

Hadoop S3A-Tuning
 Änderungen vorschlagen
Änderungen vorschlagen
Von Angela Cheng
Der Hadoop S3A Connector ermöglicht die nahtlose Interaktion zwischen Hadoop-basierten Applikationen und S3 Objektspeicher. Um die Performance bei der Arbeit mit S3-Objektspeicher zu optimieren, ist die Anpassung des Hadoop S3A Connector unerlässlich. Bevor wir uns mit der Feinabstimmung befassen, wollen wir zunächst ein grundlegendes Verständnis von Hadoop und seinen Komponenten haben.
Was ist Hadoop?
Hadoop ist ein leistungsfähiges Open-Source-Framework, das für die Verarbeitung und Speicherung großer Datenmengen entwickelt wurde. Sie ermöglicht verteilte Speicherung und parallele Verarbeitung über Cluster von Computern hinweg.
Die drei Kernkomponenten von Hadoop sind:
-
Hadoop HDFS (Hadoop Distributed File System): Dies verarbeitet Speicherung, teilt Daten in Blöcke auf und verteilt sie über Knoten.
-
Hadoop MapReduce: Verantwortlich für die Verarbeitung der Daten durch Aufteilen von Aufgaben in kleinere Blöcke und deren parallele Ausführung.
-
Hadoop YARN (noch ein weiterer Resource Negotiator): "Managt Ressourcen und plant Aufgaben effizient"
Hadoop HDFS- und S3A-Steckverbinder
HDFS ist eine wichtige Komponente des Hadoop Ecosystems und spielt eine entscheidende Rolle bei der effizienten Verarbeitung von Big Data. HDFS ermöglicht zuverlässige Speicherung und Verwaltung. Sie ermöglicht die parallele Verarbeitung und optimiert den Datenspeicher, was zu schnellerem Datenzugriff und schnelleren Analysen führt.
Bei der Big Data-Verarbeitung überzeugt HDFS durch fehlertoleranten Storage für große Datensätze. Es erreicht dies durch Datenreplikation. Die IT kann große Mengen strukturierter und unstrukturierter Daten in einer Data Warehouse-Umgebung speichern und managen. Darüber hinaus lässt sich die Software nahtlos in führende Big Data Processing Frameworks wie Apache Spark, Hive, Pig und Flink integrieren und ermöglicht so eine skalierbare und effiziente Datenverarbeitung. Er ist mit Unix-basierten (Linux) Betriebssystemen kompatibel und somit eine ideale Wahl für Unternehmen, die Linux-basierte Umgebungen für ihre Big-Data-Verarbeitung bevorzugen.
Mit der Zeit wuchs das Datenvolumen. Daher ist es ineffizient, dem Hadoop Cluster neue Maschinen mit eigenen Computing- und Storage-Ressourcen hinzuzufügen. Lineare Skalierung führt zu Herausforderungen bei der effizienten Nutzung von Ressourcen und dem Management der Infrastruktur.
Als Antwort auf diese Herausforderungen bietet der Hadoop S3A Connector hochperformante I/O für S3 Objekt-Storage. Durch die Implementierung eines Hadoop Workflows mit S3A können Sie Objekt-Storage als Daten-Repository nutzen und Computing- und Storage-Ressourcen separat voneinander skalieren. Dadurch wiederum können Sie Computing- und Storage-Ressourcen unabhängig voneinander skalieren. Die Abkopplung von Computing und Storage erlaubt es Ihnen auch, die richtige Menge an Ressourcen für Ihre Compute-Jobs bereitzustellen und die Kapazität abhängig von der Größe des Datensatzes bereitzustellen. Somit lassen sich die Gesamtbetriebskosten für Hadoop Workflows verringern.
Hadoop S3A Connector Tuning
S3 verhält sich anders als HDFS, und einige Versuche, das Aussehen eines Filesystems beizubehalten, sind aggressiv suboptimal. Um die S3-Ressourcen möglichst effizient zu nutzen, sind sorgfältiges Tuning/Testen/Experimentieren erforderlich.
Die Hadoop Optionen in diesem Dokument basieren auf Hadoop 3.3.5, siehe "Hadoop 3.3.5 core-site.xml" Für alle verfügbaren Optionen.
Hinweis – einige Hadoop fs.s3a Einstellungen sind in den jeweiligen Hadoop Versionen unterschiedlich. Überprüfen Sie unbedingt den Standardwert Ihrer aktuellen Hadoop Version. Werden diese Einstellungen nicht in Hadoop core-site.xml angegeben, so wird als Standardwert verwendet. Sie können den Wert zur Laufzeit mithilfe der Konfigurationsoptionen Spark oder Hive überschreiben.
Sie müssen zu diesem gehen "Apache Hadoop Seite aufrufen" Um die einzelnen Optionen von fs.s3a zu verstehen. Testen Sie diese nach Möglichkeit im nicht produktiven Hadoop Cluster, um die optimalen Werte zu ermitteln.
Sie sollten lesen "Maximale Leistung bei der Arbeit mit dem S3A-Steckverbinder" Für weitere Optimierungsempfehlungen.
Sehen wir uns einige wichtige Überlegungen an:
1. Datenkomprimierung
Aktivieren Sie die StorageGRID-Komprimierung nicht. Die meisten Big-Data-Systeme verwenden Byte-Bereich get, anstatt das gesamte Objekt abzurufen. Die Verwendung von Byte Range Get mit komprimierten Objekten beeinträchtigt die GET-Performance erheblich.
2. S3A Committer
Generell wird Magic s3a Committer empfohlen. Weitere Informationen finden Sie hier "Allgemeine Seite mit den Optionen für den S3A-Committer" Um ein besseres Verständnis von Magic Committer und den damit verbundenen s3a-Einstellungen zu bekommen.
Magic Committer:
Der Magic Committer setzt speziell auf S3Guard, um konsistente Verzeichnisauflistungen im S3-Objektspeicher zu bieten.
Mit konsistenten S3 (was jetzt der Fall ist), kann der Magic Committer sicher mit jedem S3-Bucket verwendet werden.
Auswahl und Experimentieren:
Je nach Anwendungsfall können Sie zwischen dem Staging Committer (der auf einem Cluster HDFS-Dateisystem basiert) und dem Magic Committer wählen.
Experimentieren Sie mit beiden, um zu ermitteln, welche Lösung am besten zu Ihrem Workload und Ihren Anforderungen passt.
Zusammenfassend stellen die S3A Committers eine Lösung für die grundlegende Herausforderung dar, die ein konsistentes, leistungsstarkes und zuverlässiges Leistungsengagement für S3 darstellt. Das interne Design gewährleistet einen effizienten Datentransfer bei gleichzeitiger Wahrung der Datenintegrität.
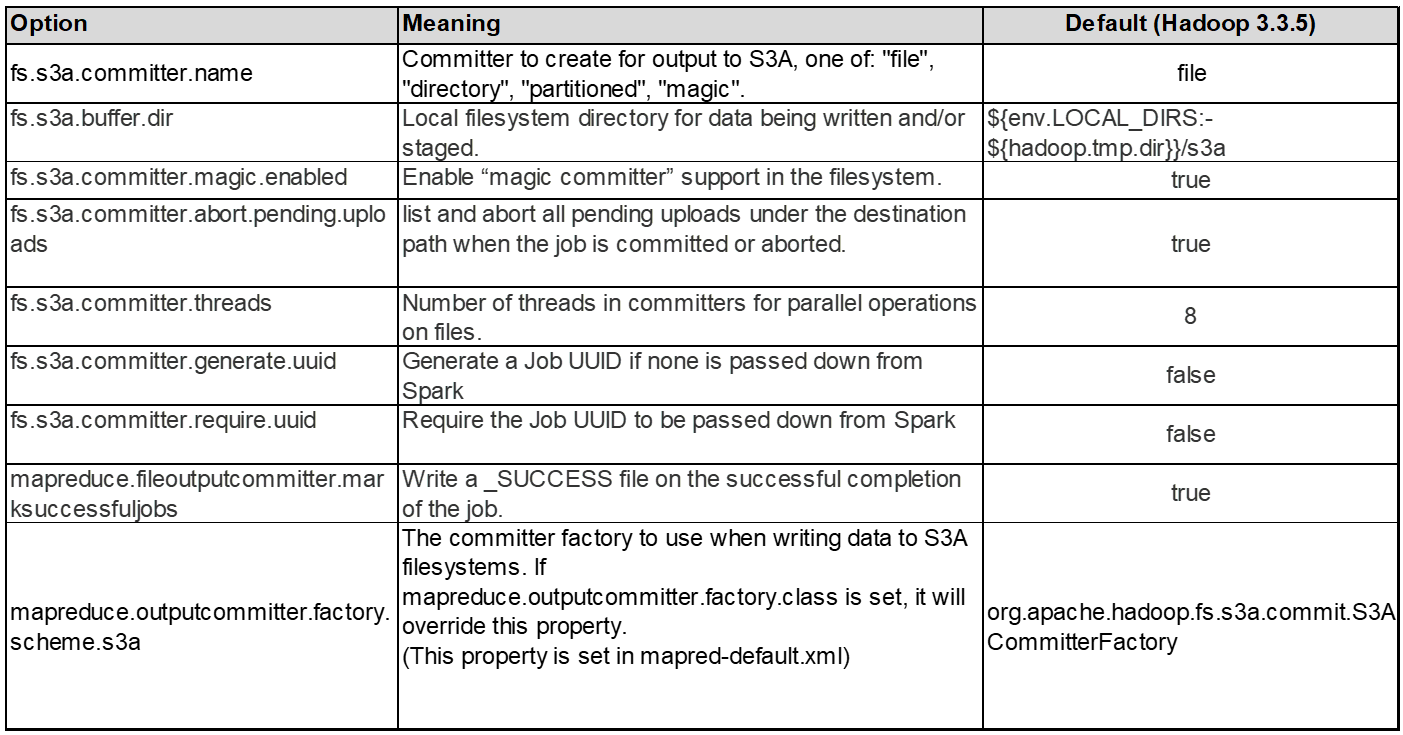
3. Thread, Größe des Verbindungspools und Blockgröße
-
Jeder S3A-Client, der mit einem einzelnen Bucket interagiert, hat einen eigenen dedizierten Pool von offenen HTTP 1.1-Verbindungen und Threads für Upload- und Kopiervorgänge.
-
Beim Hochladen von Daten in S3 werden sie in Blöcke unterteilt. Die standardmäßige Blockgröße beträgt 32 MB. Sie können diesen Wert anpassen, indem Sie die Eigenschaft fs.s3a.Block.size festlegen.
-
Größere Blockgrößen verbessern die Performance beim Hochladen großer Daten, da sich der Managementaufwand für mehrteilige Teile während des Uploads verringert. Der empfohlene Wert ist 256 MB oder höher für große Datensätze.
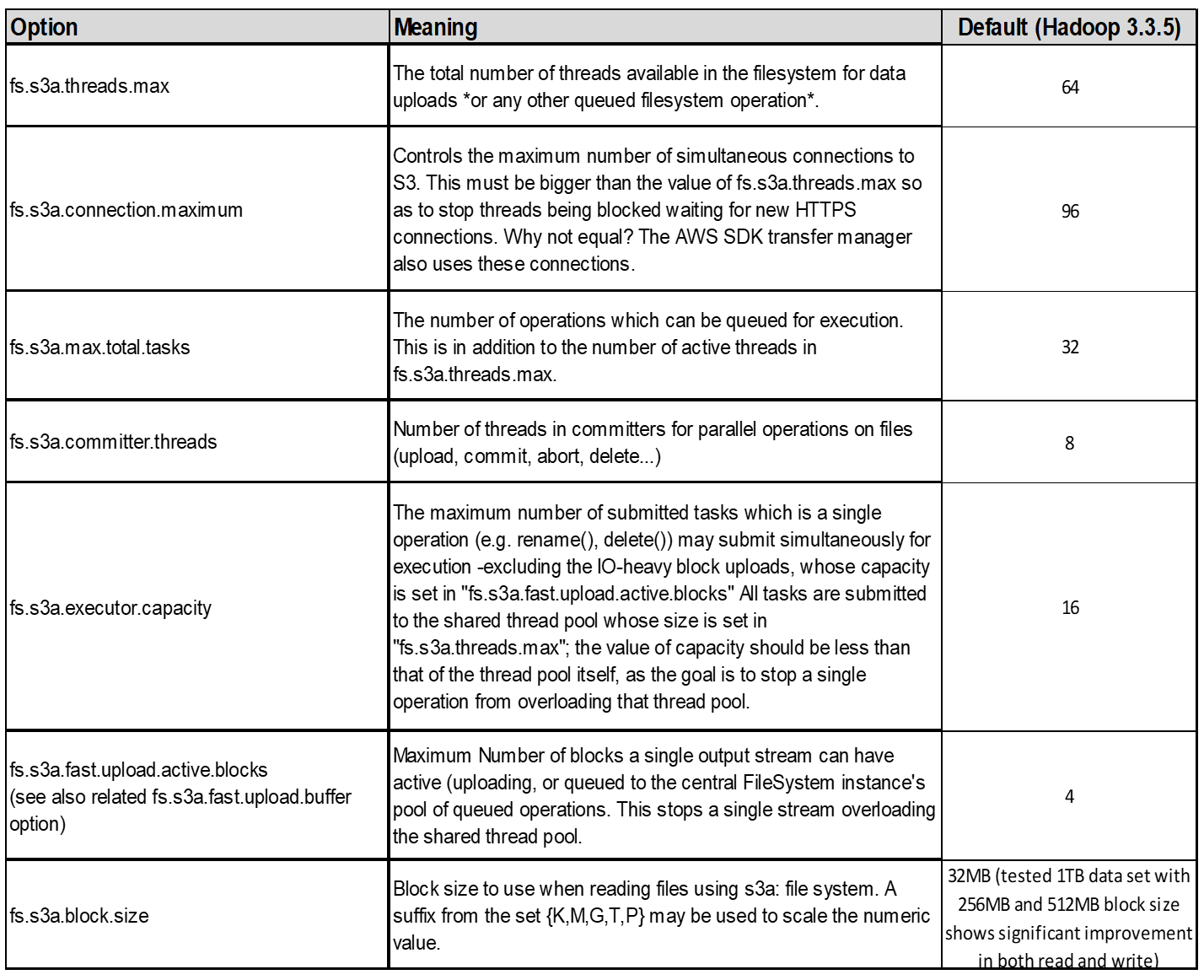
4. Mehrteiliges Hochladen
s3a-Committer Always Verwenden Sie MPU (mehrteilige Uploads) zum Hochladen von Daten in s3-Buckets. Dies ist erforderlich, um Folgendes zu ermöglichen: Task Failure, spekulative Ausführung von Aufgaben und Job Abbrüche vor Commit. Hier sind einige wichtige Spezifikationen für mehrteilige Uploads:
-
Maximale Objektgröße: 5 tib (Terabyte).
-
Maximale Anzahl von Teilen pro Upload: 10,000.
-
Teilenummern: Von 1 bis 10,000 (inklusive).
-
Größe des Teils: Zwischen 5 MiB und 5 gib. Insbesondere gibt es keine Mindestgröße für den letzten Teil Ihres mehrteiligen Uploads.
Die Verwendung kleinerer Teilgröße für S3-Multipart-Uploads hat sowohl vor- als auch Nachteile.
Vorteile:
-
Schnelle Wiederherstellung von Netzwerkproblemen: Wenn Sie kleinere Teile hochladen, werden die Auswirkungen des Neustarts eines fehlgeschlagenen Uploads aufgrund eines Netzwerkfehlers minimiert. Wenn ein Teil fehlschlägt, müssen Sie nur dieses Teil neu hochladen, nicht das gesamte Objekt.
-
Bessere Parallelisierung: Mehr Teile können parallel hochgeladen werden, wobei Multi-Threading oder gleichzeitige Verbindungen genutzt werden können. Diese Parallelisierung verbessert die Performance, insbesondere bei der Verarbeitung großer Dateien.
Nachteil:
-
Netzwerk-Overhead: Kleinere Teilegröße bedeutet, dass mehr Teile hochgeladen werden müssen, jedes Teil benötigt eine eigene HTTP-Anforderung. Mehr HTTP-Anfragen erhöhen den Overhead beim Initiieren und Abschließen einzelner Anfragen. Die Verwaltung einer großen Anzahl von Kleinteilen kann die Leistung beeinträchtigen.
-
Komplexität: Die Verwaltung der Bestellung, die Nachverfolgung von Teilen und die Sicherstellung erfolgreicher Uploads können umständlich sein. Wenn der Upload abgebrochen werden muss, müssen alle bereits hochgeladenen Teile nachverfolgt und gelöscht werden.
Für Hadoop wird eine Teilegröße von 256 MB oder höher für fs.s3a.Multipart.size empfohlen. Stellen Sie immer den Wert fs.s3a.mutlipart.threshold auf 2 x fs.s3a.multipart.size ein. Beispiel: Fs.s3a.multipart.size = 256M, fs.s3a.mutlipart.threshold sollte 512M sein.
Größere Teilegröße für großen Datensatz verwenden Es ist wichtig, eine Teilegröße zu wählen, die diese Faktoren auf der Grundlage Ihres spezifischen Anwendungsfalls und der Netzwerkbedingungen ausgleicht.
Ein mehrteiliges Hochladen ist ein "Prozess in drei Schritten":
-
Der Upload wird gestartet, StorageGRID gibt eine Upload-ID zurück.
-
Die Objektteile werden mit der Upload-ID hochgeladen.
-
Sobald alle Objektteile hochgeladen sind, sendet die komplette mehrteilige Upload-Anfrage mit Upload-ID. StorageGRID erstellt das Objekt aus den hochgeladenen Teilen, und der Client kann auf das Objekt zugreifen.
Wenn die Anfrage zum vollständigen Hochladen mehrerer Teile nicht erfolgreich gesendet wird, bleiben die Teile in StorageGRID und erstellen kein Objekt. Dies geschieht, wenn Jobs unterbrochen, fehlgeschlagen oder abgebrochen werden. Die Teile verbleiben im Raster, bis der Upload mehrerer Teile abgeschlossen ist oder abgebrochen wird oder StorageGRID diese Teile löscht, wenn 15 Tage nach dem Upload vergangen sind. Wenn sich viele (einige Hunderttausend bis Millionen) mehrteilige Uploads in einem Bucket befinden und Hadoop ‘list-Multipart-Uploads’ sendet (diese Anfrage filtert nicht nach Upload-id), kann die Bearbeitung der Anfrage sehr viel Zeit in Anspruch nehmen oder eventuell eine bestimmte Zeit in Anspruch nehmen. Sie können die Einstellung fs.s3a.mutlipart.purge mit dem entsprechenden Wert fs.s3a.Multipart.purge.age (z. B. 5 bis 7 Tage, verwenden Sie den Standardwert 86400, d. h. 1 Tag) auf true setzen. Oder wenden Sie sich an den NetApp Support, um die Situation zu untersuchen.
5. Pufferschreibdaten im Speicher
Zur Verbesserung der Performance können Sie Schreibdaten vor dem Hochladen in S3 zwischenspeichern. Dies kann die Anzahl kleiner Schreibvorgänge reduzieren und die Effizienz verbessern.

S3 und HDFS funktionieren jedoch auf unterschiedliche Weise. Um die S3-Ressourcen optimal zu nutzen, sind sorgfältiges Tuning/Test/Experiment nötig.