
Wählen Sie die Registerkarte Ziele, wählen Sie Verbinden und wählen Sie Mehrere Pfade aktivieren.
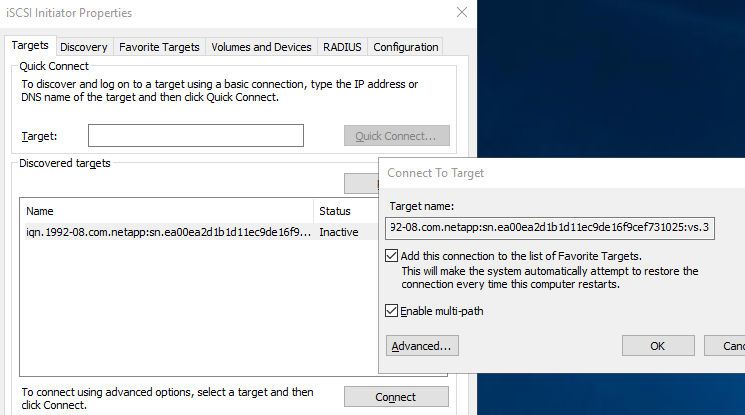
-
Für eine optimale Leistung fügen Sie weitere Sitzungen hinzu. NetApp empfiehlt die Erstellung von fünf iSCSI-Sitzungen. Wählen Sie Eigenschaften > Sitzung hinzufügen > Erweitert und wiederholen Sie Schritt 12.
$TargetPortals = ('10.2.1.167', '10.2.2.12') foreach ($TargetPortal in $TargetPortals) {New-IscsiTargetPortal -TargetPortalAddress $TargetPortal}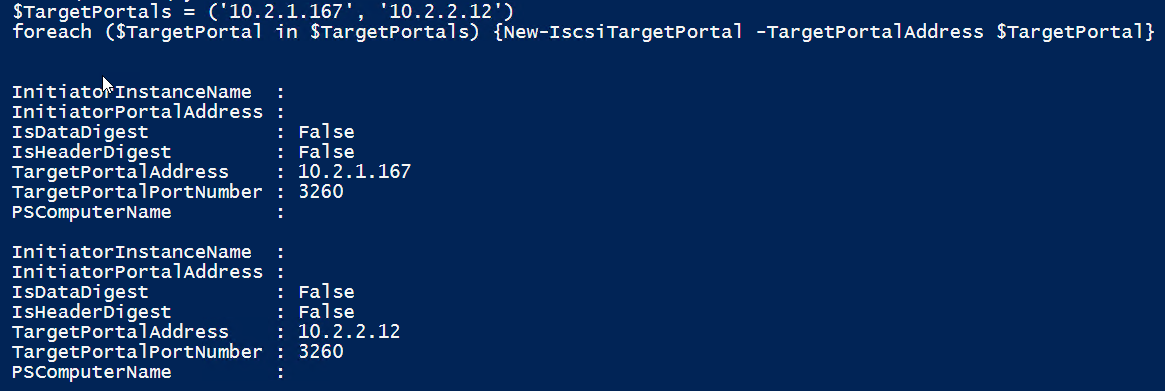
Bewährte Methoden
-
Konfigurieren Sie für optimale Leistung fünf iSCSI-Sitzungen pro Zielschnittstelle.
-
Konfigurieren Sie eine Round-Robin-Richtlinie für die beste iSCSI-Gesamtleistung.
-
Stellen Sie sicher, dass die Zuordnungseinheitsgröße für Partitionen beim Formatieren der LUNs auf 64 KB eingestellt ist
-
Führen Sie den folgenden PowerShell-Befehl aus, um sicherzustellen, dass die iSCSI-Sitzung beibehalten wird.
$targets = Get-IscsiTarget foreach ($target in $targets) { Connect-IscsiTarget -IsMultipathEnabled $true -NodeAddress $target.NodeAddress -IsPersistent $true }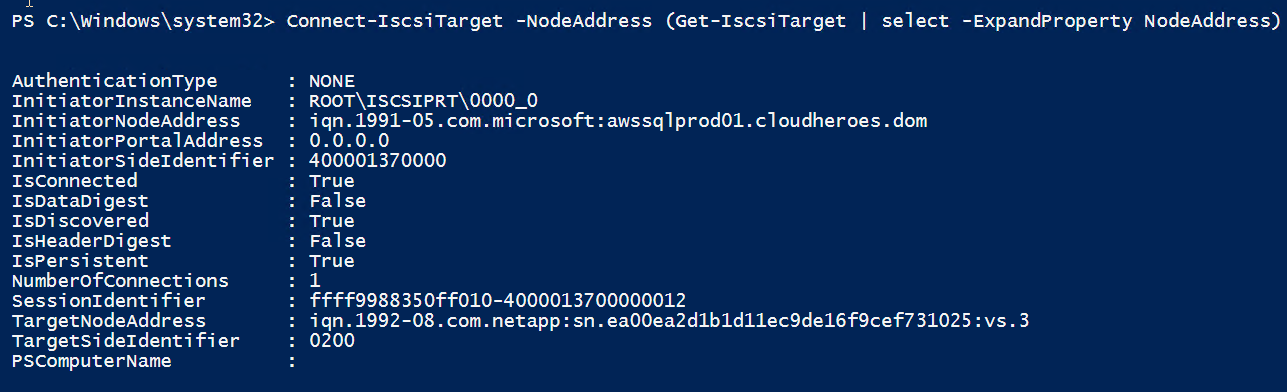
-
Initialisieren Sie die Datenträger mit dem folgenden PowerShell-Befehl.
$disks = Get-Disk | where PartitionStyle -eq raw foreach ($disk in $disks) {Initialize-Disk $disk.Number}
-
Führen Sie die Befehle „Partition erstellen“ und „Datenträger formatieren“ mit PowerShell aus.
New-Partition -DiskNumber 1 -DriveLetter F -UseMaximumSize Format-Volume -DriveLetter F -FileSystem NTFS -AllocationUnitSize 65536 New-Partition -DiskNumber 2 -DriveLetter G -UseMaximumSize Format-Volume -DriveLetter G -FileSystem NTFS -AllocationUnitSize 65536
-
Sie können die Volume- und LUN-Erstellung mit dem PowerShell-Skript aus Anhang B automatisieren. LUNs können auch mit SnapCenter erstellt werden.
Sobald die Volumes und LUNs definiert sind, müssen Sie SnapCenter einrichten, um die Datenbankvorgänge durchführen zu können.
SnapCenter -Übersicht
NetApp SnapCenter ist eine Datenschutzsoftware der nächsten Generation für Tier-1-Unternehmensanwendungen. SnapCenter automatisiert und vereinfacht mit seiner zentralen Verwaltungsoberfläche die manuellen, komplexen und zeitaufwändigen Prozesse im Zusammenhang mit der Sicherung, Wiederherstellung und dem Klonen mehrerer Datenbanken und anderer Anwendungs-Workloads. SnapCenter nutzt NetApp -Technologien, darunter NetApp Snapshots, NetApp SnapMirror, SnapRestore und NetApp FlexClone. Diese Integration ermöglicht es IT-Organisationen, ihre Speicherinfrastruktur zu skalieren, immer strengere SLA-Verpflichtungen einzuhalten und die Produktivität der Administratoren im gesamten Unternehmen zu verbessern.
SnapCenter Server-Anforderungen
In der folgenden Tabelle sind die Mindestanforderungen für die Installation des SnapCenter -Servers und des Plug-Ins auf Microsoft Windows Server aufgeführt.
| Komponenten | Erfordernis |
|---|---|
Minimale CPU-Anzahl |
Vier Kerne/vCPUs |
Erinnerung |
Minimum: 8 GB. Empfohlen: 32 GB |
Stauraum |
Mindestspeicherplatz für die Installation: 10 GB. Mindestspeicherplatz für das Repository: 10 GB. |
Unterstütztes Betriebssystem |
|
Softwarepakete |
|
Ausführliche Informationen finden Sie unter"Platz- und Größenanforderungen" .
Informationen zur Versionskompatibilität finden Sie im "NetApp Interoperabilitätsmatrix-Tool" .
Datenbankspeicherlayout
Die folgende Abbildung zeigt einige Überlegungen zum Erstellen des Speicherlayouts der Microsoft SQL Server-Datenbank beim Sichern mit SnapCenter.
Bewährte Methoden
-
Platzieren Sie Datenbanken mit E/A-intensiven Abfragen oder mit großer Datenbankgröße (z. B. 500 GB oder mehr) für eine schnellere Wiederherstellung auf einem separaten Volume. Dieses Volumen sollte zusätzlich durch separate Jobs abgesichert werden.
-
Konsolidieren Sie kleine bis mittelgroße Datenbanken, die weniger kritisch sind oder geringere E/A-Anforderungen haben, auf einem einzigen Volume. Durch die Sicherung einer großen Anzahl von Datenbanken, die sich auf demselben Datenträger befinden, müssen weniger Snapshot-Kopien verwaltet werden. Es ist außerdem eine bewährte Methode, Microsoft SQL Server-Instanzen zu konsolidieren, um dieselben Volumes zu verwenden und so die Anzahl der erstellten Sicherungs-Snapshot-Kopien zu steuern.
-
Erstellen Sie separate LUNs zum Speichern von Volltextdateien und Dateistreaming-bezogenen Dateien.
-
Weisen Sie jedem Host separate LUNs zu, um Microsoft SQL Server-Protokollsicherungen zu speichern.
-
Systemdatenbanken, in denen die Metadatenkonfiguration des Datenbankservers und Auftragsdetails gespeichert sind, werden nicht häufig aktualisiert. Platzieren Sie Systemdatenbanken/tempdb auf separaten Laufwerken oder LUNs. Platzieren Sie Systemdatenbanken nicht auf demselben Datenträger wie die Benutzerdatenbanken. Für Benutzerdatenbanken gelten andere Sicherungsrichtlinien und die Häufigkeit der Benutzerdatenbanksicherungen ist für Systemdatenbanken nicht dieselbe.
-
Platzieren Sie für die Einrichtung der Microsoft SQL Server-Verfügbarkeitsgruppe die Daten- und Protokolldateien für Replikate in einer identischen Ordnerstruktur auf allen Knoten.
Neben dem Leistungsvorteil, der sich aus der Aufteilung des Benutzerdatenbanklayouts auf verschiedene Volumes ergibt, hat die Datenbank auch einen erheblichen Einfluss auf die zum Sichern und Wiederherstellen erforderliche Zeit. Durch die Verwendung separater Volumes für Daten- und Protokolldateien lässt sich die Wiederherstellungszeit im Vergleich zu einem Volume, auf dem mehrere Benutzerdatendateien gehostet werden, erheblich verkürzen. Ebenso ist bei Benutzerdatenbanken mit einer E/A-intensiven Anwendung eine Verlängerung der Sicherungszeit wahrscheinlich. Eine ausführlichere Erklärung zu Sicherungs- und Wiederherstellungsverfahren finden Sie weiter unten in diesem Dokument.
|
|
Ab SQL Server 2012 (11.x) können Systemdatenbanken (Master, Model, MSDB und TempDB) und Datenbank-Engine-Benutzerdatenbanken mit einem SMB-Dateiserver als Speicheroption installiert werden. Dies gilt sowohl für eigenständige SQL Server- als auch für SQL Server-Failoverclusterinstallationen. Dadurch können Sie FSx ONTAP mit all seinen Leistungs- und Datenverwaltungsfunktionen nutzen, einschließlich Volume-Kapazität, Leistungsskalierbarkeit und Datenschutzfunktionen, die SQL Server nutzen kann. Von den Anwendungsservern verwendete Freigaben müssen mit dem Eigenschaftssatz „ständig verfügbar“ konfiguriert werden und das Volume sollte im NTFS-Sicherheitsstil erstellt werden. NetApp Snapcenter kann nicht mit Datenbanken verwendet werden, die auf SMB-Freigaben von FSx ONTAP platziert sind. |
|
|
Für SQL Server-Datenbanken, die SnapCenter nicht zum Durchführen von Sicherungen verwenden, empfiehlt Microsoft, die Daten- und Protokolldateien auf separaten Laufwerken zu platzieren. Bei Anwendungen, die Daten gleichzeitig aktualisieren und anfordern, ist die Protokolldatei schreibintensiv und die Datendatei (je nach Anwendung) lese-/schreibintensiv. Für den Datenabruf wird die Protokolldatei nicht benötigt. Daher können Datenanforderungen aus der auf einem eigenen Laufwerk abgelegten Datendatei erfüllt werden. |
|
|
Wenn Sie eine neue Datenbank erstellen, empfiehlt Microsoft, separate Laufwerke für die Daten und Protokolle anzugeben. Um Dateien nach der Erstellung der Datenbank zu verschieben, muss die Datenbank offline genommen werden. Weitere Empfehlungen von Microsoft finden Sie unter „Speichern von Daten- und Protokolldateien auf separaten Laufwerken“. |
Installation und Einrichtung für SnapCenter
Folgen Sie den "Installieren des SnapCenter -Servers" Und "Installieren des SnapCenter -Plug-ins für Microsoft SQL Server" um SnapCenter zu installieren und einzurichten.
Führen Sie nach der Installation von SnapCenter die folgenden Schritte aus, um es einzurichten.
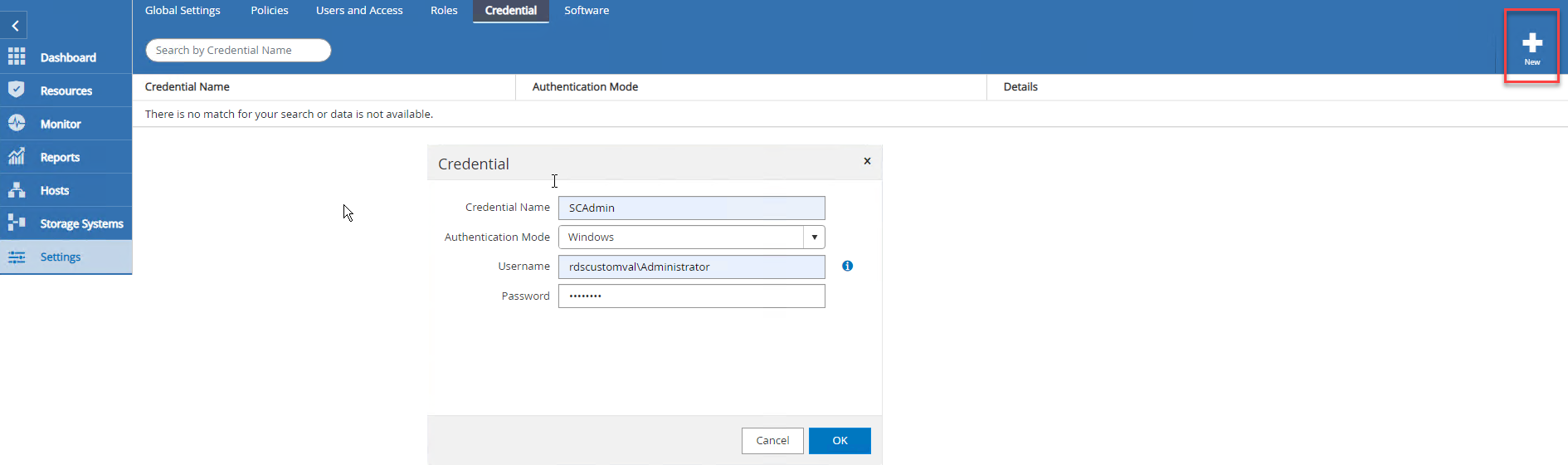
-
Um Anmeldeinformationen einzurichten, wählen Sie Einstellungen > Neu und geben Sie dann die Anmeldeinformationen ein.
-
Fügen Sie das Speichersystem hinzu, indem Sie Speichersysteme > Neu auswählen und die entsprechenden FSx ONTAP Speicherinformationen angeben.
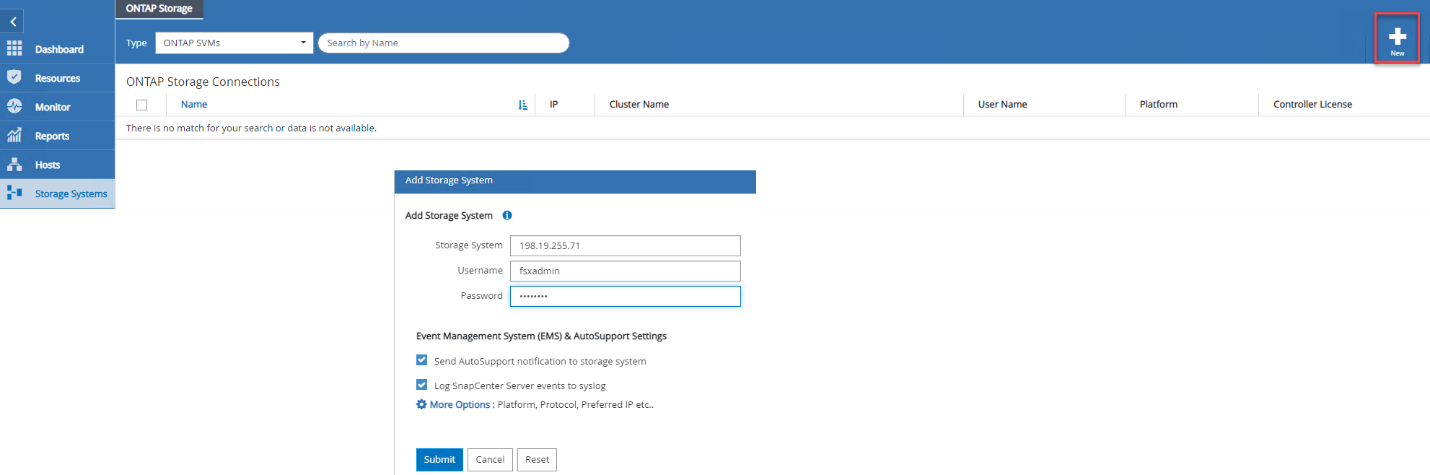
-
Fügen Sie Hosts hinzu, indem Sie Hosts > Hinzufügen auswählen und dann die Hostinformationen angeben. SnapCenter installiert das Windows- und SQL Server-Plug-In automatisch. Dieser Vorgang kann einige Zeit dauern.
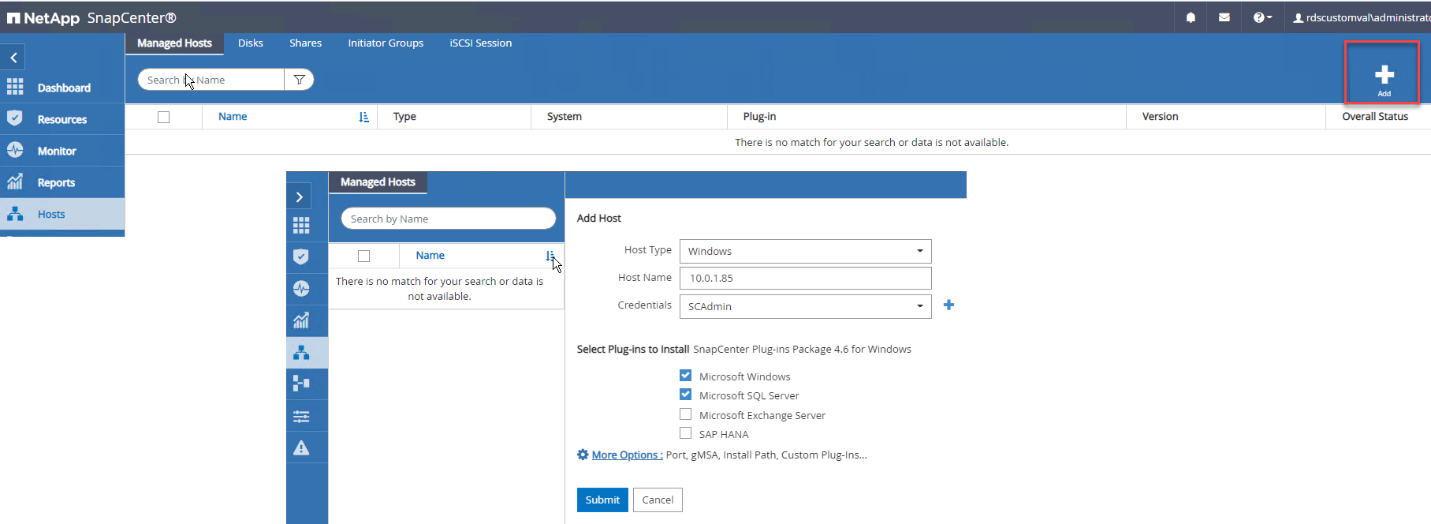
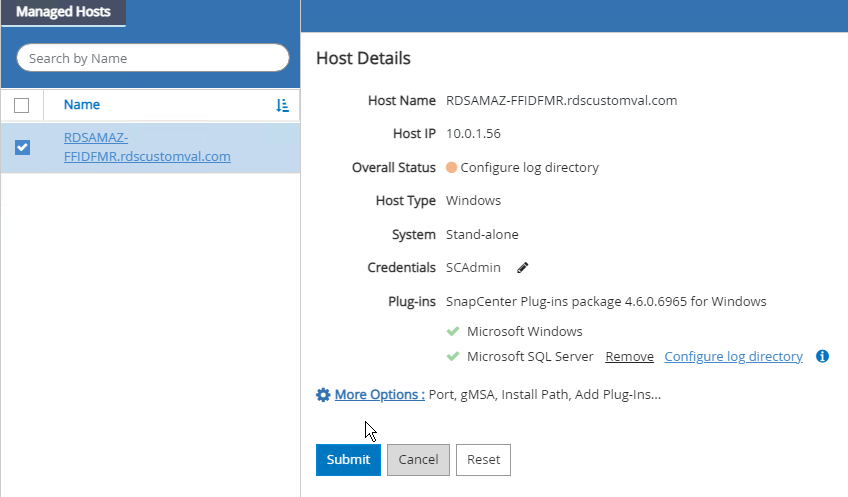
Nachdem alle Plug-ins installiert sind, müssen Sie das Protokollverzeichnis konfigurieren. Dies ist der Speicherort, an dem sich die Sicherungskopie des Transaktionsprotokolls befindet. Sie können das Protokollverzeichnis konfigurieren, indem Sie den Host auswählen und dann „Protokollverzeichnis konfigurieren“ auswählen.
|
|
SnapCenter verwendet ein Host-Protokollverzeichnis zum Speichern von Transaktionsprotokoll-Sicherungsdaten. Dies geschieht auf Host- und Instanzebene. Für jeden von SnapCenter verwendeten SQL Server-Host muss ein Host-Protokollverzeichnis konfiguriert sein, um Protokollsicherungen durchführen zu können. SnapCenter verfügt über ein Datenbank-Repository, sodass Metadaten im Zusammenhang mit Sicherungs-, Wiederherstellungs- oder Klonvorgängen in einem zentralen Datenbank-Repository gespeichert werden. |
Die Größe des Host-Protokollverzeichnisses wird wie folgt berechnet:
Größe des Host-Protokollverzeichnisses = Systemdatenbankgröße + (maximale DB-LDF-Größe × tägliche Protokolländerungsrate % × (Aufbewahrung der Snapshot-Kopie) ÷ (1 – LUN-Overhead-Speicherplatz %)
Die Formel zur Größenbestimmung des Host-Protokollverzeichnisses geht von Folgendem aus:
-
Eine Systemdatenbanksicherung, die die tempdb-Datenbank nicht enthält
-
Ein LUN-Overhead-Speicherplatz von 10 %. Platzieren Sie das Host-Protokollverzeichnis auf einem dedizierten Volume oder LUN. Die Datenmenge im Host-Protokollverzeichnis hängt von der Größe der Sicherungen und der Anzahl der Tage ab, die die Sicherungen aufbewahrt werden.
Wenn die LUNs bereits bereitgestellt wurden, können Sie den Bereitstellungspunkt auswählen, der das Host-Protokollverzeichnis darstellt.
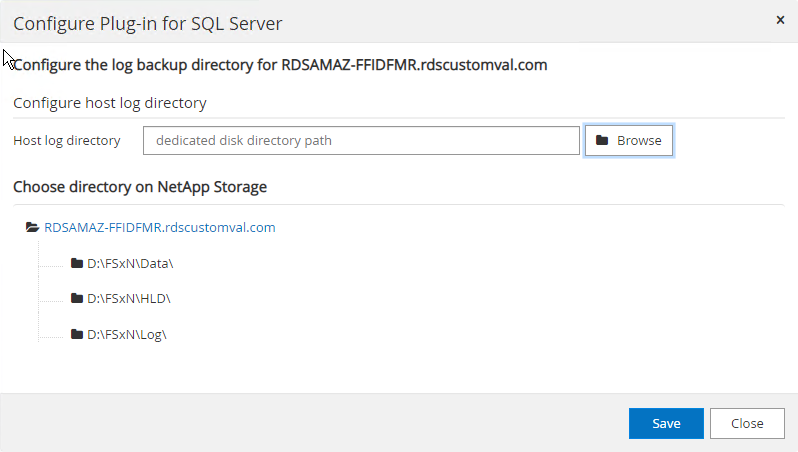
Jetzt können Sie Sicherungs-, Wiederherstellungs- und Klonvorgänge für SQL Server durchführen.
Datenbank sichern mit SnapCenter
Nachdem die Datenbank- und Protokolldateien auf den FSx ONTAP LUNs platziert wurden, kann SnapCenter zum Sichern der Datenbanken verwendet werden. Die folgenden Prozesse werden zum Erstellen einer vollständigen Sicherung verwendet.
Bewährte Vorgehensweisen
-
In SnapCenter -Begriffen kann RPO als Sicherungshäufigkeit definiert werden, z. B. wie oft Sie die Sicherung planen möchten, damit Sie den Datenverlust auf bis zu wenige Minuten reduzieren können. Mit SnapCenter können Sie Backups in Abständen von bis zu fünf Minuten planen. Es kann jedoch vorkommen, dass eine Sicherung während der Haupttransaktionszeiten oder wenn sich die Daten in der gegebenen Zeit schneller ändern, nicht innerhalb von fünf Minuten abgeschlossen werden kann. Eine bewährte Methode besteht darin, häufige Transaktionsprotokollsicherungen anstelle vollständiger Sicherungen einzuplanen.
-
Es gibt zahlreiche Ansätze zur Handhabung von RPO und RTO. Eine Alternative zu diesem Sicherungsansatz besteht darin, separate Sicherungsrichtlinien für Daten und Protokolle mit unterschiedlichen Intervallen zu haben. Planen Sie beispielsweise von SnapCenter aus Protokollsicherungen in 15-Minuten-Intervallen und Datensicherungen in 6-Stunden-Intervallen.
-
Verwenden Sie eine Ressourcengruppe für eine Sicherungskonfiguration zur Snapshot-Optimierung und die Anzahl der zu verwaltenden Jobs.
-
Wählen Sie Ressourcen und dann Microsoft SQL Server im Dropdown-Menü oben links. Wählen Sie Ressourcen aktualisieren.
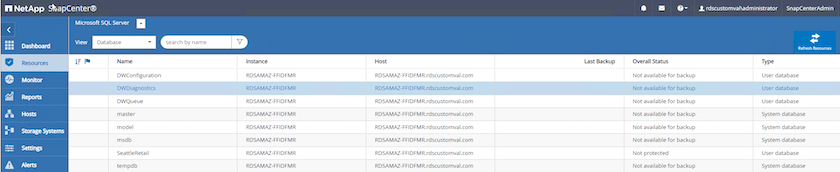
-
Wählen Sie die zu sichernde Datenbank aus und wählen Sie dann Weiter und (*), um die Richtlinie hinzuzufügen, falls noch keine erstellt wurde. Befolgen Sie die *Neue SQL Server-Sicherungsrichtlinie, um eine neue Richtlinie zu erstellen.
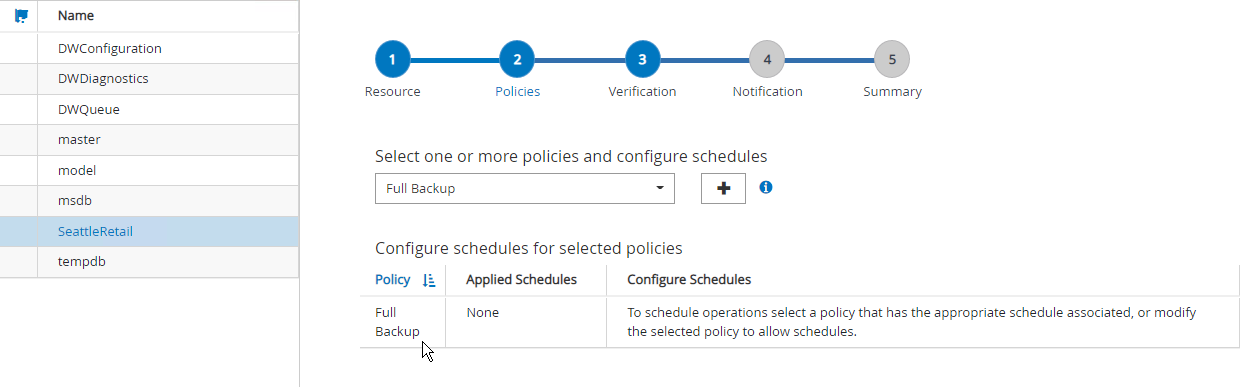
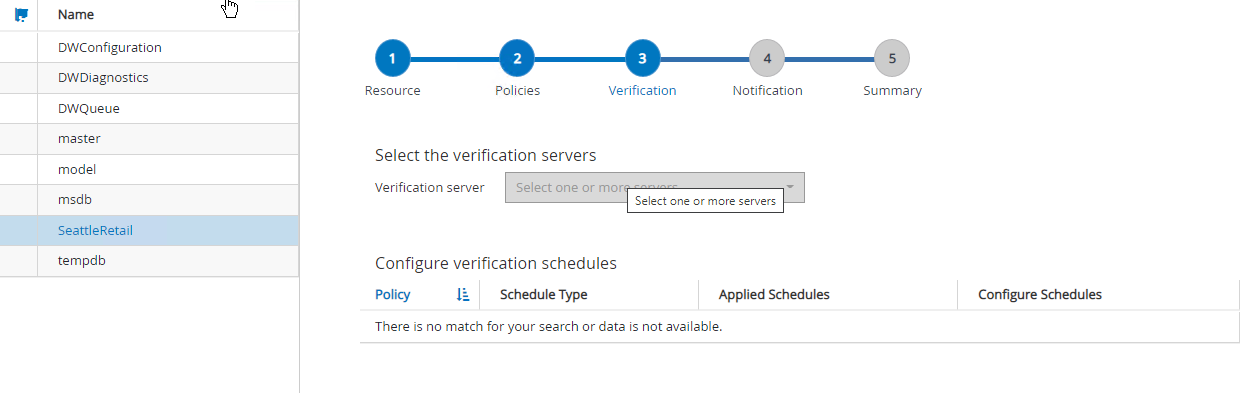
-
Wählen Sie bei Bedarf den Verifizierungsserver aus. Dieser Server ist der Server, auf dem SnapCenter DBCC CHECKDB ausführt, nachdem eine vollständige Sicherung erstellt wurde. Klicken Sie auf Weiter, um eine Benachrichtigung zu erhalten, und wählen Sie dann zur Überprüfung Zusammenfassung aus. Klicken Sie nach der Überprüfung auf Fertig.
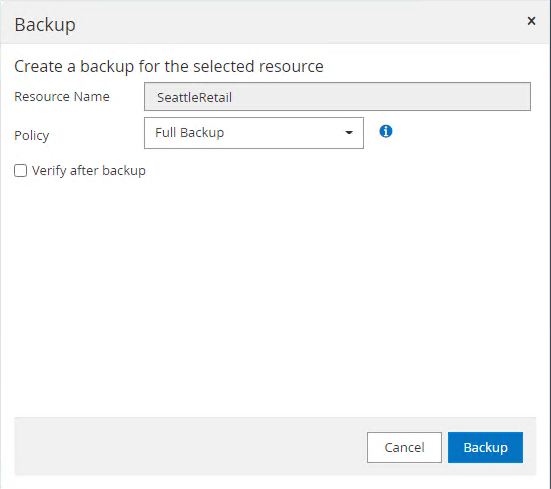
-
Klicken Sie auf Jetzt sichern, um die Sicherung zu testen. Wählen Sie im Popup-Fenster Backup aus.
-
Wählen Sie Überwachen, um zu überprüfen, ob die Sicherung abgeschlossen wurde.

-
Bewährte Vorgehensweisen
-
Sichern Sie die Transaktionsprotokollsicherung von SnapCenter , damit SnapCenter während des Wiederherstellungsvorgangs alle Sicherungsdateien lesen und automatisch der Reihe nach wiederherstellen kann.
-
Wenn für die Sicherung Produkte von Drittanbietern verwendet werden, wählen Sie „Sicherung kopieren“ in SnapCenter aus, um Probleme mit der Protokollsequenz zu vermeiden, und testen Sie die Wiederherstellungsfunktion, bevor Sie sie in die Produktion übernehmen.
Datenbank mit SnapCenter wiederherstellen
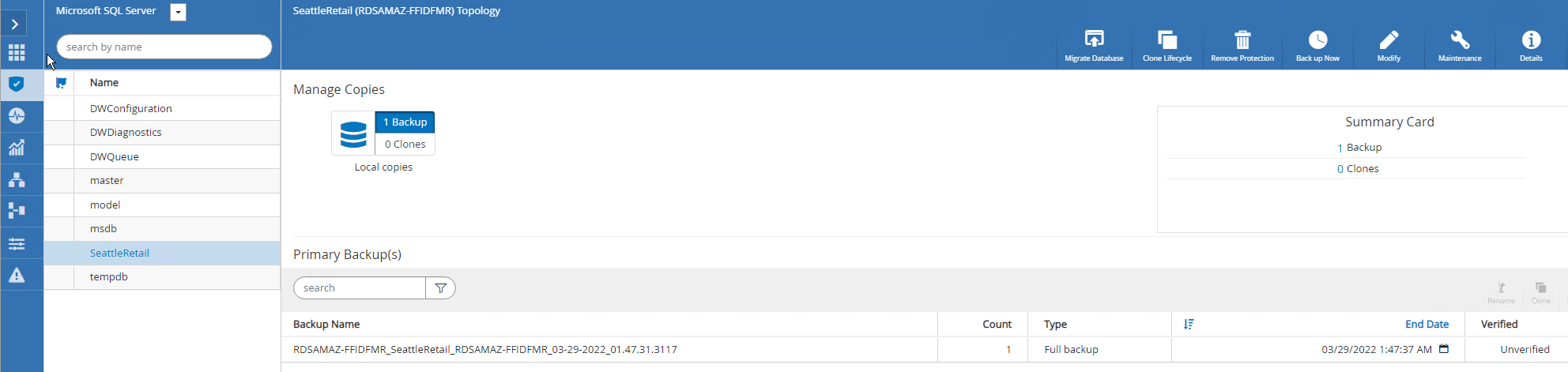
Einer der Hauptvorteile der Verwendung von FSx ONTAP mit SQL Server auf EC2 ist die Möglichkeit, auf jeder Datenbankebene eine schnelle und granulare Wiederherstellung durchzuführen.
Führen Sie die folgenden Schritte aus, um mit SnapCenter eine einzelne Datenbank auf einen bestimmten Zeitpunkt oder auf die Minute genau wiederherzustellen.
-
Wählen Sie „Ressourcen“ und dann die Datenbank aus, die Sie wiederherstellen möchten.
-
Wählen Sie den Sicherungsnamen aus, aus dem die Datenbank wiederhergestellt werden soll, und wählen Sie dann „Wiederherstellen“ aus.
-
Folgen Sie den Popup-Fenstern Wiederherstellen, um die Datenbank wiederherzustellen.
-
Wählen Sie Überwachen, um zu überprüfen, ob der Wiederherstellungsvorgang erfolgreich war.
Überlegungen zu einer Instanz mit einer großen Anzahl kleiner bis großer Datenbanken
SnapCenter kann eine große Anzahl umfangreicher Datenbanken in einer Instanz oder einer Gruppe von Instanzen innerhalb einer Ressourcengruppe sichern. Die Größe einer Datenbank ist nicht der Hauptfaktor für die Sicherungszeit. Die Dauer einer Sicherung kann je nach Anzahl der LUNs pro Volume, der Auslastung des Microsoft SQL Servers, der Gesamtzahl der Datenbanken pro Instanz und insbesondere der E/A-Bandbreite und -Nutzung variieren. Beim Konfigurieren der Richtlinie zum Sichern von Datenbanken einer Instanz oder Ressourcengruppe empfiehlt NetApp , die maximale Anzahl der pro Snapshot-Kopie gesicherten Datenbanken auf 100 pro Host zu beschränken. Stellen Sie sicher, dass die Gesamtzahl der Snapshot-Kopien das Limit von 1.023 Kopien nicht überschreitet.
NetApp empfiehlt außerdem, die Anzahl parallel ausgeführter Sicherungsjobs zu begrenzen, indem Sie die Anzahl der Datenbanken gruppieren, anstatt für jede Datenbank oder Instanz mehrere Jobs zu erstellen. Um eine optimale Leistung der Sicherungsdauer zu erzielen, reduzieren Sie die Anzahl der Sicherungsaufträge auf eine Zahl, mit der etwa 100 oder weniger Datenbanken gleichzeitig gesichert werden können.
Wie bereits erwähnt, ist die E/A-Nutzung ein wichtiger Faktor im Sicherungsprozess. Der Sicherungsvorgang muss mit der Stilllegung warten, bis alle E/A-Vorgänge einer Datenbank abgeschlossen sind. Datenbanken mit sehr intensiven E/A-Vorgängen sollten auf einen anderen Sicherungszeitpunkt verschoben oder von anderen Sicherungsaufträgen isoliert werden, um zu vermeiden, dass andere zu sichernde Ressourcen innerhalb derselben Ressourcengruppe beeinträchtigt werden.
Legen Sie für eine Umgebung mit sechs Microsoft SQL Server-Hosts, die 200 Datenbanken pro Instanz hosten, und vorausgesetzt, dass vier LUNs pro Host und eine LUN pro erstelltem Volume vorhanden sind, die vollständige Sicherungsrichtlinie mit der maximalen Anzahl von Datenbanken fest, die pro Snapshot-Kopie auf 100 gesichert werden können. Zweihundert Datenbanken auf jeder Instanz sind als 200 Datendateien angelegt, die gleichmäßig auf zwei LUNs verteilt sind, und 200 Protokolldateien sind gleichmäßig auf zwei LUNs verteilt, was 100 Dateien pro LUN pro Volume entspricht.
Planen Sie drei Sicherungsaufträge, indem Sie drei Ressourcengruppen erstellen, die jeweils zwei Instanzen mit insgesamt 400 Datenbanken gruppieren.
Durch die parallele Ausführung aller drei Sicherungsaufträge werden 1.200 Datenbanken gleichzeitig gesichert. Abhängig von der Serverauslastung und der E/A-Nutzung können die Start- und Endzeit jeder Instanz variieren. In diesem Fall werden insgesamt 24 Snapshot-Kopien erstellt.
Zusätzlich zur vollständigen Sicherung empfiehlt NetApp , für kritische Datenbanken eine Transaktionsprotokollsicherung zu konfigurieren. Stellen Sie sicher, dass die Datenbankeigenschaft auf das vollständige Wiederherstellungsmodell eingestellt ist.
Bewährte Methoden
-
Schließen Sie die Datenbank „tempdb“ nicht in eine Sicherung ein, da die darin enthaltenen Daten temporär sind. Platzieren Sie tempdb auf einer LUN oder einer SMB-Freigabe, die sich in einem Speichersystemvolume befindet, in dem keine Snapshot-Kopien erstellt werden.
-
Eine Microsoft SQL Server-Instanz mit einer E/A-intensiven Anwendung sollte in einem anderen Sicherungsauftrag isoliert werden, um die Gesamtsicherungszeit für andere Ressourcen zu reduzieren.
-
Begrenzen Sie die Anzahl der gleichzeitig zu sichernden Datenbanken auf etwa 100 und staffeln Sie die verbleibenden Datenbanksicherungen, um einen gleichzeitigen Prozess zu vermeiden.
-
Verwenden Sie in der Ressourcengruppe den Namen der Microsoft SQL Server-Instanz anstelle mehrerer Datenbanken, da SnapCenter bei der Erstellung neuer Datenbanken in der Microsoft SQL Server-Instanz automatisch eine neue Datenbank für die Sicherung in Betracht zieht.
-
Wenn Sie die Datenbankkonfiguration ändern, beispielsweise das Datenbankwiederherstellungsmodell in das vollständige Wiederherstellungsmodell ändern, führen Sie sofort eine Sicherung durch, um aktuelle Wiederherstellungsvorgänge zu ermöglichen.
-
SnapCenter kann außerhalb von SnapCenter erstellte Transaktionsprotokollsicherungen nicht wiederherstellen.
-
Stellen Sie beim Klonen von FlexVol -Volumes sicher, dass Sie über ausreichend Speicherplatz für die Klonmetadaten verfügen.
-
Achten Sie beim Wiederherstellen von Datenbanken darauf, dass auf dem Volume ausreichend Speicherplatz zur Verfügung steht.
-
Erstellen Sie eine separate Richtlinie, um Systemdatenbanken mindestens einmal pro Woche zu verwalten und zu sichern.
Klonen von Datenbanken mit SnapCenter
Um eine Datenbank an einem anderen Speicherort in einer Entwicklungs- oder Testumgebung wiederherzustellen oder eine Kopie für Geschäftsanalysezwecke zu erstellen, besteht die bewährte Methode von NetApp darin, die Klonmethode zu nutzen, um eine Kopie der Datenbank auf derselben oder einer anderen Instanz zu erstellen.
Das Klonen von Datenbanken mit 500 GB auf einer iSCSI-Festplatte, die in einer FSx ONTAP Umgebung gehostet wird, dauert normalerweise weniger als fünf Minuten. Nachdem das Klonen abgeschlossen ist, kann der Benutzer alle erforderlichen Lese-/Schreibvorgänge an der geklonten Datenbank durchführen. Die meiste Zeit wird für das Scannen der Festplatte (Diskpart) benötigt. Der NetApp -Klonvorgang dauert normalerweise weniger als 2 Minuten, unabhängig von der Größe der Datenbanken.
Das Klonen einer Datenbank kann mit zwei Methoden durchgeführt werden: Sie können einen Klon aus der neuesten Sicherung erstellen oder die Klon-Lebenszyklusverwaltung verwenden, durch die die neueste Kopie auf der sekundären Instanz verfügbar gemacht werden kann.
Mit SnapCenter können Sie die Klonkopie auf der erforderlichen Festplatte bereitstellen, um das Format der Ordnerstruktur auf der sekundären Instanz beizubehalten und weiterhin Sicherungsaufträge zu planen.
Klonen Sie Datenbanken mit dem neuen Datenbanknamen in derselben Instanz
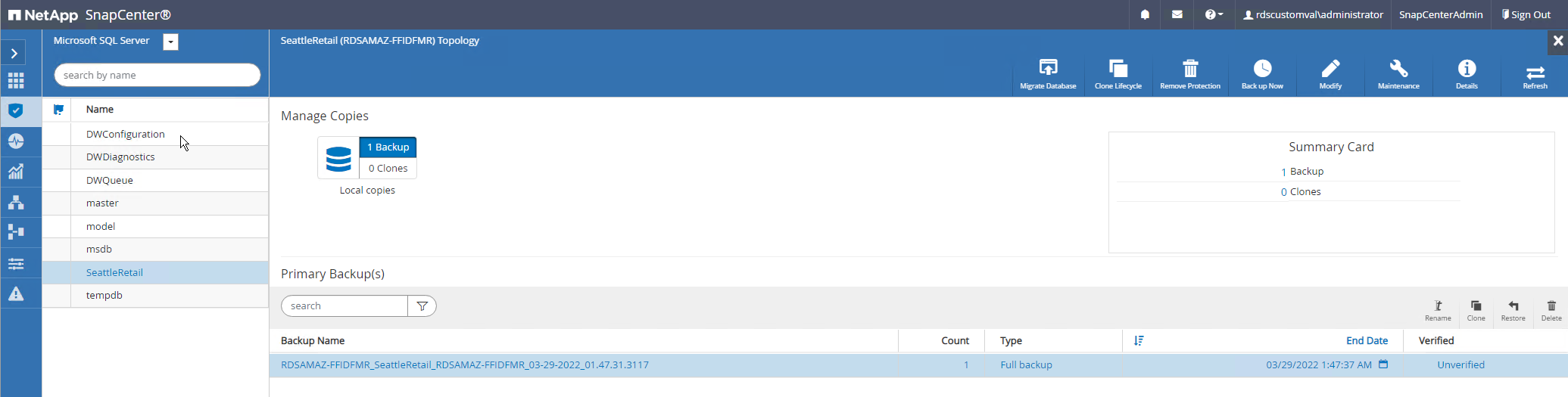
Mit den folgenden Schritten können Sie Datenbanken auf den neuen Datenbanknamen in derselben SQL-Serverinstanz klonen, die auf EC2 ausgeführt wird:
-
Wählen Sie „Ressourcen“ und dann die Datenbank aus, die geklont werden muss.
-
Wählen Sie den Sicherungsnamen aus, den Sie klonen möchten, und wählen Sie „Klonen“.
-
Befolgen Sie die Klonanweisungen in den Sicherungsfenstern, um den Klonvorgang abzuschließen.
-
Wählen Sie „Überwachen“, um sicherzustellen, dass das Klonen abgeschlossen ist.
Klonen Sie Datenbanken in die neue SQL Server-Instanz, die auf EC2 ausgeführt wird
Mit den folgenden Schritten werden Datenbanken auf die neue SQL-Serverinstanz geklont, die auf EC2 ausgeführt wird:
-
Erstellen Sie einen neuen SQL-Server auf EC2 im selben VPC.
-
Aktivieren Sie das iSCSI-Protokoll und MPIO und richten Sie dann die iSCSI-Verbindung zu FSx ONTAP ein, indem Sie die Schritte 3 und 4 im Abschnitt „Volumes und LUNs für SQL Server erstellen“ befolgen.
-
Fügen Sie einen neuen SQL Server auf EC2 in SnapCenter hinzu, indem Sie Schritt 3 im Abschnitt „Installation und Einrichtung von SnapCenter“ befolgen.
-
Wählen Sie Ressource > Instanz anzeigen und dann Ressource aktualisieren.
-
Wählen Sie „Ressourcen“ und dann die Datenbank aus, die Sie klonen möchten.
-
Wählen Sie den Sicherungsnamen aus, den Sie klonen möchten, und wählen Sie dann „Klonen“ aus.
-
Befolgen Sie die Anweisungen zum Klonen aus der Sicherung, indem Sie die neue SQL Server-Instanz auf EC2 und den Instanznamen angeben, um den Klonvorgang abzuschließen.
-
Wählen Sie „Überwachen“, um sicherzustellen, dass das Klonen abgeschlossen ist.

Um mehr über diesen Vorgang zu erfahren, sehen Sie sich das folgende Video an:
Anhänge
Anhang A: YAML-Datei zur Verwendung in der Cloud Formation-Vorlage
Die folgende YAML-Datei kann mit der Cloud Formation-Vorlage in der AWS-Konsole verwendet werden.
Um die ISCSI-LUN-Erstellung und die NetApp SnapCenter Installation mit PowerShell zu automatisieren, klonen Sie das Repo von "dieser GitHub-Link" .
Anhang B: Powershell-Skripte zum Bereitstellen von Volumes und LUNs
Das folgende Skript wird zum Bereitstellen von Volumes und LUNs sowie zum Einrichten von iSCSI basierend auf den oben angegebenen Anweisungen verwendet. Es gibt zwei PowerShell-Skripte:
-
_EnableMPIO.ps1
Function Install_MPIO_ssh {
$hostname = $env:COMPUTERNAME
$hostname = $hostname.Replace('-','_')
#Add schedule action for the next step
$path = Get-Location
$path = $path.Path + '\2_CreateDisks.ps1'
$arg = '-NoProfile -WindowStyle Hidden -File ' +$path
$schAction = New-ScheduledTaskAction -Execute "Powershell.exe" -Argument $arg
$schTrigger = New-ScheduledTaskTrigger -AtStartup
$schPrincipal = New-ScheduledTaskPrincipal -UserId "NT AUTHORITY\SYSTEM" -LogonType ServiceAccount -RunLevel Highest
$return = Register-ScheduledTask -Action $schAction -Trigger $schTrigger -TaskName "Create Vols and LUNs" -Description "Scheduled Task to run configuration Script At Startup" -Principal $schPrincipal
#Install -Module Posh-SSH
Write-host 'Enable MPIO and SSH for PowerShell' -ForegroundColor Yellow
$return = Find-PackageProvider -Name 'Nuget' -ForceBootstrap -IncludeDependencies
$return = Find-Module PoSH-SSH | Install-Module -Force
#Install Multipath-IO with PowerShell using elevated privileges in Windows Servers
Write-host 'Enable MPIO' -ForegroundColor Yellow
$return = Install-WindowsFeature -name Multipath-IO -Restart
}
Install_MPIO_ssh
Remove-Item -Path $MyInvocation.MyCommand.Source-
_CreateDisks.ps1
....
#Enable MPIO and Start iSCSI Service
Function PrepISCSI {
$return = Enable-MSDSMAutomaticClaim -BusType iSCSI
#Start iSCSI service with PowerShell using elevated privileges in Windows Servers
$return = Start-service -Name msiscsi
$return = Set-Service -Name msiscsi -StartupType Automatic
}
Function Create_igroup_vols_luns ($fsxN){
$hostname = $env:COMPUTERNAME
$hostname = $hostname.Replace('-','_')
$volsluns = @()
for ($i = 1;$i -lt 10;$i++){
if ($i -eq 9){
$volsluns +=(@{volname=('v_'+$hostname+'_log');volsize=$fsxN.logvolsize;lunname=('l_'+$hostname+'_log');lunsize=$fsxN.loglunsize})
} else {
$volsluns +=(@{volname=('v_'+$hostname+'_data'+[string]$i);volsize=$fsxN.datavolsize;lunname=('l_'+$hostname+'_data'+[string]$i);lunsize=$fsxN.datalunsize})
}
}
$secStringPassword = ConvertTo-SecureString $fsxN.password -AsPlainText -Force
$credObject = New-Object System.Management.Automation.PSCredential ($fsxN.login, $secStringPassword)
$igroup = 'igrp_'+$hostname
#Connect to FSx N filesystem
$session = New-SSHSession -ComputerName $fsxN.svmip -Credential $credObject -AcceptKey:$true
#Create igroup
Write-host 'Creating igroup' -ForegroundColor Yellow
#Find Windows initiator Name with PowerShell using elevated privileges in Windows Servers
$initport = Get-InitiatorPort | select -ExpandProperty NodeAddress
$sshcmd = 'igroup create -igroup ' + $igroup + ' -protocol iscsi -ostype windows -initiator ' + $initport
$ret = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
#Create vols
Write-host 'Creating Volumes' -ForegroundColor Yellow
foreach ($vollun in $volsluns){
$sshcmd = 'vol create ' + $vollun.volname + ' -aggregate aggr1 -size ' + $vollun.volsize #+ ' -vserver ' + $vserver
$return = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
}
#Create LUNs and mapped LUN to igroup
Write-host 'Creating LUNs and map to igroup' -ForegroundColor Yellow
foreach ($vollun in $volsluns){
$sshcmd = "lun create -path /vol/" + $vollun.volname + "/" + $vollun.lunname + " -size " + $vollun.lunsize + " -ostype Windows_2008 " #-vserver " +$vserver
$return = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
#map all luns to igroup
$sshcmd = "lun map -path /vol/" + $vollun.volname + "/" + $vollun.lunname + " -igroup " + $igroup
$return = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
}
}
Function Connect_iSCSI_to_SVM ($TargetPortals){
Write-host 'Online, Initialize and format disks' -ForegroundColor Yellow
#Connect Windows Server to svm with iSCSI target.
foreach ($TargetPortal in $TargetPortals) {
New-IscsiTargetPortal -TargetPortalAddress $TargetPortal
for ($i = 1; $i -lt 5; $i++){
$return = Connect-IscsiTarget -IsMultipathEnabled $true -IsPersistent $true -NodeAddress (Get-iscsiTarget | select -ExpandProperty NodeAddress)
}
}
}
Function Create_Partition_Format_Disks{
#Create Partion and format disk
$disks = Get-Disk | where PartitionStyle -eq raw
foreach ($disk in $disks) {
$return = Initialize-Disk $disk.Number
$partition = New-Partition -DiskNumber $disk.Number -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -AllocationUnitSize 65536 -Confirm:$false -Force
#$return = Format-Volume -DriveLetter $partition.DriveLetter -FileSystem NTFS -AllocationUnitSize 65536
}
}
Function UnregisterTask {
Unregister-ScheduledTask -TaskName "Create Vols and LUNs" -Confirm:$false
}
Start-Sleep -s 30
$fsxN = @{svmip ='198.19.255.153';login = 'vsadmin';password='net@pp11';datavolsize='10GB';datalunsize='8GB';logvolsize='8GB';loglunsize='6GB'}
$TargetPortals = ('10.2.1.167', '10.2.2.12')
PrepISCSI
Create_igroup_vols_luns $fsxN
Connect_iSCSI_to_SVM $TargetPortals
Create_Partition_Format_Disks
UnregisterTask
Remove-Item -Path $MyInvocation.MyCommand.Source
....
Führen Sie die Datei aus EnableMPIO.ps1 Das erste und das zweite Skript werden nach dem Neustart des Servers automatisch ausgeführt. Diese PowerShell-Skripte können nach ihrer Ausführung aufgrund des Anmeldeinformationszugriffs auf die SVM entfernt werden.
Wo Sie weitere Informationen finden
-
Amazon FSx ONTAP
-
Erste Schritte mit FSx ONTAP
-
Übersicht über die SnapCenter -Oberfläche
-
Tour durch die Optionen des SnapCenter -Navigationsbereichs
-
Einrichten des SnapCenter 4.0 für das SQL Server-Plug-In
-
So sichern und wiederherstellen Sie Datenbanken mit SnapCenter mit SQL Server-Plug-In
-
So klonen Sie eine Datenbank mit SnapCenter mit SQL Server-Plug-In