

Hochverfügbarkeitspaare
 Änderungen vorschlagen
Änderungen vorschlagen
Cluster-Nodes werden für Fehlertoleranz und unterbrechungsfreien Betrieb in High-Availability-(HA-)Paaren konfiguriert. Wenn ein Node ausfällt oder Sie einen Node zur routinemäßigen Wartung herunterfahren müssen, kann sein Partner dessen Storage _übernehmen und weiterhin Daten daraus liefern. Der Partner_gibt Back_ Storage zurück, wenn der Node wieder in den Online-Modus versetzt wird.
HA-Paare bestehen immer aus ähnlichen Controller-Modellen. Die Controller befinden sich normalerweise im selben Chassis mit redundanten Netzteilen.
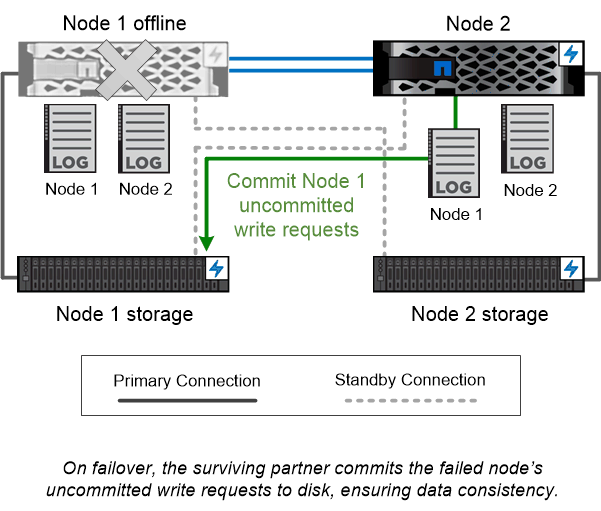
Bei den HA-Paaren handelt es sich um fehlertolerante Knoten, die auf unterschiedliche Weise miteinander kommunizieren können, sodass jeder Knoten kontinuierlich prüfen kann, ob sein Partner funktioniert, und Protokolldaten für den nichtflüchtigen Speicher des anderen spiegeln kann. Wenn eine Schreibanforderung an einen Knoten gestellt wird, wird sie im NVRAM beider Knoten protokolliert, bevor eine Antwort an den Client oder Host zurückgesendet wird. Beim Failover schreibt der überlebende Partner die nicht festgeschriebenen Schreibanforderungen des ausgefallenen Knotens auf die Festplatte und stellt so die Datenkonsistenz sicher. Der überlebende Knoten protokolliert weiterhin die Schreibvorgänge in der NVRAM Partition, die zuvor als Spiegel des NVRAM des ausgefallenen Knotens fungierte.
Dank Verbindungen mit den Storage-Medien des anderen Controllers kann jeder Node im Falle eines Takeover auf den Storage des anderen Controllers zugreifen. Durch Failover-Mechanismen von Netzwerkpfaden wird sichergestellt, dass Clients und Hosts weiterhin mit dem verbleibenden Node kommunizieren.
Um die Verfügbarkeit zu gewährleisten, sollte die Performance-Kapazitätsauslastung auf beiden Nodes bei 50 % sichergestellt werden, um den zusätzlichen Workload im Failover-Fall zu unterstützen. Aus dem gleichen Grund möchten Sie möglicherweise nicht mehr als 50 % der maximalen Anzahl an virtuellen NAS-Netzwerkschnittstellen für einen Node konfigurieren.
Übernahme und Rückgabe in virtualisierten ONTAP-Implementierungen In virtualisierten „Shared-Nothing“ ONTAP Implementierungen wie ONTAP Select wird der Speicher nicht zwischen Knoten geteilt. Fällt ein Knoten aus, stellt sein Partner weiterhin Daten aus einer synchron gespiegelten Kopie der Knotendaten bereit. Er übernimmt nicht den Speicher des Knotens, sondern lediglich dessen Datenbereitstellungsfunktion. |