

Analizar un evento de rendimiento dinámico en un clúster en una configuración de MetroCluster
 Sugerir cambios
Sugerir cambios
Puede utilizar Unified Manager para analizar el clúster en una configuración de MetroCluster en la que se detectó un evento de rendimiento. Puede identificar el nombre del clúster, la hora de detección del evento y las cargas de trabajo implicadas en intimid y Victim.
Lo que necesitará
-
Debe tener el rol de operador, administrador de aplicaciones o administrador de almacenamiento.
-
Debe haber eventos de rendimiento nuevos, reconocidos o obsoletos para una configuración de MetroCluster.
-
Los dos clústeres de la configuración de MetroCluster deben supervisarse con la misma instancia de Unified Manager.
-
Abra la página Detalles del evento para ver información sobre el evento.
-
Revise la descripción del evento para ver los nombres de las cargas de trabajo involucradas y el número de cargas de trabajo involucradas.
En este ejemplo, el icono Recursos de MetroCluster es de color rojo, lo que indica que los recursos de MetroCluster están en disputa. Coloque el cursor sobre el icono para mostrar una descripción del icono.

-
Anote el nombre del clúster y la hora de detección del evento que puede utilizar para analizar los eventos de rendimiento en el clúster de partners.
-
En los gráficos, revise las cargas de trabajo Victim para confirmar que sus tiempos de respuesta son superiores al umbral de rendimiento.
En este ejemplo, la carga de trabajo de la víctima se muestra en el texto de desplazamiento. Los gráficos de latencia muestran, a alto nivel, un patrón de latencia constante para las cargas de trabajo víctimas involucradas. Aunque la latencia anormal de las cargas de trabajo víctimas haya activado el evento, un patrón de latencia consistente podría indicar que las cargas de trabajo están funcionando dentro de su rango esperado, pero que un pico en la I/o aumentó la latencia y activó el evento.
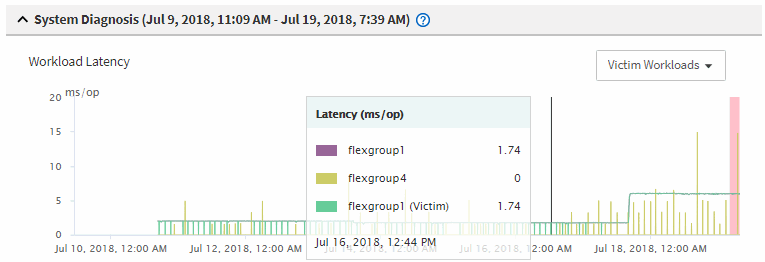
Si instaló recientemente una aplicación en un cliente que accede a estas cargas de trabajo de volumen y esa aplicación envía una gran cantidad de I/o, es posible que anticipe que aumentan las latencias. Si la latencia de las cargas de trabajo se devuelve dentro del rango esperado, el estado del evento cambia a obsoleto y permanece en este estado durante más de 30 minutos, es probable que pueda ignorar el evento. Si el evento está en curso y permanece en el estado nuevo, puede investigarlo aún más para determinar si otros problemas causaron el evento.
-
En el gráfico de rendimiento de cargas de trabajo, seleccione Bully Workloads para mostrar las cargas de trabajo abusivas.
La presencia de cargas de trabajo abusivas indica que el evento podría haber sido causado por una o más cargas de trabajo en el clúster local haciendo un uso excesivo de los recursos de MetroCluster. Las cargas de trabajo abusivas tienen una alta desviación en rendimiento de escritura (MB/s).
En este gráfico, se muestra el patrón de rendimiento de escritura (MB/s) de las cargas de trabajo en el nivel superior. Es posible revisar el patrón de escritura MB/s para identificar un rendimiento anormal, que puede indicar que una carga de trabajo está haciendo un uso excesivo de los recursos de MetroCluster.
Si en este evento no hay cargas de trabajo matones, es posible que el evento haya estado causado por un problema de estado con el enlace entre los clústeres o un problema de rendimiento en el clúster de partners. Puede usar Unified Manager para comprobar el estado de ambos clústeres en una configuración de MetroCluster. También puede utilizar Unified Manager para comprobar y analizar eventos de rendimiento en el clúster de partners.