

Erfahren Sie mehr über Data Tiering mit Cloud Volumes ONTAP in AWS, Azure oder Google Cloud
 Änderungen vorschlagen
Änderungen vorschlagen
Reduzieren Sie Ihre Speicherkosten, indem Sie die automatische Einstufung inaktiver Daten in kostengünstigen Objektspeicher ermöglichen. Aktive Daten verbleiben auf Hochleistungs-SSDs oder -HDDs, während inaktive Daten auf kostengünstigen Objektspeicher ausgelagert werden. Dadurch können Sie Speicherplatz auf Ihrem primären Speicher zurückgewinnen und den sekundären Speicher verkleinern.
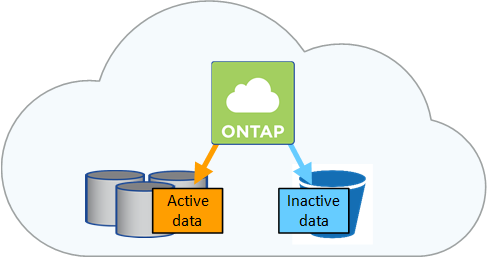
Die Datenschichtung wird durch die FabricPool -Technologie ermöglicht. Cloud Volumes ONTAP bietet Daten-Tiering für alle Cloud Volumes ONTAP Cluster ohne zusätzliche Lizenz. Wenn Sie die Datenschichtung aktivieren, fallen für die in den Objektspeicher verschobenen Daten Gebühren an. Einzelheiten zu den Kosten für die Objektspeicherung finden Sie in der Dokumentation Ihres Cloud-Anbieters.
Daten-Tiering in AWS
Wenn Sie Data Tiering in AWS aktivieren, verwendet Cloud Volumes ONTAP EBS als Performance-Tier für häufig genutzte Daten und Amazon Simple Storage Service (Amazon S3) als Kapazitäts-Tier für inaktive Daten.
- Leistungsstufe
-
Die Leistungsstufe kann aus General Purpose SSDs (gp3 oder gp2) oder Provisioned IOPS SSDs (io1) bestehen.
Bei Verwendung von durchsatzoptimierten HDDs (st1) wird das Tiering von Daten in Objektspeicher nicht empfohlen.
- Kapazitätsstufe
-
Ein Cloud Volumes ONTAP -System ordnet inaktive Daten einem einzelnen S3-Bucket zu.
Die NetApp Console erstellt für jedes System einen einzelnen S3-Bucket und nennt ihn Fabric-Pool-Cluster Unique Identifier. Es wird nicht für jedes Volume ein anderer S3-Bucket erstellt.
Wenn die Konsole den S3-Bucket erstellt, verwendet sie die folgenden Standardeinstellungen:
-
Speicherklasse: Standard
-
Standardverschlüsselung: Deaktiviert
-
Öffentlichen Zugriff blockieren: Den gesamten öffentlichen Zugriff blockieren
-
Objektbesitz: ACLs aktiviert
-
Bucket-Versionierung: Deaktiviert
-
Objektsperre: Deaktiviert
-
- Speicherklassen
-
Die Standardspeicherklasse für mehrstufige Daten in AWS ist Standard. Standard ist ideal für häufig abgerufene Daten, die in mehreren Verfügbarkeitszonen gespeichert sind.
Wenn Sie nicht vorhaben, auf die inaktiven Daten zuzugreifen, können Sie Ihre Speicherkosten senken, indem Sie die Speicherklasse in eine der folgenden ändern: Intelligent Tiering, One-Zone Infrequent Access, Standard-Infrequent Access oder S3 Glacier Instant Retrieval. Wenn Sie die Speicherklasse ändern, beginnen inaktive Daten in der Standardspeicherklasse und wechseln in die von Ihnen ausgewählte Speicherklasse, wenn nach 30 Tagen nicht auf die Daten zugegriffen wird.
Wenn Sie auf die Daten zugreifen, sind die Zugriffskosten höher. Berücksichtigen Sie dies daher, bevor Sie die Speicherklasse ändern. "Amazon S3-Dokumentation: Weitere Informationen zu Amazon S3-Speicherklassen" .
Sie können beim Erstellen des Systems eine Speicherklasse auswählen und diese später jederzeit ändern. Anweisungen zum Ändern der Speicherklasse finden Sie unter"Verschieben Sie inaktive Daten in kostengünstige Objektspeicher" .
Die Speicherklasse für die Datenschichtung gilt systemweit, nicht pro Datenträger.
Datentiering in Azure
Wenn Sie das Daten-Tiering in Azure aktivieren, verwendet Cloud Volumes ONTAP Azure Managed Disks als Leistungsebene für Hot Data und Azure Blob Storage als Kapazitätsebene für inaktive Daten.
- Leistungsstufe
-
Die Leistungsstufe kann entweder aus SSDs oder HDDs bestehen.
- Kapazitätsstufe
-
Ein Cloud Volumes ONTAP -System ordnet inaktive Daten einem einzelnen Blob-Container zu.
Die Konsole erstellt für jedes Cloud Volumes ONTAP -System ein neues Speicherkonto mit einem Container. Der Name des Speicherkontos ist zufällig. Es wird nicht für jedes Volume ein anderer Container erstellt.
Die Konsole erstellt das Speicherkonto mit den folgenden Einstellungen:
-
Zugriffsebene: Hot
-
Leistung: Standard
-
Redundanz: Entsprechend der Cloud Volume ONTAP -Bereitstellung
-
Einzelne Verfügbarkeitszone: Lokal redundanter Speicher (LRS)
-
Mehrere Verfügbarkeitszonen: Zonenredundanter Speicher (ZRS)
-
-
Konto: StorageV2 (allgemeiner Zweck v2)
-
Sichere Übertragung für REST-API-Operationen erforderlich: Aktiviert
-
Zugriff auf Speicherkontoschlüssel: Aktiviert
-
Mindestens TLS-Version: Version 1.2
-
Infrastrukturverschlüsselung: Deaktiviert
-
- Speicherzugriffsebenen
-
Die Standardspeicherzugriffsebene für mehrstufige Daten in Azure ist die Hot-Ebene. Die Hot-Tier-Ebene ist ideal für häufig abgerufene Daten in der Kapazitätsebene.
Wenn Sie nicht vorhaben, auf die inaktiven Daten in der Kapazitätsebene zuzugreifen, können Sie die coole Speicherebene wählen, in der die inaktiven Daten mindestens 30 Tage lang aufbewahrt werden. Sie können sich auch für die kalte Stufe entscheiden, bei der die inaktiven Daten mindestens 90 Tage lang gespeichert werden. Basierend auf Ihren Speicheranforderungen und Kostenüberlegungen können Sie die Stufe auswählen, die Ihren Anforderungen am besten entspricht. Wenn Sie die Speicherebene auf cool oder cold ändern, werden die Daten der inaktiven Kapazitätsebene direkt in die Speicherebene „cool“ oder „cold“ verschoben. Die kühlen und kalten Ebenen bieten im Vergleich zur heißen Ebene geringere Speicherkosten, sind jedoch mit höheren Zugriffskosten verbunden. Berücksichtigen Sie dies, bevor Sie die Speicherebene ändern. Siehe "Microsoft Azure-Dokumentation: Weitere Informationen zu Azure Blob Storage-Zugriffsebenen" .
Sie können eine Speicherebene auswählen, wenn Sie ein Cloud Volumes ONTAP -System hinzufügen, und diese später jederzeit ändern. Einzelheiten zum Ändern der Speicherebene finden Sie unter"Verschieben Sie inaktive Daten in kostengünstige Objektspeicher" .
Die Speicherzugriffsebene für die Datenschichtung gilt systemweit und nicht pro Datenträger.
Daten-Tiering in Google Cloud
Wenn Sie Data Tiering in Google Cloud aktivieren, verwendet Cloud Volumes ONTAP persistente Festplatten als Performance-Tier für häufig genutzte Daten und einen Google Cloud Storage Bucket als Kapazitäts-Tier für inaktive Daten. Eine Speicherebene kann beim Erstellen eines Systems ausgewählt und jederzeit danach geändert werden. Informationen zum Ändern der Speicherklasse finden sich unter "Verschieben Sie inaktive Daten in kostengünstige Objektspeicher".
- Leistungsstufe
-
Die Leistungsstufe kann entweder aus persistenten SSD-Festplatten, ausgeglichenen persistenten Festplatten oder persistenten Standardfestplatten bestehen.
- Kapazitätsstufe
-
Ein Cloud Volumes ONTAP -System verteilt inaktive Daten auf einen einzelnen Google Cloud Storage-Bucket.
Die Konsole erstellt für jedes System einen Bucket und nennt ihn fabric-pool-cluster unique identifier. Es wird nicht für jedes Volume ein anderer Bucket erstellt.
Wenn die Konsole den Bucket erstellt, verwendet sie die folgenden Standardeinstellungen:
-
Standorttyp: Region
-
Speicherklasse: Standard
-
Öffentlicher Zugriff: Vorbehaltlich der Objekt-ACLs
-
Zugriffskontrolle: Feinkörnig
-
Schutz: Keiner
-
Datenverschlüsselung: Von Google verwalteter Schlüssel
-
- Speicherklassen
-
Google Cloud verwendet "Speicherklassen" zur Verwaltung von Kosten und Datenverfügbarkeit. Es wird empfohlen, die Speicherklasse entsprechend der erwarteten Datenzugriffshäufigkeit auszuwählen, da der Datenzugriff mit höheren Kosten verbunden ist. Die Standard Storage-Klasse für gestaffelte Daten ist Standard Storage. Sofern nicht manuell geändert, behalten alle inaktiven Daten die Standard Storage-Klasse bei. Zum Ändern der Speicherklasse inaktiver Daten siehe "Google Cloud Dokumentation: Verwaltung von Objektlebenszyklen".
Die Speicherklasse für die Datenschichtung gilt systemweit, nicht pro Datenträger.
Daten-Tiering und Kapazitätsgrenzen
Wenn Sie Data Tiering aktivieren, bleibt die Kapazitätsgrenze eines Systems gleich. Das Limit ist auf die Leistungsstufe und die Kapazitätsstufe verteilt.
Richtlinien für die Datenträgereinteilung
Um Data Tiering zu aktivieren, müssen Sie beim Erstellen, Ändern oder Replizieren eines Volumes eine Volume-Tiering-Richtlinie auswählen. Sie können für jedes Volume eine andere Richtlinie auswählen.
Einige Tiering-Richtlinien verfügen über eine zugehörige Mindestkühlperiode, die die Zeit festlegt, die Benutzerdaten in einem Volume inaktiv bleiben müssen, damit die Daten als „kalt“ betrachtet und in die Kapazitätsebene verschoben werden. Die Abkühlphase beginnt, wenn Daten in das Aggregat geschrieben werden.

|
Sie können die Mindestkühlperiode und den Standard-Gesamtschwellenwert von 50 % ändern (mehr dazu weiter unten). "Erfahren Sie, wie Sie die Kühlperiode ändern" Und "Erfahren Sie, wie Sie den Schwellenwert ändern" . |
Die Konsole ermöglicht Ihnen beim Erstellen oder Ändern eines Volumes die Auswahl aus den folgenden Volume-Tiering-Richtlinien:
- Nur Schnappschuss
-
Nachdem ein Aggregat 50 % seiner Kapazität erreicht hat, verschiebt Cloud Volumes ONTAP kalte Benutzerdaten von Snapshot-Kopien, die nicht mit dem aktiven Dateisystem verknüpft sind, in die Kapazitätsebene. Die Abkühlzeit beträgt ca. 2 Tage.
Beim Lesen werden kalte Datenblöcke auf der Kapazitätsebene zu heißen Datenblöcken und werden auf die Leistungsebene verschoben.
- Alle
-
Alle Daten (ohne Metadaten) werden sofort als „kalt“ markiert und so schnell wie möglich in den Objektspeicher verschoben. Es ist nicht erforderlich, 48 Stunden zu warten, bis neue Blöcke in einem Volume kalt werden. Beachten Sie, dass Blöcke, die sich vor dem Festlegen der Richtlinie „Alle“ im Volume befanden, 48 Stunden benötigen, um kalt zu werden.
Beim Lesen bleiben kalte Datenblöcke auf der Cloud-Ebene kalt und werden nicht auf die Leistungsebene zurückgeschrieben. Diese Richtlinie ist ab ONTAP 9.6 verfügbar.
- Automatisch
-
Nachdem ein Aggregat 50 % seiner Kapazität erreicht hat, ordnet Cloud Volumes ONTAP kalte Datenblöcke in einem Volume einer Kapazitätsebene zu. Zu den kalten Daten gehören nicht nur Snapshot-Kopien, sondern auch kalte Benutzerdaten aus dem aktiven Dateisystem. Die Kühlperiode beträgt ca. 31 Tage.
Diese Richtlinie wird ab Cloud Volumes ONTAP 9.4 unterstützt.
Beim Lesen durch zufällige Lesevorgänge werden die kalten Datenblöcke in der Kapazitätsebene heiß und werden in die Leistungsebene verschoben. Beim Lesen durch sequenzielle Lesevorgänge, wie sie beispielsweise bei Index- und Antivirenscans auftreten, bleiben die kalten Datenblöcke kalt und werden nicht in die Leistungsebene verschoben.
- Keine
-
Behält die Daten eines Volumes in der Leistungsstufe und verhindert, dass sie in die Kapazitätsstufe verschoben werden.
Wenn Sie ein Volume replizieren, können Sie wählen, ob die Daten in den Objektspeicher verschoben werden sollen. Wenn Sie dies tun, wendet die Konsole die Backup-Richtlinie auf das Datensicherungsvolume an. Ab Cloud Volumes ONTAP 9.6 ersetzt die Tiering-Richtlinie All die Sicherungsrichtlinie. Wenn eine Replikationsbeziehung gelöscht wird, behält das Zielvolume die Tiering-Richtlinie bei, die während der Replikation gültig war.
Das Ausschalten von Cloud Volumes ONTAP wirkt sich auf die Abkühlphase aus
Datenblöcke werden durch Kühlscans gekühlt. Bei diesem Vorgang wird die Blocktemperatur nicht verwendeter Blöcke auf den nächstniedrigeren Wert verschoben (abgekühlt). Die standardmäßige Abkühlzeit hängt von der Volume-Tiering-Richtlinie ab:
-
Auto: 31 Tage
-
Nur Schnappschuss: 2 Tage
Damit der Kühlungsscan funktioniert, muss Cloud Volumes ONTAP ausgeführt werden. Wenn Cloud Volumes ONTAP ausgeschaltet wird, wird auch die Kühlung gestoppt. Dadurch kann es zu längeren Abkühlzeiten kommen.
|
|
Wenn Cloud Volumes ONTAP ausgeschaltet ist, bleibt die Temperatur jedes Blocks erhalten, bis Sie das System neu starten. Wenn beispielsweise die Temperatur eines Blocks beim Ausschalten des Systems 5 beträgt, beträgt die Temperatur auch beim erneuten Einschalten des Systems noch immer 5. |
Einrichten von Daten-Tiering
Anweisungen und eine Liste der unterstützten Konfigurationen finden Sie unter"Verschieben Sie inaktive Daten in kostengünstige Objektspeicher" .