

ONTAP Select HA verbessert den Datenschutz
 Änderungen vorschlagen
Änderungen vorschlagen
High-Availability (HA) Festplatten-Heartbeating, HA-Mailbox, HA-Heartbeating, HA-Failover und Giveback arbeiten zusammen, um den Datenschutz zu verbessern.
Festplatten-Heartbeating
Obwohl die ONTAP Select HA-Architektur viele der von herkömmlichen FAS Arrays verwendeten Codepfade nutzt, gibt es einige Ausnahmen. Eine dieser Ausnahmen betrifft die Implementierung des festplattenbasierten Heartbeatings, einer nicht netzwerkbasierten Kommunikationsmethode, die von Clusterknoten verwendet wird, um zu verhindern, dass Netzwerkisolation zu einem Split-Brain-Verhalten führt. Ein Split-Brain-Szenario entsteht durch Clusterpartitionierung, typischerweise verursacht durch Netzwerkausfälle, wobei jede Seite annimmt, die andere sei ausgefallen, und versucht, Clusterressourcen zu übernehmen.
HA-Implementierungen der Enterprise-Klasse müssen solche Szenarien problemlos bewältigen. ONTAP nutzt hierfür ein angepasstes, festplattenbasiertes Heartbeat-Verfahren. Die Aufgabe übernimmt die HA-Mailbox, ein Speicherort auf dem physischen Speicher, der von den Clusterknoten zum Austausch von Heartbeat-Nachrichten verwendet wird. Dies hilft dem Cluster, die Konnektivität zu ermitteln und somit im Falle eines Failovers das Quorum zu bestimmen.
Bei FAS Arrays, die eine gemeinsam genutzte Speicher-HA-Architektur verwenden, löst ONTAP Split-Brain-Probleme auf folgende Weise:
-
SCSI persistente Reservierungen
-
Persistente HA-Metadaten
-
HA-Status wird über HA-Verbindung gesendet
In der Shared-Nothing-Architektur eines ONTAP Select Clusters kann ein Knoten jedoch nur auf seinen eigenen lokalen Speicher zugreifen und nicht auf den des HA-Partners. Daher sind die zuvor beschriebenen Methoden zur Bestimmung des Cluster-Quorums und des Failover-Verhaltens nicht verfügbar, wenn die Netzwerkpartitionierung die beiden Seiten eines HA-Paares isoliert.
Obwohl die bisherige Methode zur Erkennung und Vermeidung von Split-Brain-Situationen nicht anwendbar ist, wird weiterhin ein Mediationsverfahren benötigt, das sich in einer Shared-Nothing-Umgebung bewährt. ONTAP Select erweitert die bestehende Mailbox-Infrastruktur und ermöglicht so die Mediation bei Netzwerkpartitionierung. Da kein gemeinsamer Speicher verfügbar ist, erfolgt die Mediation über den Zugriff auf die Mailbox-Festplatten via NAS. Diese Festplatten sind über den gesamten Cluster verteilt, einschließlich des Mediators in einem Zwei-Node-Cluster, und nutzen das iSCSI-Protokoll. Dadurch kann ein Clusterknoten auf Basis des Zugriffs auf diese Festplatten intelligente Failover-Entscheidungen treffen. Kann ein Knoten auf die Mailbox-Festplatten anderer Knoten außerhalb seines HA-Partners zugreifen, ist er wahrscheinlich betriebsbereit.

|
Die Mailbox-Architektur und die auf Festplatten basierende Heartbeat-Methode zur Behebung von Cluster-Quorum- und Split-Brain-Problemen sind die Gründe, warum die Multi-Node-Variante von ONTAP Select entweder vier separate Knoten oder einen Mediator für ein Zwei-Node-Cluster erfordert. |
HA-Mailbox-Posting
Die HA-Mailbox-Architektur verwendet ein Message-Post-Modell. In regelmäßigen Abständen senden Clusterknoten Nachrichten an alle anderen Mailbox-Festplatten im Cluster, einschließlich des Mediators, und geben an, dass der Knoten betriebsbereit ist. In einem fehlerfreien Cluster befinden sich zu jedem Zeitpunkt auf der Mailbox-Festplatte eines Clusterknotens Nachrichten von allen anderen Clusterknoten.
Jedem Select-Clusterknoten ist eine virtuelle Festplatte zugeordnet, die speziell für den gemeinsamen Postfachzugriff verwendet wird. Diese Festplatte wird als Mediator-Postfachfestplatte bezeichnet, da ihre Hauptfunktion darin besteht, als Methode zur Cluster-Vermittlung im Falle von Knotenausfällen oder Netzwerkpartitionierung zu dienen. Diese Postfachfestplatte enthält Partitionen für jeden Clusterknoten und wird von anderen Select-Clusterknoten über ein iSCSI-Netzwerk eingebunden. Diese Knoten senden regelmäßig Statusmeldungen an die entsprechende Partition der Postfachfestplatte. Durch die Verwendung von netzwerkzugänglichen Postfachfestplatten im gesamten Cluster lässt sich der Knotenstatus mithilfe einer Erreichbarkeitsmatrix ableiten. Beispielsweise können die Clusterknoten A und B an das Postfach von Clusterknoten D schreiben, jedoch nicht an das Postfach von Knoten C. Außerdem kann Clusterknoten D nicht an das Postfach von Knoten C schreiben, sodass es wahrscheinlich ist, dass Knoten C entweder ausgefallen oder vom Netzwerk isoliert ist und übernommen werden sollte.
HA Heartbeating
Wie bei NetApp FAS-Plattformen sendet ONTAP Select regelmäßig HA-Heartbeat-Nachrichten über die HA-Interconnect. Innerhalb des ONTAP Select Clusters erfolgt dies über eine TCP/IP-Netzwerkverbindung, die zwischen den HA-Partnern besteht. Zusätzlich werden festplattenbasierte Heartbeat-Nachrichten an alle HA-Mailbox-Disks, einschließlich der Mediator-Mailbox-Disks, übermittelt. Diese Nachrichten werden alle paar Sekunden übermittelt und regelmäßig zurückgelesen. Die Häufigkeit, mit der diese gesendet und empfangen werden, ermöglicht es dem ONTAP Select Cluster, HA-Ausfallereignisse innerhalb von etwa 15 Sekunden zu erkennen, was dem gleichen Zeitfenster wie bei FAS-Plattformen entspricht. Wenn Heartbeat-Nachrichten nicht mehr gelesen werden, wird ein Failover-Ereignis ausgelöst.
Die folgende Abbildung zeigt den Prozess des Sendens und Empfangens von Heartbeat-Nachrichten über die HA-Verbindung und die Mediator-Disks aus der Perspektive eines einzelnen ONTAP Select Cluster-Node, Node C.
|
|
Netzwerk-Heartbeats werden über die HA-Verbindung an den HA-Partner, Knoten D, gesendet, während Disk-Heartbeats Mailbox-Disks über alle Clusterknoten A, B, C und D hinweg verwenden. |
*HA-Herzschlag in einem Vier-Knoten-Cluster: stabiler Zustand*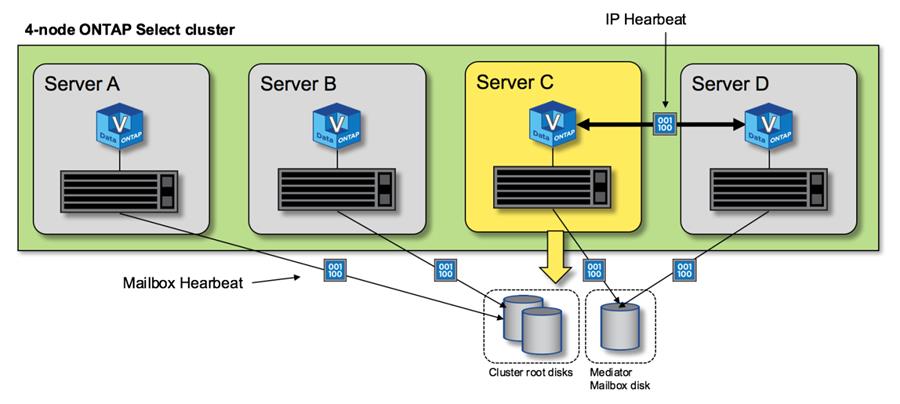
HA-Failover und Giveback
Während eines Failover-Vorgangs übernimmt der verbleibende Knoten die Datenbereitstellungsverantwortung für seinen Partnerknoten mithilfe der lokalen Kopie der Daten seines HA-Partners. Client-I/O kann ununterbrochen fortgesetzt werden, aber Änderungen an diesen Daten müssen repliziert werden, bevor die Rückgabe erfolgen kann. Beachten Sie, dass ONTAP Select eine erzwungene Rückgabe nicht unterstützt, da dies dazu führt, dass auf dem verbleibenden Knoten gespeicherte Änderungen verloren gehen.
Der Sync-Back-Vorgang wird automatisch ausgelöst, wenn der neu gestartete Node dem Cluster wieder beitritt. Die für den Sync-Back benötigte Zeit hängt von mehreren Faktoren ab. Zu diesen Faktoren gehören die Anzahl der zu replizierenden Änderungen, die Netzwerklatenz zwischen den Nodes und die Geschwindigkeit der Festplattensubsysteme auf jedem Node. Es ist möglich, dass die für den Sync-Back benötigte Zeit das automatische Giveback-Fenster von 10 Minuten überschreitet. In diesem Fall ist nach dem Sync-Back ein manueller Giveback erforderlich. Der Fortschritt des Sync-Backs kann mit dem folgenden Befehl überwacht werden:
storage aggregate status -r -aggregate <aggregate name>