

Daten-zu-Modell-Rückverfolgbarkeit mit NetApp und MLflow
 Änderungen vorschlagen
Änderungen vorschlagen
Der "NetApp DataOps Toolkit für Kubernetes" kann in Verbindung mit den Experimentverfolgungsfunktionen von MLflow verwendet werden, um die Rückverfolgbarkeit von Code zu Datensatz, Datensatz zu Modell oder Arbeitsplatz zu Modell zu implementieren.
Im Beispielnotizbuch wurden folgende Bibliotheken verwendet:
Voraussetzungen
Um die Rückverfolgbarkeit von Code-Datensatz-Modellen oder Arbeitsbereichen zu Modellen zu implementieren, erstellen Sie einfach mithilfe des DataOps Toolkits einen Snapshot Ihres Datensatzes oder Workspace-Volumes als Teil Ihres Trainingslaufs, wie im folgenden Beispiel gezeigt, ein Codebeispiel. Mit diesem Code werden der Name des Datenvolumes und der Snapshot-Name als Tags gespeichert, die mit dem spezifischen Trainingslauf verknüpft sind, den Sie auf Ihrem MLflow-Experimentverfolgungsserver protokollieren.
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")Der oben genannte Codeschnipsel protokolliert die Snapshot-IDs an den MLflow Experiment Tracking Server, der verwendet werden kann, um zurück zu dem spezifischen Datensatz und Modell, die für das Training des Modells verwendet wurden zurückverfolgen. Dies ermöglicht es Ihnen, zurück zu den spezifischen Datensatz und Modell, die für das Training des Modells verwendet wurden, sowie den spezifischen Code, der verwendet wurde, um die Daten vorverarbeiten, tokenize die Eingabedatei, laden Sie den Tokenizer und Modell, kodieren, generieren und dekodieren "NLTK"Sie den Text, speichern Sie das Modell, finetune das Modell, bewerten Sie das Modell mit Perplexity Scores, und protokollieren Sie die Hyperparameter und Metriken zu MLflow. Die folgende Abbildung zeigt zum Beispiel den mittleren quadratischen Fehler (MSE) eines scikit-Lernmodells für verschiedene Versuchsläufe:

Für Datenanalysen, Geschäftsbereichsleiter und Führungskräfte ist es einfach zu verstehen, welches Modell unter Ihren besonderen Einschränkungen, Einstellungen, Zeiträumen und anderen Umständen am besten funktioniert. Weitere Informationen zum Vorverarbeiten, Tokenisieren, Laden, Kodieren, Generieren, Dekodieren, Speichern, Finetunen und Evaluieren des Modells dotk-mlflow netapp_dataops.k8s finden Sie im Beispiel für verpackte Python im Repository.
Weitere Informationen zum Erstellen von Snapshots Ihres Datensatzes oder des JupyterLab-Arbeitsbereichs finden Sie im "NetApp DataOps Toolkit-Seite".
In Bezug auf die trainierten Modelle wurden im dotk-mlflow Notebook folgende Modelle verwendet:
Modelle
-
"GPT2LMHeadModel": Der GPT2 Modelltransformator mit einem Sprachmodellierungskopf oben (lineare Schicht mit Gewichten, die an die Eingangseingaben gebunden sind). Es handelt sich um ein Transformatormodell, das auf einem großen Korpus von Textdaten vortrainiert und mit einem bestimmten Datensatz abgearbeitet wurde. Wir haben das Standard-GPT2-Modell "Warnmaske"für das Batching von Eingabesequenzen mit entsprechendem Tokenizer für Ihr Wunschmodell verwendet.
-
"Phi-2": Phi-2 ist ein Transformator mit 2.7 Milliarden Parametern. Es wurde mit denselben Datenquellen wie Phi-1.5 trainiert, ergänzt um eine neue Datenquelle, die aus verschiedenen synthetischen NLP-Texten und gefilterten Websites besteht (aus Sicherheitsgründen und Bildungswert).
-
"XLNet (Modell mit basierter Größe)": XLNet-Modell auf Englisch vortrainiert. Es wurde in dem Papier "XLNet: Generalisierte autoregressive Vorschulung für das Sprachverständnis" von Yang et al. Eingeführt und erstmals in diesem veröffentlicht"Repository".
Das Ergebnis "Modellregistrierung in MLflow"enthält die folgenden zufälligen Forest-Modelle, Versionen und Tags:
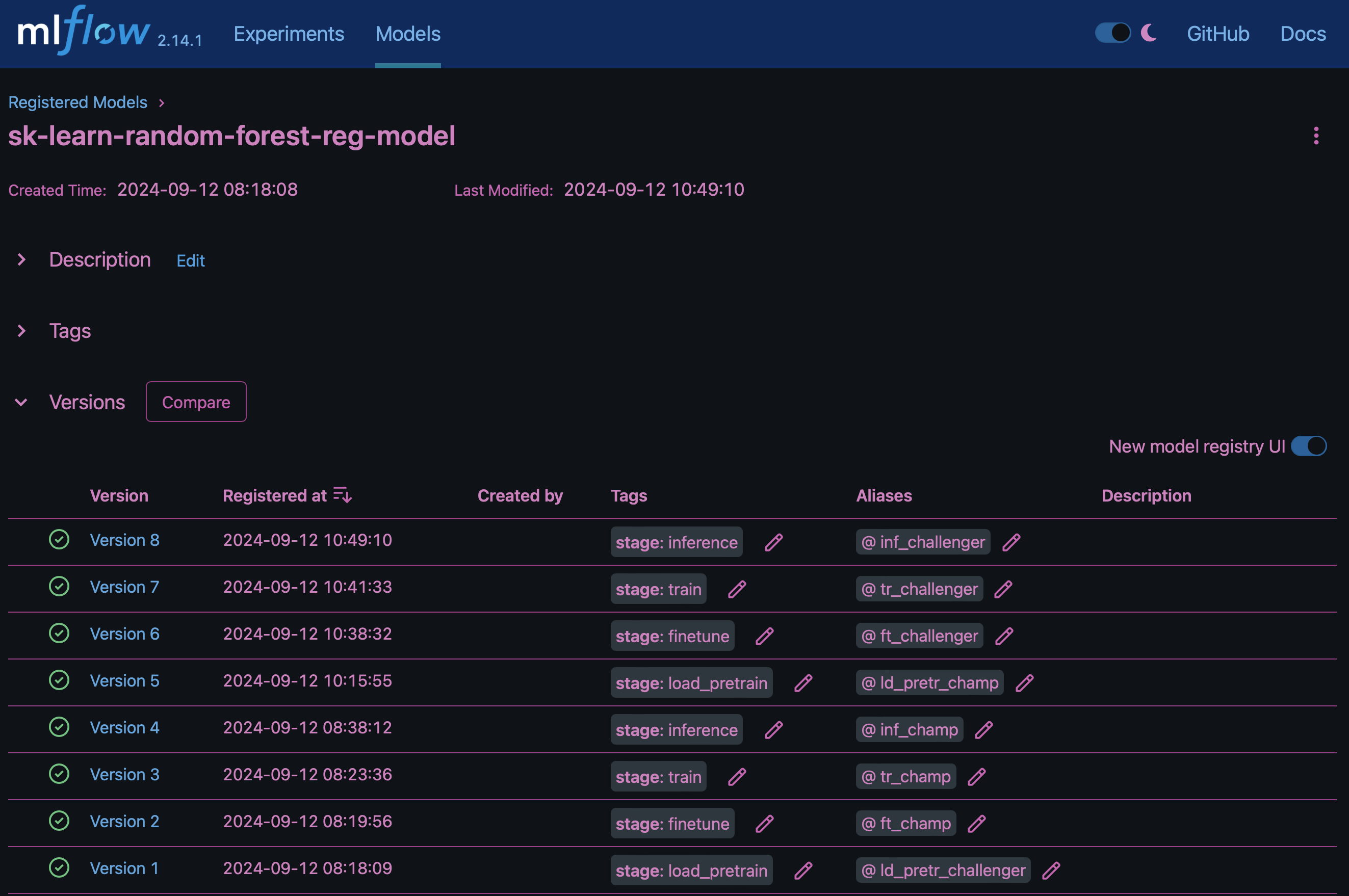
Um das Modell über Kubernetes auf einem Inferenzserver bereitzustellen, führen Sie einfach das folgende Jupyter Notebook aus. Beachten Sie, dass dotk-mlflow wir in diesem Beispiel anstelle des Pakets die Architektur des zufälligen Forest Regression-Modells ändern, um den mittleren quadratischen Fehler (MSE) im Anfangsmodell zu minimieren und daher mehrere Versionen dieses Modells in unserer Modellregistrierung zu erstellen.
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)Das Ausführungsergebnis Ihrer Jupyter Notebook-Zelle sollte dem folgenden ähneln, wobei das Modell als Version 3 in der Modellregistrierung registriert wird:
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
In der Modellregistrierung ist es möglich, nach dem Speichern der gewünschten Modelle, Versionen und Tags auf den spezifischen Datensatz, das Modell und den Code zurückzugreifen, der zum Trainieren des Modells verwendet wurde, sowie auf den spezifischen Code, der zum Verarbeiten der Daten verwendet wurde, den Tokenizer und das Modell zu laden, den Text zu kodieren, zu generieren und zu dekodieren, das Modell zu speichern, das Modell mit NLTK Perplexity Scores oder anderen geeigneten Hypertab-Parametern auszuwerten snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun.
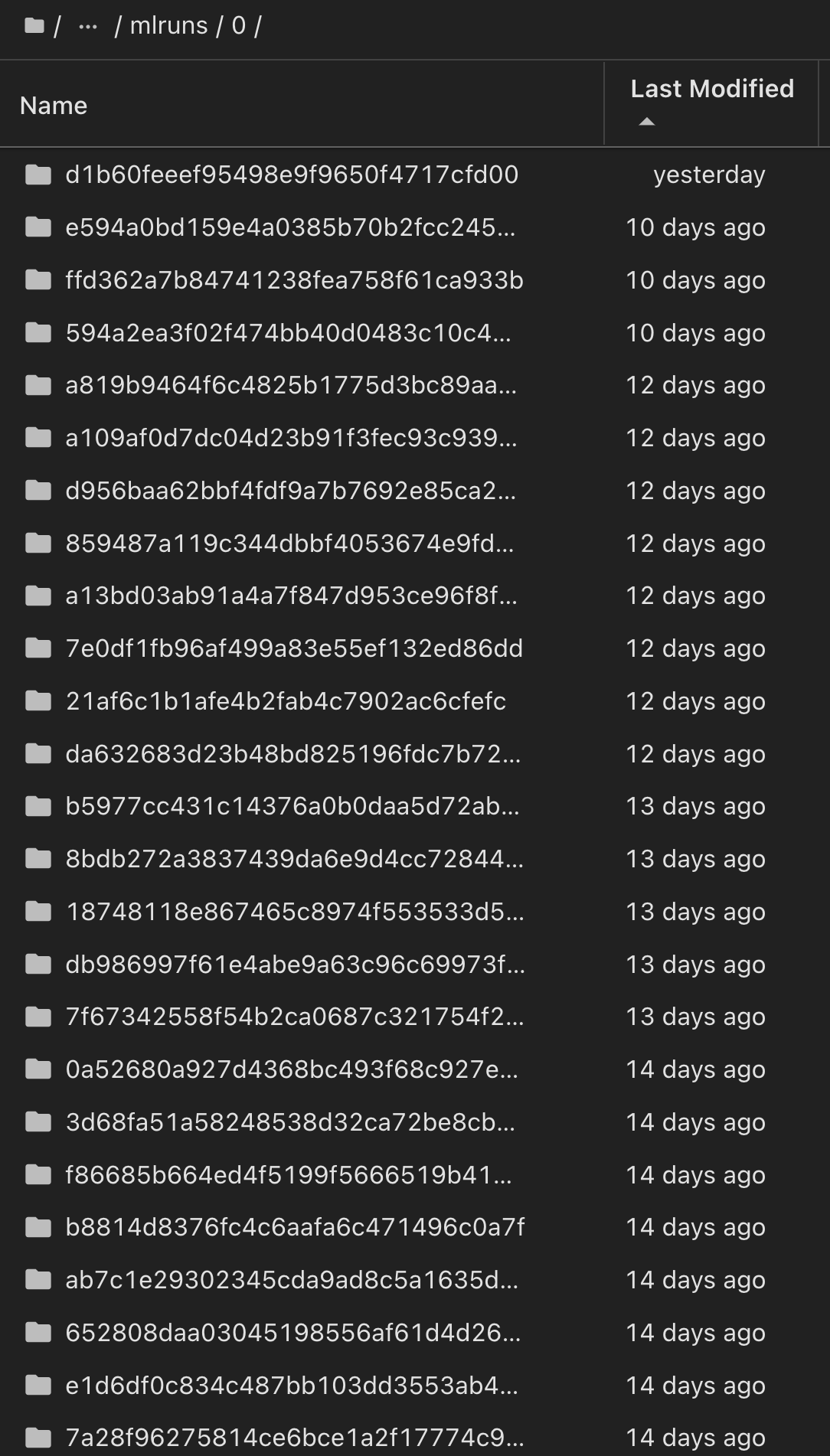
In ähnlicher Weise phi-2_finetuned_model torch können wir für unsere, deren quantifizierte Gewichte über GPU oder vGPU mithilfe der Bibliothek berechnet wurden, die folgenden Zwischenartefakte prüfen, die die Performance-Optimierung, Skalierbarkeit (Durchsatz/SLA-Garantie) und Kostensenkung des gesamten Workflows ermöglichen:
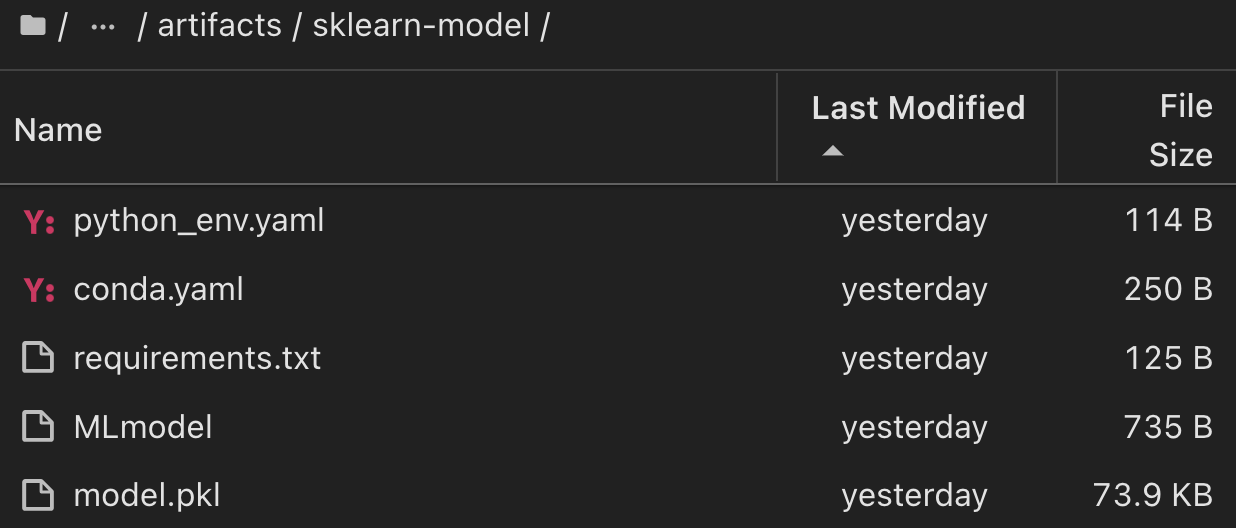
Bei einem einzelnen Experiment mit Scikit-learn und MLflow zeigt die folgende Abbildung die generierten Artefakte, conda Umgebung, MLmodel Datei und MLmodel Verzeichnis an:
Kunden können Tags angeben, z. B. „Standard“, „Phase“, „Prozess“, „Engpass“, um verschiedene Eigenschaften ihrer AI-Workflow-Durchläufe contributors zu organisieren, die neuesten Ergebnisse zu notieren oder den Entwicklerfortschritt des Data Science-Teams zu verfolgen. Wenn für das Standard-Tag " ", Ihre gespeicherten mlflow.log-model.history, , mlflow.runName, mlflow.source.type mlflow.source.name und mlflow.user unter JupyterHub aktuell aktiven Datei Navigator Registerkarte:
Schließlich haben die Benutzer ihren eigenen angegebenen Jupyter Workspace, der versioniert und in einer Persistent Volume Claim (PVC) im Kubernetes-Cluster gespeichert wird. Die folgende Abbildung zeigt den Jupyter Workspace, der das netapp_dataops.k8s Python-Paket enthält, und die Ergebnisse eines erfolgreich erstellten VolumeSnapshot:
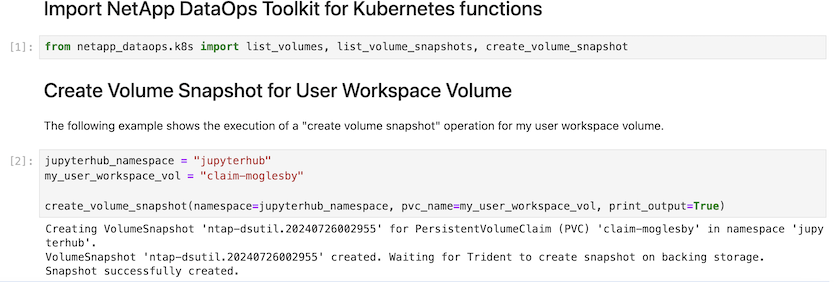
Unsere branchenweit bewährten Snapshot® und andere Technologien wurden für Datensicherung, Verschiebung und effiziente Komprimierung der Enterprise-Klasse eingesetzt. Weitere KI-Anwendungsfälle finden Sie in der "NetApp AIPod" Dokumentation.