
Intelligentes Tiering und Kosteneinsparungen
 Änderungen vorschlagen
Änderungen vorschlagen
Da Kunden Splunk Data Analytics sehr einfach und leistungsfreundlich nutzen können, möchten sie natürlich eine stetig wachsende Datenmenge indizieren. Mit zunehmender Datenmenge wächst auch die für den Service erforderliche Computing- und Storage-Infrastruktur. Da auf ältere Daten weniger häufig referenziert wird, wird das Bestellen derselben Menge an Computing-Ressourcen und der Verbrauch kostspieliger Primärspeicher immer ineffizienter. Zur Skalierung profitieren Kunden davon, dass „warme“ Daten auf eine kostengünstigere Tier verschoben werden und so Datenverarbeitungs- und Primärspeicher für heiße Daten freigegeben werden.
Splunk SmartStore mit StorageGRID bietet Unternehmen eine skalierbare, performante und kostengünstige Lösung. Da SmartStore datenorientiert ist, werden Datenzugriffsmuster automatisch ausgewertet, um zu ermitteln, welche Daten für Echtzeitanalysen (wichtige Daten) genutzt werden müssen und welche Daten im kostengünstigeren Langzeitspeicher (warme Daten) gespeichert werden sollten. SmartStore nutzt die branchenübliche AWS S3 API dynamisch und intelligent und platziert Daten in den von StorageGRID bereitgestellten S3 Storage. Dank der flexiblen Scale-out-Architektur von StorageGRID kann die Tier mit „heißen“ Daten kosteneffizient je nach Bedarf wachsen. Die Node-basierte Architektur von StorageGRID sorgt dafür, dass die Performance- und Kostenanforderungen optimal erfüllt werden.
Folgende Abbildung zeigt Splunk und StorageGRID Tiering.
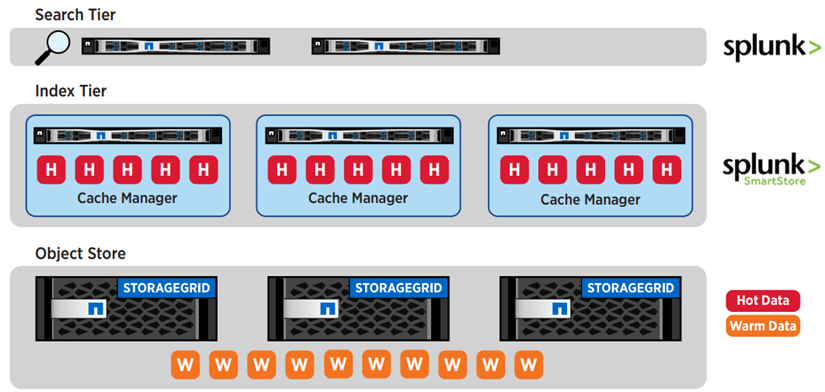
Die branchenführende Kombination aus Splunk SmartStore und NetApp StorageGRID bietet die Vorteile einer entkoppelten Architektur in einer Full-Stack-Lösung.