

Übersicht zur Lösungsüberprüfung
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt haben wir SQL-Testabfragen aus mehreren Quellen ausgeführt, um die Funktionalität zu überprüfen und den Spillover zum NetApp -Speicher zu testen und zu verifizieren.
SQL-Abfrage im Objektspeicher
-
Stellen Sie den Speicher in dremio.env auf 250 GB pro Server ein
root@hadoopmaster:~# for i in hadoopmaster hadoopnode1 hadoopnode2 hadoopnode3 hadoopnode4; do ssh $i "hostname; grep -i DREMIO_MAX_MEMORY_SIZE_MB /opt/dremio/conf/dremio-env; cat /proc/meminfo | grep -i memtotal"; done hadoopmaster #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515760 kB hadoopnode1 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515860 kB hadoopnode2 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515864 kB hadoopnode3 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 264004556 kB node4 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515484 kB root@hadoopmaster:~#
-
Überprüfen Sie den Überlaufspeicherort (${DREMIO_HOME}"/dremiocache) in der Datei dremio.conf und den Speicherdetails.
paths: { # the local path for dremio to store data. local: ${DREMIO_HOME}"/dremiocache" # the distributed path Dremio data including job results, downloads, uploads, etc #dist: "hdfs://hadoopmaster:9000/dremiocache" dist: "dremioS3:///dremioconf" } services: { coordinator.enabled: true, coordinator.master.enabled: true, executor.enabled: false, flight.use_session_service: false } zookeeper: "10.63.150.130:2181,10.63.150.153:2181,10.63.150.151:2181" services.coordinator.master.embedded-zookeeper.enabled: false -
Richten Sie den Dremio-Überlaufspeicherort auf den NetApp NFS-Speicher aus
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /opt/dremio/dremiocache/ total 8.0K drwxr-xr-x 3 dremio dremio 4.0K Aug 22 18:19 spill_old drwxr-xr-x 4 dremio dremio 4.0K Aug 22 18:19 cm lrwxrwxrwx 1 root root 12 Aug 22 19:03 spill -> /dremiocache root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# df -h /dremiocache Filesystem Size Used Avail Use% Mounted on 10.63.150.159:/dremiocache_hadoopnode1 2.1T 209M 2.0T 1% /dremiocache root@hadoopnode1:~#
-
Wählen Sie den Kontext aus. In unserem Test haben wir den Test mit von TPCDS generierten Parquet-Dateien ausgeführt, die sich in ONTAP S3 befinden. Dremio Dashboard → SQL-Runner → Kontext → NetAppONTAPS3→Parquet1TB
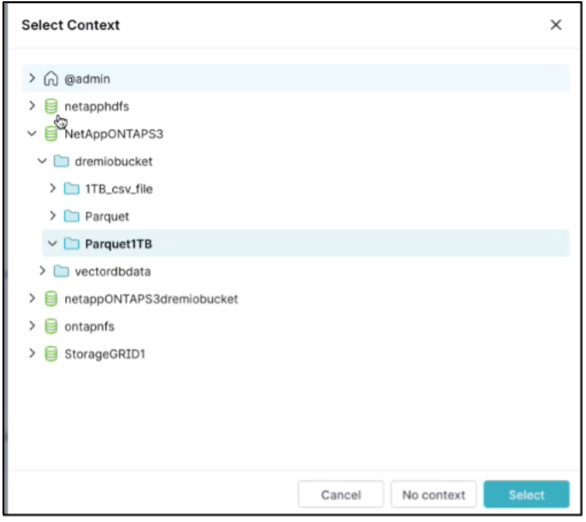
-
Führen Sie die TPC-DS-Abfrage67 vom Dremio-Dashboard aus

-
Überprüfen Sie, ob der Job auf allen Executoren ausgeführt wird. Dremio-Dashboard → Jobs → <Job-ID> → Rohprofil → EXTERNAL_SORT auswählen → Hostname
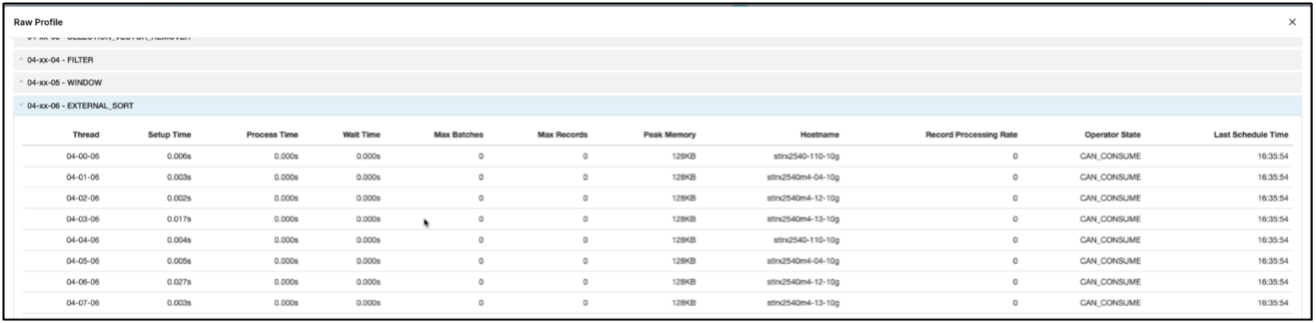
-
Wenn die SQL-Abfrage ausgeführt wird, können Sie den geteilten Ordner auf Daten-Caching im NetApp -Speichercontroller überprüfen.
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /dremiocache/spilling_stlrx2540m4-12-10g_45678/ total 4.0K drwxr-xr-x 2 root daemon 4.0K Sep 13 16:23 1726243167416
-
Die SQL-Abfrage wurde mit Überlauf abgeschlossen

-
Zusammenfassung der Auftragserledigung.
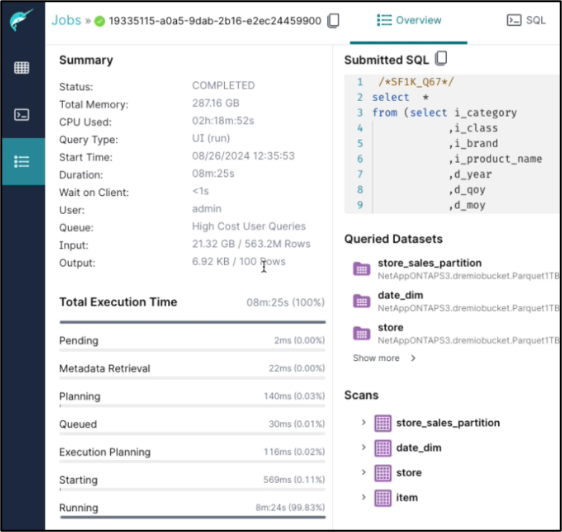
-
Überprüfen Sie die Größe der verschütteten Daten
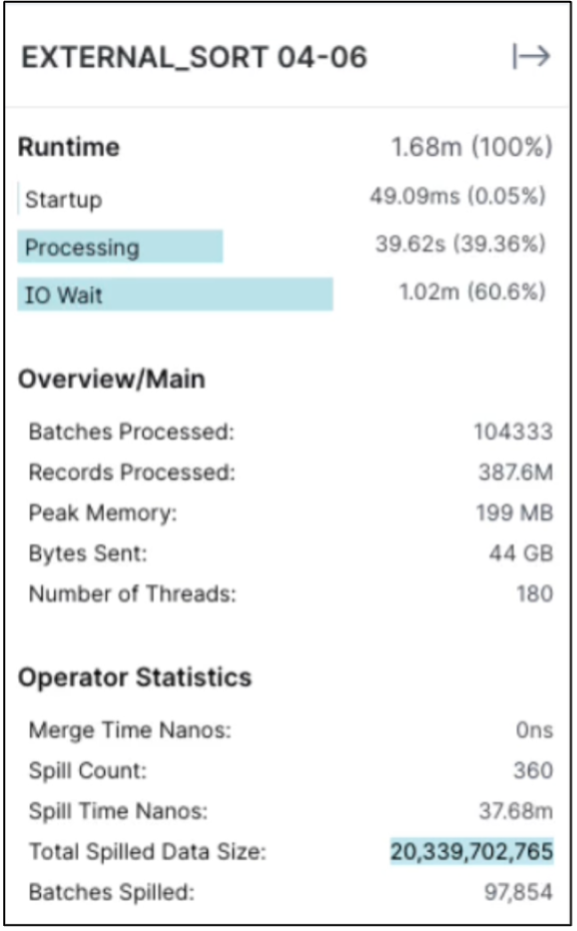
Das gleiche Verfahren gilt für NAS- und StorageGRID -Objektspeicher.