

Análisis y notificación de eventos de rendimiento
 Sugerir cambios
Sugerir cambios
Los eventos de rendimiento le notifican problemas de rendimiento de I/o en una carga de trabajo provocada por la contención en un componente de clúster. Unified Manager analiza el evento para identificar todas las cargas de trabajo involucradas, el componente en disputa y si el evento sigue siendo un problema que podría necesitar resolver.
Unified Manager supervisa la latencia de I/o (tiempo de respuesta) y las IOPS (operaciones) para volúmenes en un clúster. Cuando otras cargas de trabajo realizan un uso excesivo de un componente del clúster, por ejemplo, el componente es objeto de disputa y no puede funcionar en un nivel óptimo para satisfacer las demandas de las cargas de trabajo. El rendimiento de otras cargas de trabajo que utilizan el mismo componente puede verse afectado, lo que provoca el aumento de las latencias. Si la latencia supera el umbral de rendimiento dinámico, Unified Manager activa un evento de rendimiento para notificarle.
Análisis de eventos
Unified Manager realiza los siguientes análisis utilizando los 15 días anteriores de estadísticas de rendimiento para identificar las cargas de trabajo víctimas, las cargas de trabajo abusivas y el componente del clúster implicados en un evento:
-
Identifica las cargas de trabajo víctimas cuya latencia ha superado el umbral de rendimiento dinámico, que es el límite superior de la previsión de latencia:
-
Para los volúmenes en agregados de HDD o Flash Pool (híbrido) (nivel local), los eventos solo se activan cuando la latencia es superior a 5 milisegundos (ms) y las IOPS son superiores a 10 operaciones por segundo (OPS/s).
-
Para volúmenes en agregados íntegramente de SSD o agregados de FabricPool (nivel de cloud), los eventos solo se activan cuando la latencia es superior a 1 ms y el IOPS supera las 100 OPS/s.
-
-
Identifica el componente del clúster en disputa.

Si la latencia de las cargas de trabajo víctimas en la interconexión del clúster es superior a 1 ms, Unified Manager lo considera importante y activa un evento para la interconexión del clúster.
-
Identifica las cargas de trabajo abusivas que están sobreutilizando el componente del clúster y que hacen que estén en contención.
-
Clasifica las cargas de trabajo involucradas, en función de su desviación en utilización o actividad de un componente del clúster, para determinar qué elementos agresores tienen el mayor cambio de uso del componente del clúster y qué víctimas son las más afectadas.
Es posible que se produzca un evento solo durante un breve momento y, a continuación, corregirlo después de que el componente que está utilizando ya no sea objeto de disputa. Un evento continuo es un evento que se vuelve a producir para el mismo componente del clúster en un intervalo de cinco minutos y permanece en el estado activo. En el caso de eventos continuos, Unified Manager activa una alerta tras detectar el mismo evento en dos intervalos de análisis consecutivos.
Cuando se resuelve un evento, este sigue disponible en Unified Manager como parte del registro de problemas de rendimiento anteriores de un volumen. Cada evento tiene un ID único que identifica el tipo de evento y los componentes de volúmenes, clúster y clúster implicados.
|
|
Un único volumen puede participar en más de un evento a la vez. |
Estado del evento
Los eventos pueden estar en uno de los siguientes estados:
-
Activo
Indica que el evento de rendimiento está activo (nuevo o reconocido). El problema que causa el evento no se ha corregido solo o no se ha resuelto. El contador de rendimiento del objeto de almacenamiento sigue por encima del umbral de rendimiento.
-
Obsoleto
Indica que el evento no está activo. El problema que causa el evento se ha corregido solo o se ha resuelto. El contador de rendimiento del objeto de almacenamiento ya no está por encima del umbral de rendimiento.
Notificación de eventos
Los eventos se muestran en la página Dashboard y en muchas otras páginas de la interfaz de usuario, y las alertas de esos eventos se envían a direcciones de correo electrónico especificadas. Puede ver información detallada sobre un evento y obtener sugerencias para resolverlo en la página de detalles Event y en la página Workload Analysis.
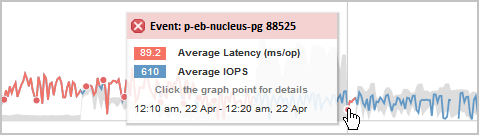
En este ejemplo, un evento se indica mediante un punto rojo (![]() ) En el gráfico latencia. Al pasar el cursor del ratón por encima del punto rojo, se muestra una ventana emergente con más detalles sobre el evento y las opciones para analizarlo.
) En el gráfico latencia. Al pasar el cursor del ratón por encima del punto rojo, se muestra una ventana emergente con más detalles sobre el evento y las opciones para analizarlo.
Interacción de eventos
En la página de detalles Event y en la página Workload Analysis, puede interactuar con los eventos de las siguientes maneras:
-
Al mover el ratón sobre un evento se muestra un mensaje que muestra el identificador del evento y la fecha y hora en que se detectó el evento.
Si hay varios eventos para el mismo período de tiempo, el mensaje muestra el número de eventos.
-
Al hacer clic en un solo evento se muestra un cuadro de diálogo que muestra información más detallada sobre el evento, incluidos los componentes del clúster implicados.
El componente objeto de la contención está en un círculo y se resalta en rojo. Puede hacer clic en el ID del evento o en Ver análisis completo para ver el análisis completo en la página de detalles del evento. Si hay varios eventos para el mismo período de tiempo, el cuadro de diálogo muestra detalles acerca de los tres eventos más recientes. Puede hacer clic en un ID de evento para ver el análisis de eventos en la página de detalles Event.