

Ersetzen Sie ein I/O-Modul – AFF A700 und FAS9000
 Änderungen vorschlagen
Änderungen vorschlagen
Um ein E/A-Modul zu ersetzen, müssen Sie eine bestimmte Sequenz von Aufgaben ausführen.
-
Sie können dieses Verfahren bei allen Versionen von ONTAP verwenden, die von Ihrem System unterstützt werden
-
Alle anderen Komponenten des Systems müssen ordnungsgemäß funktionieren. Falls nicht, müssen Sie sich an den technischen Support wenden.
Schritt 1: Schalten Sie den beeinträchtigten Regler aus
Sie können den beeinträchtigten Controller je nach Hardwarekonfiguration des Speichersystems mithilfe verschiedener Verfahren herunterfahren oder übernehmen.
Übernehmen Sie den fehlerhaften Controller und stoppen Sie ihn, damit der intakte Controller weiterhin Daten aus dem Speicher des fehlerhaften Controllers bereitstellt. Dazu unterdrücken Sie die automatische Fallerstellung in AutoSupport, deaktivieren die automatische Rückgabe und bringen den fehlerhaften Controller zur LOADER-Eingabeaufforderung. Die LOADER-Eingabeaufforderung ist der sichere, angehaltene Zustand, aus dem Sie die FRU ersetzen können.
-
Wenn Sie über ein SAN-System verfügen, müssen Sie Event-Meldungen ) für den beeinträchtigten Controller SCSI Blade überprüft haben
cluster kernel-service show. Mit demcluster kernel-service showBefehl (im erweiterten Modus von priv) werden der Knotenname, der Node, der Verfügbarkeitsstatus dieses Node und der Betriebsstatus dieses Node angezeigt"Quorum-Status".Jeder Prozess des SCSI-Blades sollte sich im Quorum mit den anderen Nodes im Cluster befinden. Probleme müssen behoben werden, bevor Sie mit dem Austausch fortfahren.
-
Wenn Sie über ein Cluster mit mehr als zwei Nodes verfügen, muss es sich im Quorum befinden. Wenn sich das Cluster nicht im Quorum befindet oder ein gesunder Controller FALSE anzeigt, um die Berechtigung und den Zustand zu erhalten, müssen Sie das Problem korrigieren, bevor Sie den beeinträchtigten Controller herunterfahren; siehe "Synchronisieren eines Node mit dem Cluster".
-
Wenn AutoSupport aktiviert ist, unterdrücken Sie die automatische Erstellung eines Cases durch Aufrufen einer AutoSupport Meldung:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hDies verhindert, dass während Ihres geplanten Wartungsfensters automatisch Supportfälle eröffnet werden. Die maximale Unterdrückungsdauer beträgt 72 Stunden. Falls Ihre Wartung vorzeitig abgeschlossen ist, können Sie die Fallerstellung wieder aktivieren, indem Sie eine AutoSupport-Nachricht mit
MAINT=ENDauslösen. Weitere Informationen finden Sie unter "Wie man die automatische Fallerstellung während geplanter Wartungsfenster unterdrückt".Die folgende AutoSupport Meldung unterdrückt die automatische Erstellung von Cases für zwei Stunden:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Automatische Rückgabe deaktivieren:
-
Geben Sie den folgenden Befehl von der Konsole des fehlerfreien Controllers ein:
storage failover modify -node impaired_node_name -auto-giveback false -
Eingeben
ywenn die Eingabeaufforderung Möchten Sie die automatische Rückgabe deaktivieren? angezeigt wird
-
-
Nehmen Sie den beeinträchtigten Controller zur LOADER-Eingabeaufforderung:
Wenn der eingeschränkte Controller angezeigt wird… Dann… Die LOADER-Eingabeaufforderung
Fahren Sie mit dem nächsten Schritt fort.
Warten auf Giveback…
Drücken Sie Strg-C, und antworten Sie dann
yWenn Sie dazu aufgefordert werden.Eingabeaufforderung für das System oder Passwort
Übernehmen oder stoppen Sie den beeinträchtigten Regler von der gesunden Steuerung:
storage failover takeover -ofnode impaired_node_name -halt trueDer Parameter -stop true führt Sie zur Loader-Eingabeaufforderung.
Um den beeinträchtigten Controller herunterzufahren, müssen Sie den Status des Controllers bestimmen und gegebenenfalls den Controller umschalten, damit der gesunde Controller weiterhin Daten aus dem beeinträchtigten Reglerspeicher bereitstellen kann.
-
Sie müssen die Netzteile am Ende dieses Verfahrens einschalten, um den gesunden Controller mit Strom zu versorgen.
-
Überprüfen Sie den MetroCluster-Status, um festzustellen, ob der beeinträchtigte Controller automatisch auf den gesunden Controller umgeschaltet wurde:
metrocluster show -
Je nachdem, ob eine automatische Umschaltung stattgefunden hat, fahren Sie mit der folgenden Tabelle fort:
Wenn die eingeschränkte Steuerung… Dann… Ist automatisch umgeschaltet
Fahren Sie mit dem nächsten Schritt fort.
Nicht automatisch umgeschaltet
Einen geplanten Umschaltvorgang vom gesunden Controller durchführen:
metrocluster switchoverHat nicht automatisch umgeschaltet, haben Sie versucht, mit dem zu wechseln
metrocluster switchoverBefehl und Switchover wurde vetoedÜberprüfen Sie die Veto-Meldungen, und beheben Sie das Problem, wenn möglich, und versuchen Sie es erneut. Wenn das Problem nicht behoben werden kann, wenden Sie sich an den technischen Support.
-
Synchronisieren Sie die Datenaggregate neu, indem Sie das ausführen
metrocluster heal -phase aggregatesBefehl aus dem verbleibenden Cluster.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Wenn die Heilung ein Vetorecht ist, haben Sie die Möglichkeit, das zurückzugeben
metrocluster healBefehl mit dem-override-vetoesParameter. Wenn Sie diesen optionalen Parameter verwenden, überschreibt das System alle weichen Vetos, die die Heilung verhindern. -
Überprüfen Sie, ob der Vorgang mit dem befehl „MetroCluster Operation show“ abgeschlossen wurde.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Überprüfen Sie den Status der Aggregate mit
storage aggregate showBefehl.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Heilen Sie die Root-Aggregate mit dem
metrocluster heal -phase root-aggregatesBefehl.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Wenn die Heilung ein Vetorecht ist, haben Sie die Möglichkeit, das zurückzugeben
metrocluster healBefehl mit dem Parameter -override-vetoes. Wenn Sie diesen optionalen Parameter verwenden, überschreibt das System alle weichen Vetos, die die Heilung verhindern. -
Stellen Sie sicher, dass der Heilungsvorgang abgeschlossen ist, indem Sie den verwenden
metrocluster operation showBefehl auf dem Ziel-Cluster:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
Trennen Sie am Controller-Modul mit eingeschränkter Betriebsstörung die Netzteile.
Schritt 2: E/A-Module ersetzen
Um ein E/A-Modul zu ersetzen, suchen Sie es im Gehäuse und befolgen Sie die spezifischen Schritte.
-
Wenn Sie nicht bereits geerdet sind, sollten Sie sich richtig Erden.
-
Trennen Sie alle Kabel, die mit dem Ziel-E/A-Modul verbunden sind.
Achten Sie darauf, dass Sie die Kabel so kennzeichnen, dass Sie wissen, woher sie stammen.
-
Entfernen Sie das Ziel-I/O-Modul aus dem Gehäuse:
-
Drücken Sie die Taste mit der Nummerierung und dem Buchstaben.
Die Nockentaste bewegt sich vom Gehäuse weg.
-
Drehen Sie die Nockenverriegelung nach unten, bis sie sich in horizontaler Position befindet.
Das I/O-Modul wird aus dem Gehäuse entfernt und bewegt sich ca. 1/2 Zoll aus dem I/O-Steckplatz.
-
Entfernen Sie das E/A-Modul aus dem Gehäuse, indem Sie an den Zuglaschen an den Seiten der Modulfläche ziehen.
Stellen Sie sicher, dass Sie den Steckplatz verfolgen, in dem sich das I/O-Modul befand.
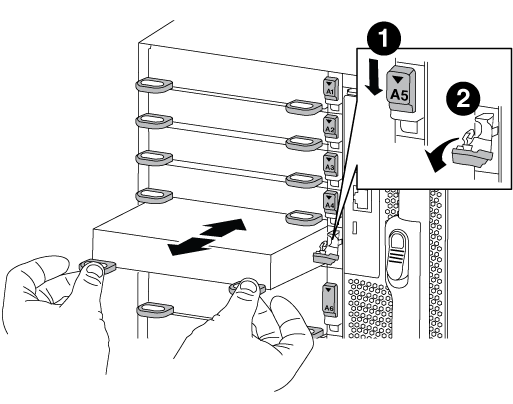

Gerettete und nummerierte E/A-Nockenverriegelung

E/A-Nockenverriegelung vollständig entriegelt
-
-
Legen Sie das E/A-Modul beiseite.
-
Setzen Sie das Ersatz-E/A-Modul in das Gehäuse ein, indem Sie das E/A-Modul vorsichtig in den Steckplatz schieben, bis die vorletzte und nummerierte E/A-Nockenverriegelung mit dem E/A-Nockenstift in Kontakt kommt und dann die E/A-Nockenverriegelung ganz nach oben drücken, um das Modul zu sichern.
-
E/A-Modul nach Bedarf wieder aufführen.
Schritt 3: Starten Sie den Controller nach dem Austausch des E/A-Moduls neu
Nachdem Sie ein I/O-Modul ersetzt haben, müssen Sie das Controller-Modul neu starten.

|
Wenn das neue I/O-Modul nicht das gleiche Modell wie das ausgefallene Modul ist, müssen Sie zuerst den BMC neu booten. |
-
Starten Sie den BMC neu, wenn das Ersatzmodul nicht dasselbe Modell wie das alte Modul ist:
-
Ändern Sie von der LOADER-Eingabeaufforderung in den erweiterten Berechtigungsebene:
priv set advanced -
Starten Sie den BMC neu:
sp reboot
-
-
Booten Sie an der LOADER-Eingabeaufforderung den Node neu:
bye
Dadurch werden die PCIe-Karten und andere Komponenten neu initialisiert und der Node wird neu gebootet. -
Wenn Ihr System 10-GbE-Cluster Interconnect- und Datenverbindungen auf 40-GbE-NICs oder integrierten Ports konfiguriert ist, konvertieren Sie diese Ports mithilfe der in 10-GbE-Verbindungen
nicadmin convertBefehl im Wartungsmodus.
Achten Sie darauf, den Wartungsmodus nach Abschluss der Konvertierung zu beenden. -
Zurückkehren des Node in den normalen Betrieb:
storage failover giveback -ofnode impaired_node_name -
Wenn die automatische Rückübertragung deaktiviert wurde, aktivieren Sie sie erneut:
storage failover modify -node local -auto-giveback true
Wenn sich Ihr System in einer MetroCluster Konfiguration mit zwei Nodes befindet, müssen Sie die Aggregate wie im nächsten Schritt beschrieben wiederherstellen.
Schritt 4: Aggregate in einer MetroCluster Konfiguration mit zwei Nodes zurückwechseln
Dieser Task gilt nur für MetroCluster-Konfigurationen mit zwei Nodes.
-
Vergewissern Sie sich, dass sich alle Nodes im befinden
enabledBundesland:metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Überprüfen Sie, ob die Neusynchronisierung auf allen SVMs abgeschlossen ist:
metrocluster vserver show -
Überprüfen Sie, ob die automatischen LIF-Migrationen durch die heilenden Vorgänge erfolgreich abgeschlossen wurden:
metrocluster check lif show -
Führen Sie den Wechsel zurück mit dem aus
metrocluster switchbackBefehl von einem beliebigen Node im verbleibenden Cluster -
Stellen Sie sicher, dass der Umkehrvorgang abgeschlossen ist:
metrocluster showDer Vorgang zum zurückwechseln wird weiterhin ausgeführt, wenn sich ein Cluster im befindet
waiting-for-switchbackBundesland:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
Der Vorgang zum zurückwechseln ist abgeschlossen, wenn sich die Cluster im befinden
normalBundesland:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Wenn ein Wechsel eine lange Zeit in Anspruch nimmt, können Sie den Status der in-progress-Basispläne über die überprüfen
metrocluster config-replication resync-status showBefehl. -
Wiederherstellung beliebiger SnapMirror oder SnapVault Konfigurationen
Schritt 5: Senden Sie das fehlgeschlagene Teil an NetApp zurück
Senden Sie das fehlerhafte Teil wie in den dem Kit beiliegenden RMA-Anweisungen beschrieben an NetApp zurück. "Rückgabe und Austausch von Teilen"Weitere Informationen finden Sie auf der Seite.