

Wie Audit-Meldungen durch das StorageGRID System in die Datei audit.log zur Aufbewahrung gelangen
 Änderungen vorschlagen
Änderungen vorschlagen
Alle StorageGRID-Services generieren während des normalen Systembetriebs Audit-Meldungen. Sie sollten verstehen, wie diese Meldungen über das StorageGRID-System in die Datei verschoben audit.log werden.
Die folgenden Workflows für Audit-Nachrichten und die Aufbewahrung von Audit-Nachrichten sind nur anwendbar, wenn StorageGRID für Admin-Knoten/lokale Knoten oder Admin-Knoten und externen Syslog-Server konfiguriert ist. Wenn StorageGRID für "Nur lokale Knoten" (Standard) oder "Externer Syslog-Server" konfiguriert ist, werden die Audit-Meldungen lokal auf jedem Knoten im /var/local/log/localaudit.log Datei und kann nicht von Admin-Knoten oder Speicherknoten verarbeitet werden.
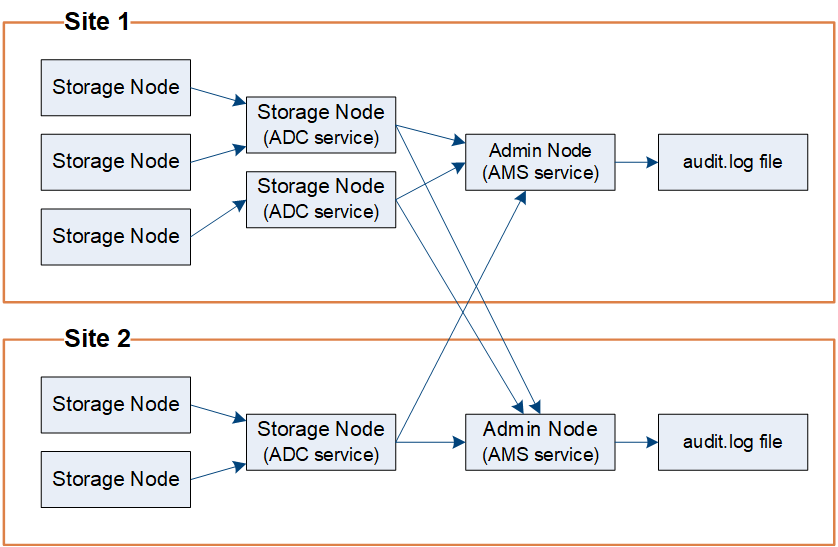
Audit-Nachrichtenfluss
Audit-Nachrichten werden von Admin-Knoten verarbeitet, wenn StorageGRID für Admin-Knoten/lokale Knoten oder Admin-Knoten und externen Syslog-Server konfiguriert ist, und von den Storage-Knoten, die über einen Administrative Domain Controller (ADC)-Dienst verfügen.
Wie im Überwachungsmeldung-Flow-Diagramm dargestellt, sendet jeder StorageGRID Node seine Audit-Meldungen an einen der ADC-Services am Datacenter-Standort. Der ADC-Dienst wird automatisch für die ersten drei Speicherknoten aktiviert, die an jedem Standort installiert sind.
Jeder ADC-Dienst fungiert wiederum als Relais und sendet seine Sammlung von Audit-Meldungen an jeden Admin-Knoten im StorageGRID-System, wodurch jeder Admin-Knoten einen vollständigen Datensatz der Systemaktivität erhält.
Jeder Admin-Knoten speichert Überwachungsmeldungen in Textprotokolldateien; die aktive Protokolldatei wird mit dem Namen audit.log.
Aufbewahrung von Überwachungsnachrichten
StorageGRID verwendet einen Kopier- und Löschprozess, um sicherzustellen, dass keine Audit-Meldungen verloren gehen, bevor sie in das Audit-Protokoll geschrieben werden.
Wenn ein Knoten eine Prüfnachricht generiert oder weiterleitet, wird die Nachricht in einer Prüfnachrichtenwarteschlange auf der Systemfestplatte des Grid-Knotens gespeichert. Eine Kopie der Nachricht wird immer in einer Audit-Nachrichtenwarteschlange aufbewahrt, bis die Nachricht in die Audit-Protokolldatei im Admin-Knoten geschrieben wird. /var/local/audit/export Verzeichnis. Dadurch wird verhindert, dass während des Transports eine Prüfnachricht verloren geht.
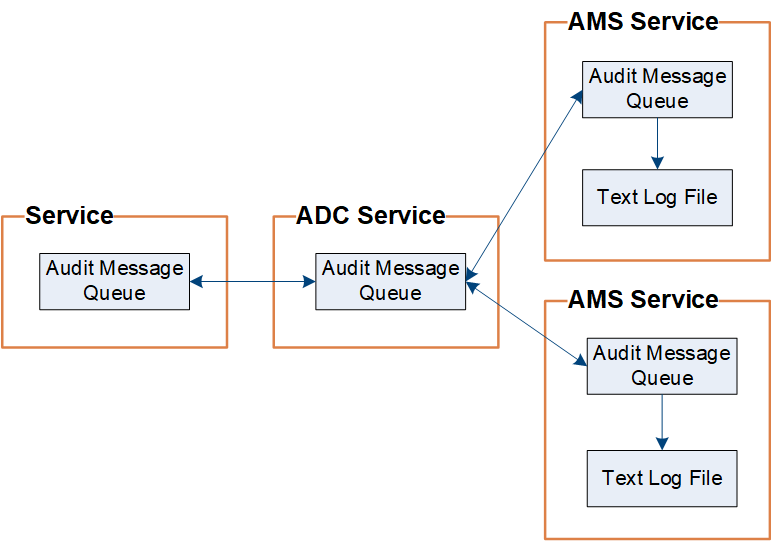
Die Warteschlange der Prüfnachrichten kann aufgrund von Netzwerkverbindungsproblemen oder unzureichender Prüfkapazität vorübergehend größer werden. Wenn die Warteschlangen größer werden, verbrauchen sie mehr verfügbaren Speicherplatz in den einzelnen Knoten. /var/local/ Verzeichnis. Wenn das Problem weiterhin besteht und das Prüfnachrichtenverzeichnis eines Knotens zu voll wird, priorisieren die einzelnen Knoten die Verarbeitung ihres Rückstands und sind vorübergehend für neue Nachrichten nicht verfügbar.
Sie können insbesondere folgende Verhaltensweisen erkennen:
-
Wenn die
/var/local/audit/exportWenn das von einem Admin-Knoten verwendete Verzeichnis voll ist, wird der Admin-Knoten als für neue Prüfmeldungen nicht verfügbar gekennzeichnet, bis das Verzeichnis nicht mehr voll ist. S3-Client-Anfragen sind nicht betroffen. Der XAMS-Alarm (Unreachable Audit Repositories) wird ausgelöst, wenn ein Audit-Repository nicht erreichbar ist. -
Wenn die
/var/local/Wenn das von einem Speicherknoten mit dem ADC-Dienst verwendete Verzeichnis zu 92 % gefüllt ist, wird der Knoten als für die Überwachung von Nachrichten nicht verfügbar gekennzeichnet, bis das Verzeichnis nur noch zu 87 % gefüllt ist. S3-Client-Anfragen an andere Knoten sind nicht betroffen. Der NRLY-Alarm (Available Audit Relays) wird ausgelöst, wenn Audit-Relays nicht erreichbar sind.
Wenn keine verfügbaren Storage-Nodes mit dem ADC-Dienst vorhanden sind, speichern die Storage-Nodes die Überwachungsmeldungen lokal in der /var/local/log/localaudit.logDatei. -
Wenn die
/var/local/Das von einem Speicherknoten verwendete Verzeichnis ist zu 85 % gefüllt. Der Knoten beginnt, S3-Client-Anfragen mit503 Service Unavailable.
Die folgenden Arten von Problemen können dazu führen, dass die Warteschlangen für Überwachungsnachrichten sehr groß werden:
-
Der Ausfall eines Admin-Knotens oder Speicherknoten mit dem ADC-Dienst. Wenn einer der Systemknoten ausgefallen ist, werden die übrigen Knoten möglicherweise rückgemeldet.
-
Eine nachhaltige Aktivitätsrate, die die Audit-Kapazität des Systems übersteigt.
-
Der
/var/local/Speicherplatz auf einem ADC-Speicherknoten wird aus Gründen voll, die nicht mit Überwachungsmeldungen in Verbindung stehen. In diesem Fall hört der Knoten auf, neue Überwachungsmeldungen zu akzeptieren und priorisiert seinen aktuellen Rückstand, was zu Backlogs auf anderen Knoten führen kann.
Großer Alarm für Überwachungswarteschlangen und Überwachungsmeldungen in Queued (AMQS)
Um Ihnen dabei zu helfen, die Größe der Überwachungsmeldungswarteschlangen im Laufe der Zeit zu überwachen, werden die Warnung große Prüfwarteschlange und der ältere AMQS-Alarm ausgelöst, wenn die Anzahl der Nachrichten in einer Speicherknotenwarteschlange oder Admin-Knoten-Warteschlange bestimmte Schwellenwerte erreicht.
Wenn der Alarm * Large Audit queue* oder der alte AMQS-Alarm ausgelöst wird, prüfen Sie zunächst die Auslastung des Systems – wenn eine beträchtliche Anzahl aktueller Transaktionen vorliegt, sollten sich die Warnung und der Alarm im Laufe der Zeit lösen und können ignoriert werden.
Wenn die Warnung oder der Alarm weiterhin besteht und an Schwere zunimmt, sehen Sie sich ein Diagramm der Warteschlangengröße an. Wenn die Zahl über Stunden oder Tage hinweg stetig ansteigt, hat die Prüflast wahrscheinlich die Prüfkapazität des Systems überschritten. Reduzieren Sie die Client-Betriebsrate oder verringern Sie die Anzahl der protokollierten Prüfmeldungen, indem Sie die Prüfstufe für Client-Schreibvorgänge und Client-Lesevorgänge auf „Fehler“ oder „Aus“ ändern. Sehen "Konfigurieren Sie die Protokollverwaltung und den externen Syslog-Server" .
Duplizieren von Nachrichten
Bei einem Netzwerk- oder Node-Ausfall ist das StorageGRID System konservativ. Aus diesem Grund können doppelte Nachrichten im Audit-Protokoll vorhanden sein.