

VMware vSphere Lösungsübersicht
 Änderungen vorschlagen
Änderungen vorschlagen
Die vCenter Server Appliance (VCSA) ist ein leistungsstarkes, zentralisiertes Managementsystem und eine zentrale Benutzeroberfläche für vSphere, die es Administratoren ermöglicht, ESXi-Cluster effektiv zu betreiben. Es ermöglicht wichtige Funktionen wie die Bereitstellung virtueller Maschinen, vMotion-Operationen, Hochverfügbarkeit (HA), Distributed Resource Scheduler (DRS), VMware vSphere Kubernetes Service (VKS) und mehr. Es handelt sich um eine wesentliche Komponente in VMware-Cloud-Umgebungen, bei deren Entwicklung die Verfügbarkeit der Dienste im Vordergrund stand.
VSphere High Availability
Die Cluster-Technologie von VMware gruppiert ESXi Server zu Pools gemeinsam genutzter Ressourcen für virtuelle Maschinen und bietet vSphere High Availability (HA). VSphere HA bietet benutzerfreundliche Hochverfügbarkeit für Anwendungen, die in virtuellen Maschinen ausgeführt werden. Wenn die HA-Funktion auf dem Cluster aktiviert ist, hält jeder ESXi-Server die Kommunikation mit anderen Hosts aufrecht, sodass ein ESXi-Host nicht mehr reagiert oder isoliert wird. der HA-Cluster kann die Wiederherstellung der Virtual Machines, die auf diesem ESXi-Host ausgeführt wurden, zwischen den noch intakten Hosts im Cluster aushandeln. Im Falle eines Ausfalls eines Gastbetriebssystems kann vSphere HA die betroffene Virtual Machine auf demselben physischen Server neu starten. VSphere HA ermöglicht es, geplante Ausfallzeiten zu reduzieren, ungeplante Ausfallzeiten zu vermeiden und ein schnelles Recovery nach Ausfällen zu ermöglichen.
vSphere HA-Cluster stellt VMs von einem ausgefallenen Server wieder her.
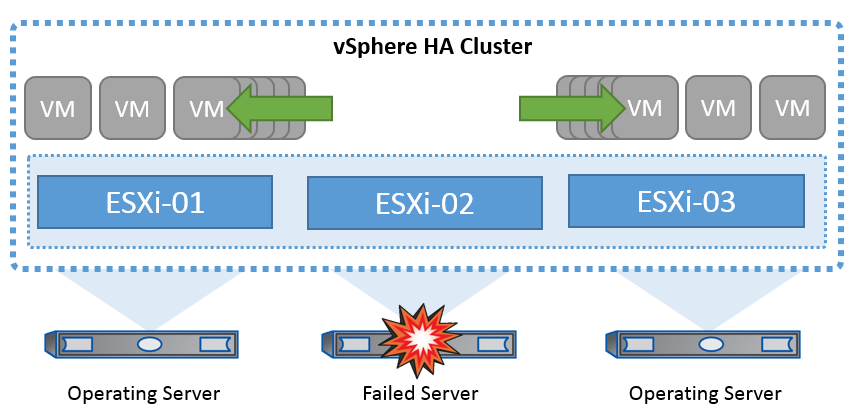
Es ist wichtig zu wissen, dass VMware vSphere weder über NetApp MetroCluster noch über SnapMirror Active Sync verfügt und alle ESXi Hosts im vSphere Cluster als berechtigte Hosts für HA-Clustervorgänge erkennt, je nach Host- und VM-Gruppenaffinitätskonfigurationen.
Erkennung Von Host-Ausfällen
Sobald der HA-Cluster erstellt ist, nehmen alle Hosts im Cluster an der Wahl teil, und einer der Hosts wird zum Master. Jeder Slave sendet einen Netzwerk-Heartbeat an den Master, und der Master sendet seinerseits einen Netzwerk-Heartbeat an alle Slave-Hosts. Der Master-Host eines vSphere HA-Clusters ist für die Erkennung des Ausfalls von Slave-Hosts zuständig.
Je nach Art des erkannten Fehlers müssen die auf den Hosts ausgeführten virtuellen Maschinen möglicherweise ein Failover durchführen.
In einem vSphere HA-Cluster werden drei Arten von Host-Ausfällen erkannt:
-
Fehler: Ein Host funktioniert nicht mehr.
-
Isolierung: Ein Host wird zu einem isolierten Netzwerk.
-
Partition: Ein Host verliert die Netzwerkverbindung mit dem Master-Host.
Der Master-Host überwacht die Slave-Hosts im Cluster. Diese Kommunikation erfolgt durch den Austausch von Netzwerk-Heartbeats jede Sekunde. Wenn der Master-Host diese Heartbeats nicht mehr von einem Slave-Host empfängt, prüft er die Host-Lebendigkeit, bevor er den Host für fehlgeschlagen erklärt. Die Liveness-Prüfung, die der Master-Host durchführt, besteht darin festzustellen, ob der Slave-Host Heartbeats mit einem der Datastores austauscht. Außerdem prüft der Master-Host, ob der Host auf ICMP-Pings reagiert, die an seine Management-IP-Adressen gesendet werden, um festzustellen, ob er lediglich von seinem Master-Knoten isoliert oder vollständig vom Netzwerk isoliert ist. Dies erfolgt durch Ping an das Standard-Gateway. Eine oder mehrere Isolationsadressen können manuell angegeben werden, um die Zuverlässigkeit der Isolationsvalidierung zu erhöhen.

|
NetApp empfiehlt, mindestens zwei zusätzliche Isolationsadressen anzugeben, und jede dieser Adressen sollte standortlokal sein. Dies erhöht die Zuverlässigkeit der Isolationsvalidierung. |
Antwort Der Hostisolation
Die Isolationsreaktion ist eine Einstellung in vSphere HA, die festlegt, welche Aktion auf virtuellen Maschinen ausgelöst wird, wenn ein Host in einem vSphere HA-Cluster seine Management-Netzwerkverbindungen verliert, aber weiterhin ausgeführt wird. Für diese Einstellung gibt es drei Optionen: „Deaktiviert“, „VMs herunterfahren und neu starten“ und „VMs ausschalten und neu starten“.
„Herunterfahren“ ist besser als „Ausschalten“, da bei letzterem die zuletzt vorgenommenen Änderungen nicht auf die Festplatte geschrieben und Transaktionen nicht gespeichert werden. Wenn virtuelle Maschinen nicht innerhalb von 300 Sekunden heruntergefahren werden, werden sie ausgeschaltet. Um die Wartezeit zu ändern, verwenden Sie die erweiterte Option das.isolationshutdowntimeout.
Bevor HA die Isolationsantwort initiiert, prüft es zunächst, ob der vSphere HA-Master-Agent den Datenspeicher besitzt, der die VM-Konfigurationsdateien enthält. Wenn dies nicht der Fall ist, löst der Host die Isolationsantwort nicht aus, da kein Master zum Neustart der VMs vorhanden ist. Der Host überprüft regelmäßig den Datastore-Status, um festzustellen, ob er von einem vSphere HA-Agent beansprucht wird, der die Master-Rolle besitzt.
|
|
NetApp empfiehlt, die „Host-Isolationsantwort“ auf deaktiviert zu setzen. |
Ein Split-Brain-Zustand kann auftreten, wenn ein Host vom vSphere HA-Master-Host isoliert oder partitioniert wird und der Master nicht über Heartbeat Datastores oder Ping kommunizieren kann. Der Master erklärt den isolierten Host für tot und startet die VMs auf anderen Hosts im Cluster neu. Eine Split-Brain-Bedingung besteht jetzt, weil zwei Instanzen der virtuellen Maschine ausgeführt werden, von denen nur eine die virtuellen Laufwerke lesen oder schreiben kann. Split-Brain-Bedingungen können jetzt durch die Konfiguration von VM Component Protection (VMCP) vermieden werden.
Schutz von VM-Komponenten (VMCP)
Eine der Funktionsverbesserungen bei vSphere 6, relevant für HA, ist VMCP. VMCP bietet erweiterten Schutz vor All Paths Down (APD) und Permanent Device Loss (PDL) für Block (FC, iSCSI, FCoE) und File Storage (NFS).
Permanenter Geräteverlust (PDL)
PDL ist ein Zustand, der eintritt, wenn ein Speichermedium dauerhaft ausfällt oder administrativ entfernt wird und voraussichtlich nicht wiederhergestellt werden kann. Das NetApp -Speicherarray sendet einen SCSI-Sense-Code an ESXi, der signalisiert, dass das Gerät dauerhaft ausgefallen ist. Im Abschnitt „Fehlerbedingungen und VM-Reaktion“ von vSphere HA können Sie konfigurieren, wie die Reaktion nach dem Erkennen einer PDL-Bedingung aussehen soll.
|
|
NetApp empfiehlt, die "Reaktion für Datenspeicher mit PDL" auf "VMs ausschalten und neu starten" einzustellen. Wird dieser Zustand erkannt, wird eine VM sofort auf einem fehlerfreien Host innerhalb des vSphere HA-Clusters neu gestartet. |
Alle Pfade nach unten (APD)
APD ist ein Zustand, der auftritt, wenn ein Speichermedium für den Host nicht mehr zugänglich ist und keine Pfade zum Array mehr verfügbar sind. ESXi betrachtet dies als ein vorübergehendes Problem mit dem Gerät und geht davon aus, dass es bald wieder verfügbar sein wird.
Wenn eine APD-Bedingung erkannt wird, wird ein Timer gestartet. Nach 140 Sekunden wird der APD-Zustand offiziell deklariert und das Gerät als APD-Zeitabmeldung markiert. Nach Ablauf der 140 Sekunden zählt HA die Anzahl der Minuten, die in der Verzögerung für VM-Failover-APD angegeben sind. Wenn die angegebene Zeit verstrichen ist, startet HA die betroffenen virtuellen Maschinen neu. Sie können VMCP so konfigurieren, dass es bei Bedarf anders reagiert (deaktiviert, Ereignisse ausstellen oder VMs aus- und neu starten).
|
|
|
VMware DRS Implementierung für NetApp SnapMirror Active Sync
VMware DRS ist eine Funktion, die die Host-Ressourcen in einem Cluster aggregiert und hauptsächlich zum Lastausgleich innerhalb eines Clusters in einer virtuellen Infrastruktur verwendet wird. VMware DRS berechnet in erster Linie die CPU- und Arbeitsspeicherressourcen für den Lastausgleich in einem Cluster. Da vSphere das erweiterte Clustering nicht kennt, werden beim Lastausgleich alle Hosts an beiden Standorten berücksichtigt.
VMware DRS Implementierung für NetApp MetroCluster
To avoid cross-site traffic, NetApp recommends configuring DRS affinity rules to manage a logical separation of VMs. This will ensure that, unless there is a complete site failure, HA and DRS will only use local hosts. Wenn Sie eine DRS-Affinitätsregel für Ihr Cluster erstellen, können Sie festlegen, wie vSphere diese Regel während eines Failover einer virtuellen Maschine anwendet.
Es gibt zwei Arten von Regeln, die Sie für das Failover-Verhalten von vSphere HA festlegen können:
-
VM-Anti-Affinitätsregeln zwingen bestimmte Virtual Machines dazu, bei Failover-Aktionen getrennt zu bleiben.
-
VM-Host-Affinitätsregeln platzieren angegebene Virtual Machines während Failover-Aktionen auf einem bestimmten Host oder einem Mitglied einer definierten Gruppe von Hosts.
Mithilfe der VM Host-Affinitätsregeln in VMware DRS lässt sich eine logische Trennung zwischen Standort A und Standort B erreichen, sodass die VM auf dem Host am selben Standort ausgeführt wird wie das Array, das als primärer Lese-/Schreib-Controller für einen bestimmten Datenspeicher konfiguriert ist. Zudem bleiben Virtual Machines gemäß den Regeln zur VM Host-Affinität lokal im Storage, wodurch wiederum die Virtual Machine-Verbindung im Falle von Netzwerkausfällen zwischen den Standorten hergestellt wird.
Nachfolgend finden Sie ein Beispiel für VM-Hostgruppen und Affinitätsregeln.
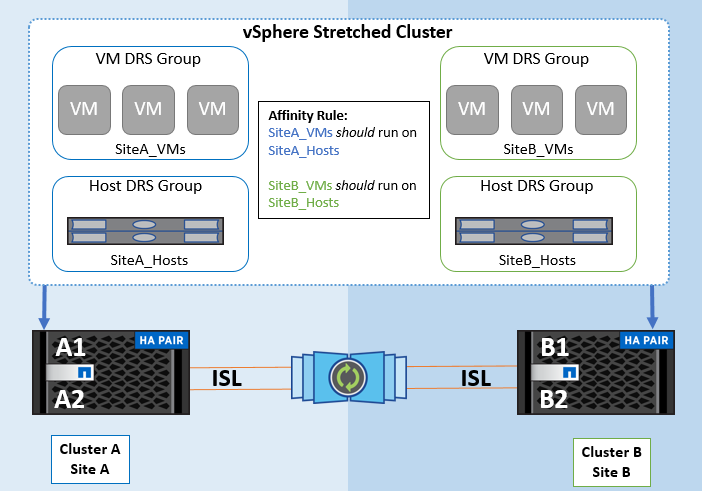
Best Practice
NetApp empfiehlt die Implementierung der „sollte“-Regeln statt der „müssen“-Regeln, da im Falle eines Ausfalls von vSphere HA gegen diese verstoßen wird. Die Verwendung von „Must“-Regeln kann zu Serviceausfällen führen.
Die Verfügbarkeit von Dienstleistungen sollte stets Vorrang vor der Leistung haben. Im Falle eines vollständigen Ausfalls des Rechenzentrums müssen die "Muss"-Regeln Hosts aus der VM-Hostaffinitätsgruppe auswählen, und wenn das Rechenzentrum nicht verfügbar ist, werden die virtuellen Maschinen nicht neu gestartet.
VMware Storage DRS Implementierung mit NetApp MetroCluster
Die VMware Storage DRS-Funktion ermöglicht die Aggregation von Datastores in eine einzige Einheit und gleicht Festplatten der virtuellen Maschine aus, wenn die SIOC-Schwellenwerte (Storage I/O Control) überschritten werden.
Die Storage-I/O-Steuerung ist bei DRS-Clustern mit Storage DRS standardmäßig aktiviert. Mit der Storage-I/O-Kontrolle kann ein Administrator die Menge an Storage-I/O steuern, die Virtual Machines bei I/O-Engpässen zugewiesen wird. Dadurch können wichtigeren Virtual Machines bei der I/O-Ressourcenzuweisung Vorrang vor weniger wichtigen Virtual Machines geben.
Storage DRS verwendet Storage vMotion, um die virtuellen Maschinen auf verschiedene Datastores innerhalb eines Datastore-Clusters zu migrieren. In einer NetApp MetroCluster Umgebung muss eine Migration von Virtual Machines innerhalb der Datenspeicher dieses Standorts gesteuert werden. Eine Virtual Machine A, die auf einem Host an Standort A ausgeführt wird, sollte idealerweise innerhalb der Datenspeicher der SVM an Standort A migriert werden Wenn dies nicht der Fall ist, wird die virtuelle Maschine weiterhin betrieben, jedoch mit verminderter Leistung, da das Lesen/Schreiben der virtuellen Festplatte von Standort B über standortübergreifende Links erfolgt.
|
|
*Bei Verwendung von ONTAP-Speicher wird empfohlen, Storage DRS zu deaktivieren.
|