

Ermitteln und Aufheben fehlgeschlagener Storage Volumes
 Änderungen vorschlagen
Änderungen vorschlagen
Bei der Wiederherstellung eines Storage-Nodes mit ausgefallenen Storage-Volumes müssen Sie die ausgefallenen Volumes identifizieren und deren Bereitstellung aufheben. Sie müssen überprüfen, ob nur die fehlgeschlagenen Speicher-Volumes im Rahmen der Wiederherstellungsverfahren neu formatiert werden.
Sie sind mit einem bei Grid Manager angemeldet "Unterstützter Webbrowser".
Sie sollten ausgefallene Storage Volumes so bald wie möglich wiederherstellen.
Der erste Schritt des Wiederherstellungsprozesses besteht darin, Volumes zu erkennen, die entfernt wurden, abgehängt werden müssen oder I/O-Fehler haben. Wenn weiterhin fehlgeschlagene Volumes angehängt sind, aber ein zufällig beschädigtes Dateisystem vorhanden ist, erkennt das System möglicherweise keine Beschädigung in nicht verwendeten oder nicht zugewiesenen Teilen der Festplatte.

|
Sie müssen dieses Verfahren abschließen, bevor Sie manuelle Schritte zur Wiederherstellung von Volumes durchführen, z. B. das Hinzufügen oder erneutes Anschließen von Festplatten, das Anhalten des Node, Starten des Node oder Neustarten. Andernfalls, wenn Sie den ausführen reformat_storage_block_devices.rb Skript, möglicherweise tritt ein Dateisystemfehler auf, der zum Aufhängen oder Fehlschlagen des Skripts führt.
|
|
|
Reparieren Sie die Hardware und schließen Sie die Festplatten ordnungsgemäß an, bevor Sie den ausführen reboot Befehl.
|

|
Fehlerhafte Storage-Volumes sorgfältig ermitteln Anhand dieser Informationen können Sie überprüfen, welche Volumes neu formatiert werden müssen. Nachdem ein Volume neu formatiert wurde, können Daten auf dem Volume nicht wiederhergestellt werden. |
Um fehlgeschlagene Speicher-Volumes korrekt wiederherzustellen, müssen Sie sowohl die Gerätenamen der ausgefallenen Speicher-Volumes als auch die zugehörigen Volume-IDs kennen.
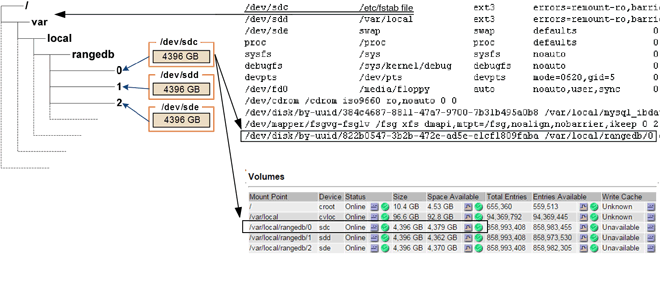
Bei der Installation wird jedem Storage-Gerät eine UUID (Universal Unique Identifier) des Filesystems zugewiesen und über die zugewiesene Filesystem-UUID in ein rangedb-Verzeichnis auf dem Storage Node gemountet. Die UUID des Dateisystems und das Verzeichnis „rangedb“ sind im aufgeführt /etc/fstab Datei: Der Gerätename, das rankgedb-Verzeichnis und die Größe des gemounteten Volumes werden im Grid Manager angezeigt.
Im folgenden Beispiel ist das Gerät /dev/sdc Hat eine Volume-Größe von 4 TB, wird angehängt auf /var/local/rangedb/0, Verwenden des Gerätenamens /dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba Im /etc/fstab Datei:
-
Führen Sie die folgenden Schritte durch, um die fehlgeschlagenen Speicher-Volumes und deren Gerätenamen aufzunehmen:
-
Wählen Sie SUPPORT > Tools > Grid-Topologie aus.
-
Wählen Sie Standort > fehlgeschlagener Speicherknoten > LDR > Storage > Übersicht > Haupt, und suchen Sie nach Objektspeichern mit Alarmen.

-
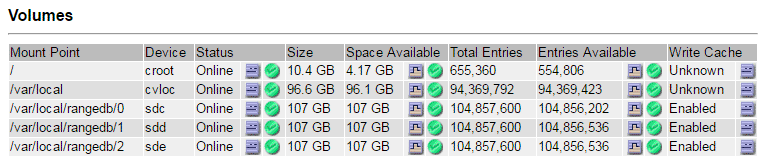
Wählen Sie Standort > fehlgeschlagener Speicherknoten > SSM > Ressourcen > Übersicht > Haupt. Ermitteln Sie den Mount-Punkt und die Volume-Größe jedes im vorherigen Schritt identifizierten ausgefallenen Storage-Volumes.
Objektspeichern werden in Hex-Notation nummeriert. Zum Beispiel ist 0000 das erste Volumen und 000F das sechzehnte Volumen. Im Beispiel entspricht der Objektspeicher mit der ID 0000
/var/local/rangedb/0Mit dem Gerätenamen sdc und einer Größe von 107 GB.
-
-
Melden Sie sich beim fehlgeschlagenen Speicherknoten an:
-
Geben Sie den folgenden Befehl ein:
ssh admin@grid_node_IP -
Geben Sie das im aufgeführte Passwort ein
Passwords.txtDatei: -
Geben Sie den folgenden Befehl ein, um zum Root zu wechseln:
su - -
Geben Sie das im aufgeführte Passwort ein
Passwords.txtDatei:
Wenn Sie als root angemeldet sind, ändert sich die Eingabeaufforderung von
$Bis#. -
-
Führen Sie das folgende Skript aus, um die Bereitstellung eines ausgefallenen Speichervolume aufzuheben:
sn-unmount-volume object_store_IDDer
object_store_IDIst die ID des ausgefallenen Speicher-Volumes. Geben Sie beispielsweise an0Im Befehl für einen Objektspeicher mit der ID 0000. -
Wenn Sie dazu aufgefordert werden, drücken Sie y, um den Cassandra-Service abhängig von Speichervolume 0 zu beenden.
Wenn der Cassandra-Dienst bereits angehalten wurde, werden Sie nicht dazu aufgefordert. Der Cassandra-Service wird nur für Volume 0 angehalten. root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
In einigen Sekunden wird das Volume abgehängt. Die Meldungen werden angezeigt, die jeden Schritt des Prozesses angeben. Die letzte Meldung gibt an, dass das Volume abgehängt wurde.
-
Wenn das Unmounten fehlschlägt, weil das Volume ausgelastet ist, können Sie das Unmounten mithilfe des erzwingen
--use-umountofOption:
Erzwingen eines Unmounting mithilfe des --use-umountofDie Option kann dazu führen, dass sich Prozesse oder Dienste, die das Volume verwenden, unerwartet verhalten oder abstürzen.root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes