

Crear un plan de replicación en NetApp Disaster Recovery
 Sugerir cambios
Sugerir cambios
Una vez que hayas añadido recursos y sitios, crea un plan de replicación para gestionar la protección de datos. Crear el plan de replicación implica designar los sitios de origen y destino, seleccionar los grupos de recursos y elegir cómo deben restaurarse y encenderse las aplicaciones. Por ejemplo, podrías agrupar máquinas virtuales (VMs) asociadas con una aplicación o podrías agrupar aplicaciones que tengan niveles similares.
Al crear un plan de replicación, también puedes modificar las programaciones para el cumplimiento y las pruebas, realizando conmutaciones de prueba sin afectar tus datos de producción.
Función de NetApp Console requerida Para realizar esta tarea se requiere la función Super admin, Disaster recovery admin, Disaster recovery failover admin o Disaster recovery application admin. "Obtenga información sobre los roles y permisos de usuario en NetApp Disaster Recovery". "Obtenga información sobre los roles de acceso a la NetApp Console para todos los servicios".
Acerca de los planes de replicación
Puede proteger varias máquinas virtuales en varios almacenes de datos. NetApp Disaster Recovery crea grupos de consistencia ONTAP para todos los volúmenes ONTAP que alojan almacenes de datos de máquinas virtuales protegidos.
Sólo puedes activar la protección si el plan de replicación se encuentra en uno de los siguientes estados:
-
Listo
-
Conmutación por recuperación comprometida
-
Prueba de conmutación por error confirmada
Instantáneas del plan de replicación
La recuperación ante desastres mantiene la misma cantidad de instantáneas en los clústeres de origen y destino. De forma predeterminada, el servicio realiza un proceso de conciliación de instantáneas cada 24 horas para garantizar que la cantidad de instantáneas en los clústeres de origen y destino sea la misma.
Las siguientes situaciones pueden provocar que la cantidad de instantáneas varíe entre los clústeres de origen y destino:
-
Algunas situaciones pueden provocar que las operaciones de ONTAP fuera de la recuperación ante desastres agreguen o eliminen instantáneas del volumen:
-
Si faltan instantáneas en el sitio de origen, es posible que se eliminen las instantáneas correspondientes en el sitio de destino, según la política de SnapMirror predeterminada para la relación.
-
Si faltan instantáneas en el sitio de destino, el servicio podría eliminar las instantáneas correspondientes en el sitio de origen durante el próximo proceso de conciliación de instantáneas programado, según la política SnapMirror predeterminada para la relación.
-
-
Una reducción en el recuento de retención de instantáneas del plan de replicación puede provocar que el servicio elimine las instantáneas más antiguas tanto en el sitio de origen como en el de destino para cumplir con el número de retención recientemente reducido.
En estos casos, Disaster Recovery elimina instantáneas más antiguas de los clústeres de origen y destino en la siguiente verificación de consistencia. O bien, el administrador puede realizar una limpieza de instantáneas inmediata seleccionando Acciones*![]() icono en el plan de replicación y seleccionando *Limpiar instantáneas.
icono en el plan de replicación y seleccionando *Limpiar instantáneas.
Disaster Recovery realiza comprobaciones de simetría de instantáneas cada 24 horas.
Antes de empezar
-
Antes de crear una relación SnapMirror , configure el clúster y el emparejamiento SVM fuera de Disaster Recovery.
-
Si configuras las asignaciones de red a nivel de vCenter, Disaster Recovery reconoce esas asignaciones cuando creas el plan de replicación. Si modificas o agregas la asignación de red a nivel de vCenter después de crear el plan de replicación, Disaster Recovery reconoce esas asignaciones cuando editas manualmente el plan de replicación.
-
Con Google Cloud, solo puedes agregar un volumen o almacén de datos a un plan de replicación.

|
Organiza tus máquinas virtuales o clústeres de Kubernetes antes de implementar NetApp Disaster Recovery para minimizar la dispersión. Coloca los recursos que necesitan protección en un subconjunto de almacenes de datos y los recursos que no se van a proteger en un subconjunto diferente de almacenes de datos. Para organizar grupos de recursos antes de crear el plan de replicación, consulta "Crear un grupo de recursos". |
Crear el plan de replicación
Un asistente le guiará a través de estos pasos:
-
Seleccione servidores vCenter.
-
Selecciona los recursos (VMs, datastore, namespaces) que quieres replicar y asigna grupos de recursos.
-
Mapee cómo los recursos del entorno de origen se asignan al destino.
-
Establezca la frecuencia con la que se ejecuta el plan, ejecute un script alojado por el invitado, establezca el orden de arranque y seleccione el objetivo del punto de recuperación.
-
Revisar el plan.
Cuando crees el plan, sigue estas pautas:
-
Usa las mismas credenciales para todas las máquinas virtuales o clústeres Kubernetes del plan.
-
Usa el mismo script para todas las máquinas virtuales o clústeres de Kubernetes en el plan.
-
Usa la misma subred, DNS y puerta de enlace para todas las máquinas virtuales o clústeres de Kubernetes en el plan.
Seleccionar servidores vCenter
Primero, seleccione el vCenter de origen y luego seleccione el vCenter de destino.
-
Desde el panel de navegación izquierdo de la NetApp Console , seleccione Protección > Recuperación ante desastres.
-
En el menú NetApp Disaster Recovery , seleccione Planes de replicación.
-
En el menú desplegable, elige el tipo de recurso para el que quieres crear el plan de replicación: Kubernetes o vCenter.
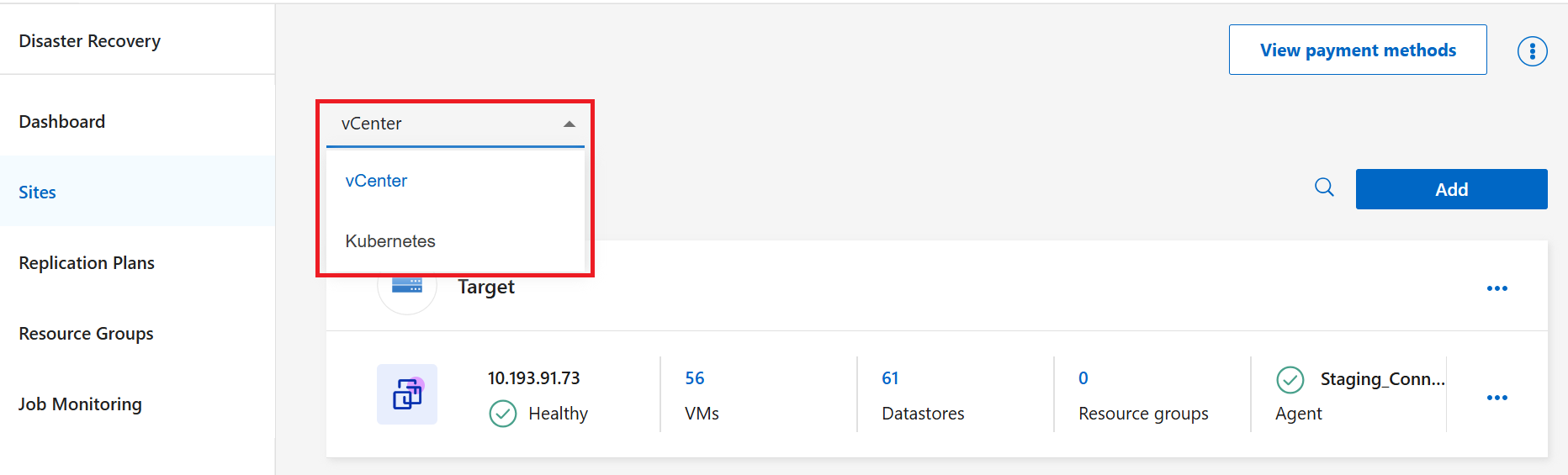
-
Seleccione Agregar.
-
Ingresa un nombre para el plan de replicación.
-
Para Source, selecciona el clúster vCenter o Kubernetes que quieres designar como origen.
-
En Source vCenter, selecciona el vCenter donde existen los datos en el menú desplegable. En Target, selecciona el vCenter o clúster de Kubernetes que quieres usar como clúster de destino para la recuperación de desastres.
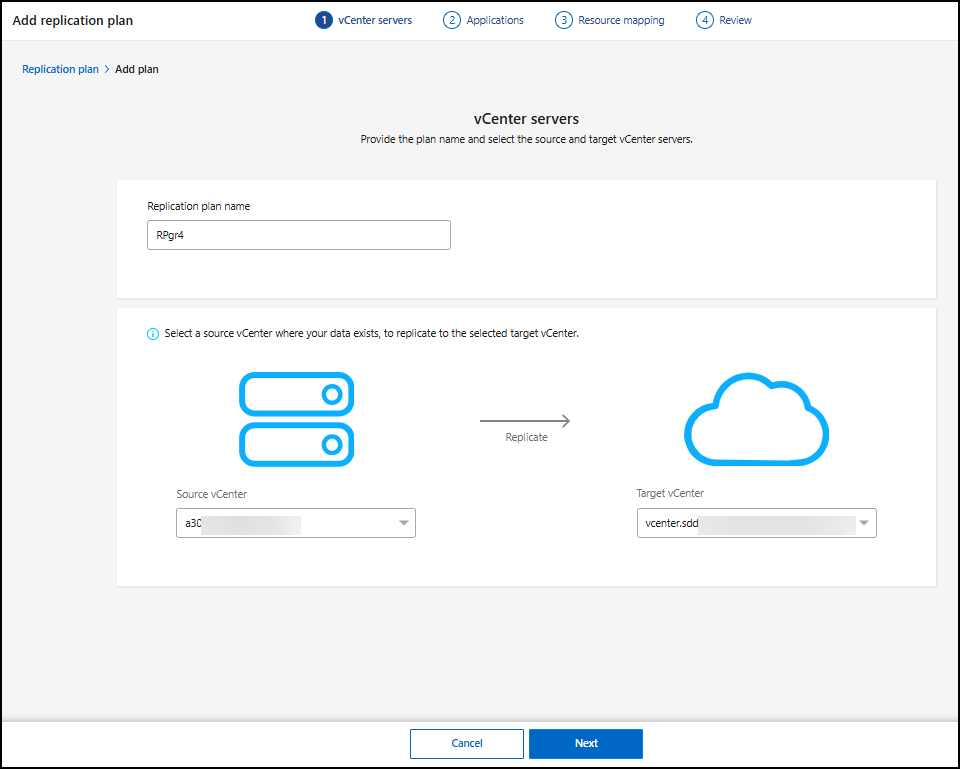
-
Seleccione Siguiente.
Seleccionar aplicaciones para replicar y asignar grupos de recursos
El siguiente paso consiste en agrupar las máquinas virtuales, los almacenes de datos o los clústeres de Kubernetes necesarios en grupos de recursos funcionales. Los grupos de recursos te permiten proteger un conjunto de recursos, como un clúster de Kubernetes o una máquina virtual, con una instantánea común.
Al crear grupos de recursos, tenga en cuenta las siguientes cuestiones:
-
Antes de añadir recursos a los grupos de recursos, inicia primero una detección manual o una detección programada. Esto garantiza que los recursos se descubran y aparezcan en el grupo de recursos.
-
Asegúrate de que hay al menos una máquina virtual en el almacén de datos. Si no hay máquinas virtuales en el almacén de datos, el almacén de datos no se detectará.
-
Un único almacén de datos no debe alojar máquinas virtuales protegidas por más de un plan de replicación.
-
No alojes recursos protegidos y no protegidos en el mismo almacén de datos. Si los recursos protegidos y no protegidos se alojan en el mismo almacén de datos, puedes encontrarte con estos problemas:
-
La capacidad utilizada de ese volumen puede contribuir al cálculo de licencias porque Disaster Recovery utiliza SnapMirror, lo que significa que el sistema replica volúmenes ONTAP completos. En este caso, el espacio de volumen consumido tanto por los recursos protegidos como por los no protegidos se incluiría en este cálculo.
-
Si el grupo de recursos y sus recursos asociados deben transferirse por error al sitio de recuperación ante desastres, los recursos desprotegidos dejarán de existir en el sitio de origen desde el proceso de conmutación por error, lo que provocará el fallo de los recursos desprotegidos en el sitio de origen. Además, NetApp Disaster Recovery no iniciará esos recursos desprotegidos en el sitio de conmutación por error.
-
|
|
Crea un conjunto separado de asignaciones dedicadas para tus pruebas de conmutación por error para evitar que los recursos se conecten a las redes de producción usando las mismas direcciones IP. |
-
Si ya tienes grupos de recursos, selecciona Resource groups, elige el grupo de recursos y luego Next.
Si no tienes grupos de recursos existentes o necesitas añadir recursos a uno, selecciona Virtual machines o Datastores.
-
Selecciona las máquinas virtuales o los datastores que quieres añadir al plan de replicación desde la lista generada automáticamente. Para las máquinas virtuales, puedes filtrar por el datastore. Cuando seleccionas un datastore o una máquina virtual, se añade automáticamente a un grupo de recursos.
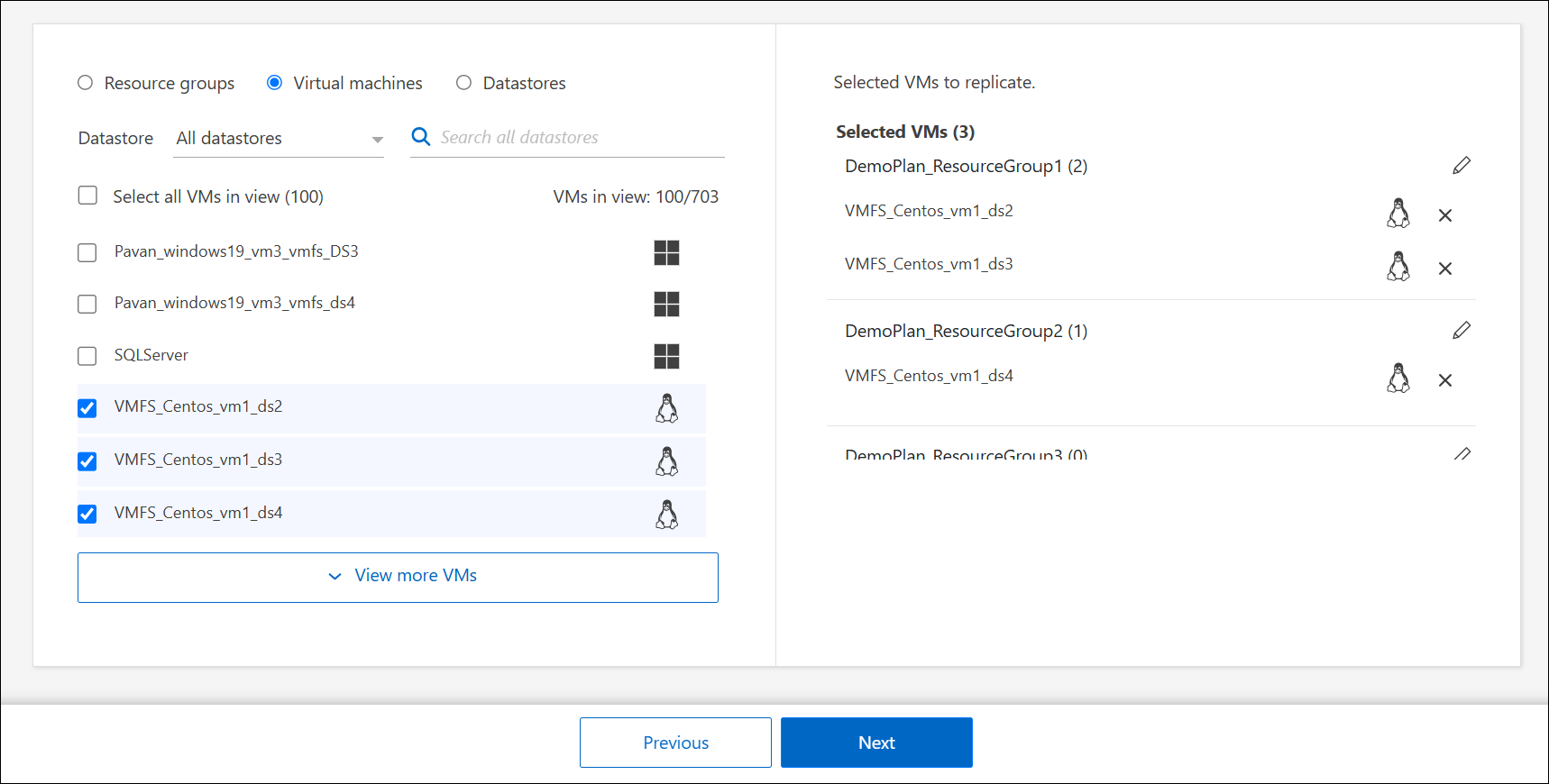
-
En la mitad derecha de la página, revisa las máquinas virtuales o los almacenes de datos seleccionados.
-
Para eliminar una máquina virtual o un almacén de datos, pasa el ratón sobre el nombre de la fuente de datos y selecciona X.
-
Para organizar los recursos en varios grupos de recursos, selecciona Haz clic para añadir otro grupo de recursos. Después de que hayas añadido el grupo de recursos, puedes arrastrar y soltar recursos entre grupos. Selecciona el icono del lápiz* para editar el nombre del grupo de recursos.
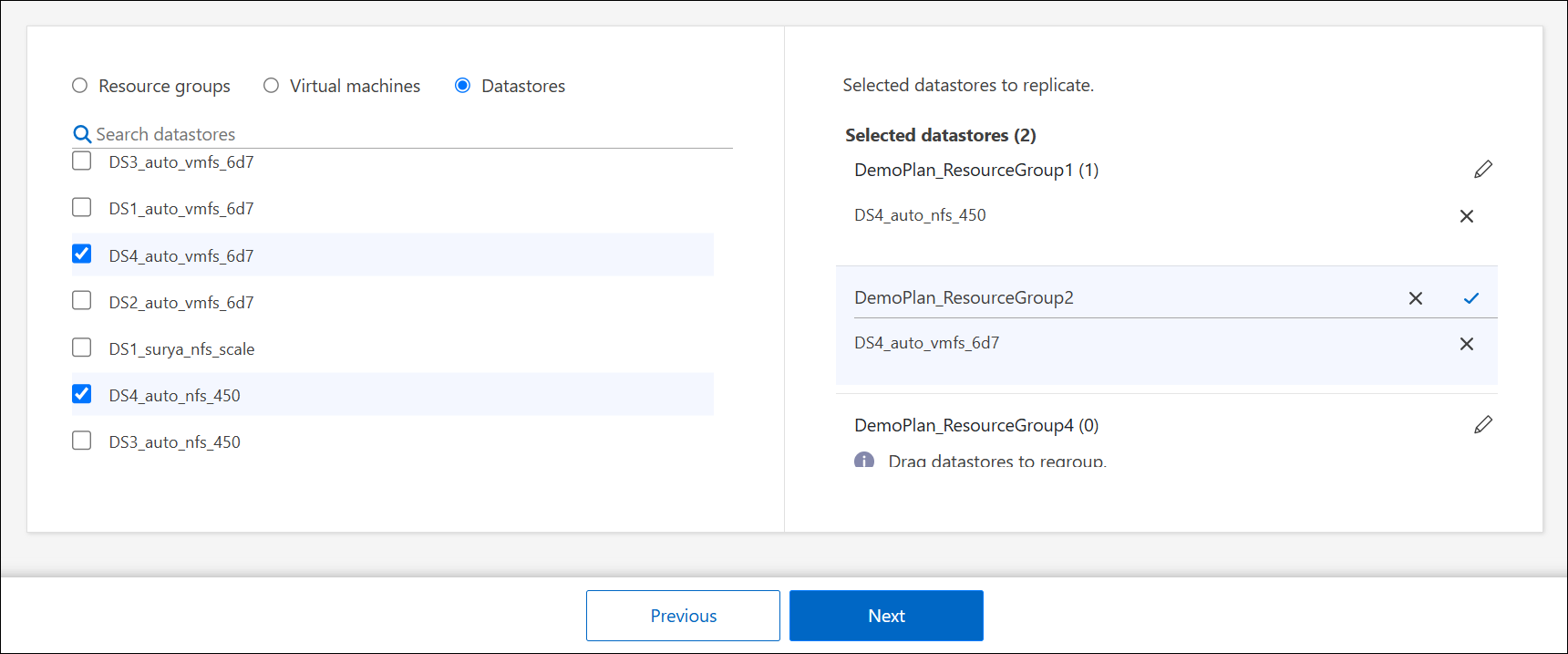
-
-
Seleccione Siguiente.
Al crear un plan de replicación para clústeres de Kubernetes, los espacios de nombres de Kubernetes de un grupo de recursos deben pertenecer al mismo clúster de ONTAP.
-
Si tienes grupos de recursos existentes, elige los grupos de la lista.
Si no tienes grupos de recursos existentes o necesitas añadir recursos a uno, selecciona + Crear nuevo grupo de recursos. Sigue las instrucciones para "agrega espacios de nombres a un grupo de recursos".
Cuando se nombra un grupo de recursos, los únicos caracteres admitidos son letras minúsculas y números.
-
En la columna alternativa, revisa los grupos de recursos seleccionados.
-
Selecciona Siguiente.
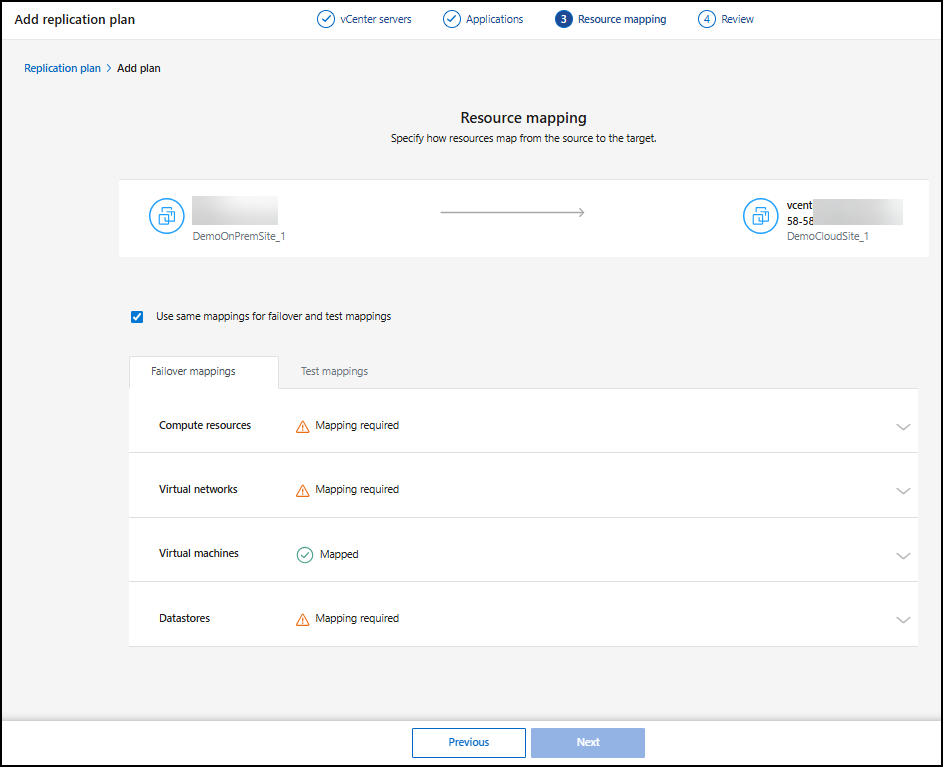
Asignar recursos de origen al destino
En el paso de mapeo de recursos, especifique cómo deben mapearse los recursos del entorno de origen al destino. Al crear un plan de replicación, puede establecer un retraso y un orden de arranque para cada máquina virtual en el plan. Esto le permite establecer una secuencia para que se inicien las máquinas virtuales.
Si planea realizar conmutaciones por error de prueba como parte de su plan de recuperación ante desastres, debe proporcionar un conjunto de asignaciones de conmutación por error de prueba para garantizar que las máquinas virtuales iniciadas durante la prueba de conmutación por error no interfieran con las máquinas virtuales de producción. Puede lograr esto proporcionando a las máquinas virtuales de prueba direcciones IP diferentes o asignando las NIC virtuales de las máquinas virtuales de prueba a una red diferente que esté aislada de la producción pero que tenga la misma configuración IP (conocida como burbuja o red de prueba).
Si desea crear una relación SnapMirror en este servicio, el clúster y su emparejamiento SVM ya deben haberse configurado fuera de NetApp Disaster Recovery.
-
En la página de mapeo de recursos, marque la casilla para usar las mismas asignaciones para las operaciones de prueba y conmutación por error.
-
En la pestaña Asignaciones de conmutación por error, seleccione la flecha hacia abajo a la derecha de cada recurso y asigne los recursos en cada sección:
-
Recursos computacionales
-
Redes virtuales
-
Máquinas virtuales
-
Almacenes de datos
-
-
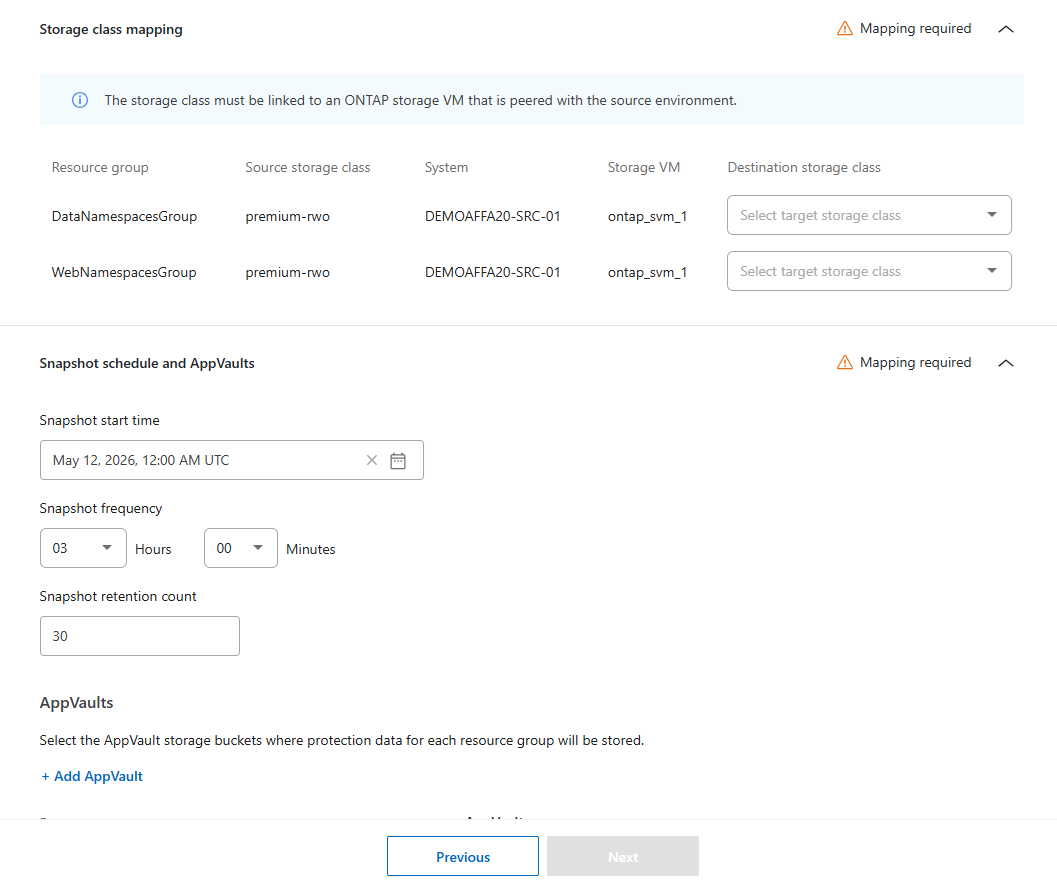
Elige las asignaciones de espacios de nombres para cada espacio de nombres en cada grupo de recursos. Por defecto, Disaster Recovery selecciona que el destino sea el mismo que el origen. Puedes elegir un espacio de nombres diferente en el clúster de destino.
-
Designa el mapeo de la clase de almacenamiento para cada grupo de recursos. La clase de almacenamiento debe estar vinculada a una VM de almacenamiento ONTAP peered con el entorno de origen. Se utiliza la clase de almacenamiento predeterminada en el clúster si no designas una.
Ejecuta el comando CLI kubectl get pvc -n <namespace>en el espacio de nombres para ver la clase de almacenamiento. -
Configura la programación de snapshots:
Elige la Hora de inicio de instantáneas y retención (fecha y hora del calendario), la Frecuencia de instantáneas y retención (con qué frecuencia se inician las instantáneas) y el Conteo de retención de instantáneas (cuántas instantáneas se guardan).
Al establecer la frecuencia de las instantáneas, el mínimo permitido es de cinco minutos.
-
Selecciona Add AppVault para crear el AppVault donde se guardarán los datos de protección.
-
Introduce un Nombre y selecciona el Console agent al que debe conectarse AppVault.
-
Selecciona el Proveedor de la nube para alojar el AppVault.
-
Basándose en la selección del proveedor, Disaster Recovery rellena las suscripciones configuradas existentes en la nube. Elige la Suscripción, el Grupo de recursos y la Cuenta de almacenamiento para el proveedor de la nube.
-
Selecciona Añadir.
-
-
Selecciona Siguiente.
-
Revisa las asignaciones de conmutación por error y selecciona Add para crear el plan de replicación.
Después de seleccionar Add, puedes supervisar los diferentes trabajos en Job monitoring.

|
Para Kubernetes, este es el paso final para crear una replicación. Para vCenters, continúa en Sección de recursos de compute. |
Sección de recursos de compute
La sección Recursos de cómputo define dónde se restaurarán las máquinas virtuales después de una conmutación por error. Asigne el centro de datos y el clúster de vCenter de origen a un centro de datos y un clúster de destino.
Opcionalmente, las máquinas virtuales se pueden reiniciar en un host vCenter ESXi específico. Si VMWare DRS está habilitado, puede mover la VM a un host alternativo automáticamente si es necesario para cumplir con la política de DR configurada.
Opcionalmente, puede colocar todas las máquinas virtuales en este plan de replicación en una carpeta única con vCenter. Esto proporciona una forma sencilla de organizar rápidamente las máquinas virtuales conmutadas por error dentro del vCenter.
Seleccione la flecha hacia abajo junto a Recursos informáticos.
-
Centros de datos de origen y destino
-
Clúster objetivo
-
Host de destino (opcional): después de seleccionar el clúster, puede configurar esta información.
-
Carpeta (opcional)
|
|
Si un vCenter tiene un Programador de recursos distribuidos (DRS) configurado para administrar varios hosts en un clúster, no es necesario seleccionar un host. Si selecciona un host, NetApp Disaster Recovery colocará todas las máquinas virtuales en el host seleccionado. * Carpeta de máquina virtual de destino (opcional): crea una nueva carpeta raíz para almacenar las máquinas virtuales seleccionadas. |
Redes virtuales
Las máquinas virtuales usan NIC virtuales conectadas a redes virtuales. En el proceso de conmutación por error, el servicio conecta estas NIC virtuales a redes virtuales definidas en el entorno VMware de destino. Para cada red virtual de origen usada por las máquinas virtuales en el grupo de recursos, el servicio requiere una asignación de red virtual de destino.
|
|
Esta sección sólo es necesaria para vCenters. No es necesario completarla para Kubernetes. |
|
|
Puede asignar varias redes virtuales de origen a la misma red virtual de destino. Sin embargo, esto podría crear conflictos de configuración de red IP. Puede asignar varias redes de origen a una única red de destino para garantizar que todas las redes de origen tengan la misma configuración. |
En la pestaña Mapeos de conmutación por error, seleccione la flecha hacia abajo junto a Redes virtuales. Seleccione la LAN virtual de origen y la LAN virtual de destino.
Seleccione la asignación de red a la LAN virtual adecuada. Las LAN virtuales ya deberían estar aprovisionadas, así que seleccione la LAN virtual adecuada para mapear la VM.
Máquinas virtuales
Puede configurar cada máquina virtual en el grupo de recursos protegido por el plan de replicación para que se adapte al entorno virtual de vCenter de destino configurando cualquiera de las siguientes opciones:
-
El número de CPU virtuales
-
La cantidad de DRAM virtual
-
La configuración de la dirección IP
-
La capacidad de ejecutar scripts de shell del sistema operativo invitado como parte del proceso de conmutación por error
-
La capacidad de cambiar los nombres de las máquinas virtuales conmutadas por error mediante un prefijo y un sufijo únicos
-
La capacidad de establecer el orden de reinicio durante la conmutación por error de la máquina virtual
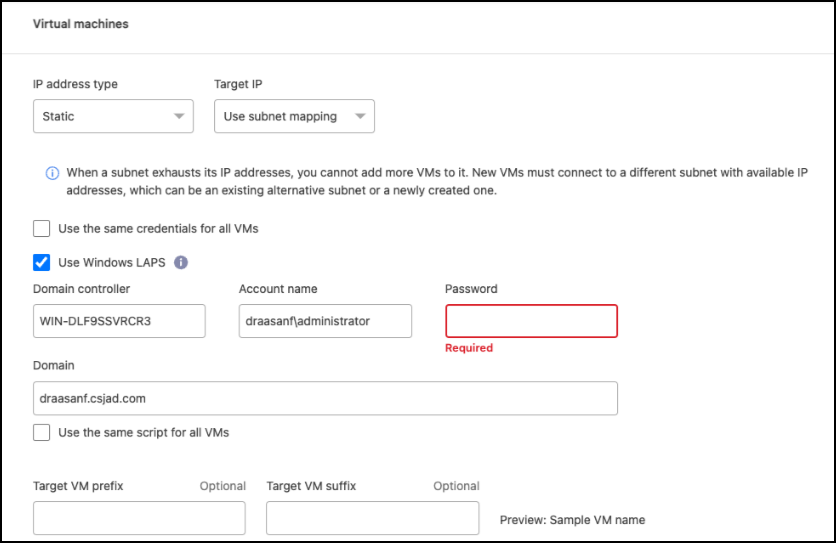
En la pestaña Mapeos de conmutación por error, seleccione la flecha hacia abajo junto a Máquinas virtuales.
El valor predeterminado para las máquinas virtuales está asignado. La asignación predeterminada utiliza las mismas configuraciones que usan las máquinas virtuales en el entorno de producción (misma dirección IP, máscara de subred y puerta de enlace).
Si realiza algún cambio en la configuración predeterminada, deberá cambiar el campo IP de destino a "Diferente de la fuente".
|
|
Si cambia la configuración a "Diferente de la fuente", deberá proporcionar las credenciales del sistema operativo invitado de la máquina virtual. |
Esta sección puede mostrar diferentes campos dependiendo de su selección.
Puede aumentar o disminuir la cantidad de CPU virtuales asignadas a cada máquina virtual conmutada por error. Sin embargo, cada VM requiere al menos una CPU virtual. Puede cambiar la cantidad de CPU virtuales y DRAM virtuales asignadas a cada VM. El motivo más común por el que podría querer cambiar la configuración predeterminada de CPU virtual y DRAM virtual es si los nodos del clúster vCenter de destino no tienen tantos recursos disponibles como el clúster vCenter de origen.
|
|
Activa la configuración avanzada para añadir los ajustes Scripts y consistente con las aplicaciones. |
Configuración de red Disaster Recovery admite un amplio conjunto de opciones de configuración para redes de máquinas virtuales. Puede que sea necesario cambiarlas si el sitio de destino tiene redes virtuales que utilizan una configuración TCP/IP diferente a la de las redes virtuales de producción del sitio de origen.
En el nivel más básico (y predeterminado), la configuración simplemente utiliza la misma configuración de red TCP/IP para cada VM en el sitio de destino que la utilizada en el sitio de origen. Esto requiere que configure los mismos ajustes TCP/IP en las redes virtuales de origen y destino.
El servicio admite configuraciones de red de IP estática o de protocolo de configuración dinámica de host (DHCP) para máquinas virtuales. DHCP proporciona un método basado en estándares para configurar dinámicamente los parámetros TCP/IP de un puerto de red host. DHCP debe proporcionar, como mínimo, una dirección TCP/IP y también puede proporcionar una dirección de puerta de enlace predeterminada (para enrutar a una conexión a Internet externa), una máscara de subred y una dirección de servidor DNS. El DHCP se utiliza comúnmente para dispositivos informáticos de usuarios finales, como computadoras de escritorio, portátiles y conexiones de teléfonos móviles de empleados, aunque también se puede utilizar para cualquier dispositivo informático de red, como servidores.
-
Opción Usar la misma máscara de subred, DNS y configuración de puerta de enlace: debido a que estas configuraciones suelen ser las mismas para todas las máquinas virtuales conectadas a las mismas redes virtuales, es posible que le resulte más fácil configurarlas una vez y dejar que Disaster Recovery use las configuraciones para todas las máquinas virtuales en el grupo de recursos protegido por el plan de replicación. Si algunas máquinas virtuales usan configuraciones diferentes, deberá desmarcar esta casilla y proporcionar esas configuraciones para cada máquina virtual.
-
Tipo de dirección IP: reconfigura la configuración de las máquinas virtuales para que coincida con los requisitos de la red virtual de destino. NetApp Disaster Recovery ofrece dos opciones: DHCP o IP estática. Para direcciones IP estáticas, configure la máscara de subred, la puerta de enlace y los servidores DNS. Además, ingrese las credenciales para las máquinas virtuales.
-
DHCP: seleccione esta configuración si desea que sus máquinas virtuales obtengan información de configuración de red de un servidor DHCP. Si elige esta opción, proporcionará únicamente las credenciales para la máquina virtual.
-
IP estática: seleccione esta configuración si desea especificar la información de configuración de IP manualmente. Puede seleccionar una de las siguientes opciones: igual que la fuente, diferente de la fuente o asignación de subred. Si elige lo mismo que la fuente, no necesita ingresar credenciales. Por otro lado, si elige utilizar información diferente de la fuente, puede proporcionar las credenciales, la dirección IP de la VM, la máscara de subred, el DNS y la información de la puerta de enlace. Las credenciales del sistema operativo invitado de la máquina virtual se deben proporcionar al nivel global o a cada nivel de la máquina virtual.
Esto puede ser muy útil al recuperar entornos grandes en clústeres de destino más pequeños o para realizar pruebas de recuperación ante desastres sin tener que aprovisionar una infraestructura VMware física uno a uno.
-
-
Scripts: puede incluir scripts personalizados alojados en el sistema operativo invitado en formato .sh, .bat o .ps1 como procesos posteriores. Con scripts personalizados, Disaster Recovery puede ejecutar su script después de una conmutación por error, una recuperación y procesos de migración. Por ejemplo, puede utilizar un script personalizado para reanudar todas las transacciones de la base de datos una vez completada la conmutación por error. El servicio puede ejecutar scripts dentro de máquinas virtuales que ejecutan Microsoft Windows o cualquier variante de Linux compatible con parámetros de línea de comandos admitidos. Puede asignar un script a máquinas virtuales individuales o a todas las máquinas virtuales en el plan de replicación.
Para habilitar la ejecución de scripts con el SO invitado VM, deben cumplirse las siguientes condiciones:
-
VMware Tools debe estar instalado en la máquina virtual.
-
Se deben proporcionar credenciales de usuario apropiadas con privilegios de sistema operativo invitado adecuados para ejecutar el script.
-
Opcionalmente, incluya un valor de tiempo de espera en segundos para el script.
Máquinas virtuales que ejecutan Microsoft Windows: pueden ejecutar scripts por lotes de Windows (.bat) o de PowerShell (ps1). Los scripts de Windows pueden utilizar argumentos de línea de comandos. Formatear cada argumento en el
arg_name$valueformato, dondearg_namees el nombre del argumento y$valuees el valor del argumento y un punto y coma separa cada unoargument$valuepar.
Máquinas virtuales que ejecutan Linux: pueden ejecutar cualquier script de shell (.sh) compatible con la versión de Linux utilizada por la máquina virtual. Los scripts de Linux pueden utilizar argumentos de línea de comandos. Proporcione argumentos en una lista de valores separados por punto y coma. No se admiten argumentos con nombre. Añade cada argumento a la
Arg[x]lista de argumentos y hacer referencia a cada valor mediante un puntero a laArg[x]matriz, por ejemplo,value1;value2;value3. -
-
Reducir la versión del hardware de la máquina virtual y registrarla: Seleccione esta opción si la versión del host ESX de destino es anterior a la del origen para que coincidan durante el registro.
-
Conservar la jerarquía de carpetas original: de manera predeterminada, Disaster Recovery conserva la jerarquía de inventario de VM (estructura de carpetas) en caso de conmutación por error. Si el destino de recuperación no tiene la jerarquía de carpetas original, Disaster Recovery la crea.
Desmarque esta casilla para ignorar la jerarquía de carpetas original.
-
Prefijo y sufijo de la máquina virtual de destino: en los detalles de las máquinas virtuales, puede agregar opcionalmente un prefijo y un sufijo a cada nombre de máquina virtual conmutada por error. Esto puede resultar útil para diferenciar las máquinas virtuales conmutadas por error de las máquinas virtuales de producción que se ejecutan en el mismo clúster de vCenter. Por ejemplo, puede agregar un prefijo "DR-" y un sufijo "-failover" al nombre de la VM. Algunas personas agregan un segundo vCenter de producción para alojar máquinas virtuales temporalmente en un sitio diferente en caso de desastre. Agregar un prefijo o sufijo puede ayudarle a identificar rápidamente las máquinas virtuales conmutadas por error. También puedes usar el prefijo o sufijo en scripts personalizados.
Puede utilizar el método alternativo para configurar la carpeta de la máquina virtual de destino en la sección Recursos de cómputo.
-
CPU y Memoria (GB): en los detalles de las máquinas virtuales, puedes cambiar opcionalmente el tamaño de la CPU y la memoria.
Puede configurar la DRAM en gigabytes (GiB) o megabytes (MiB). Si bien cada VM requiere al menos un MiB de RAM, la cantidad real debe garantizar que el sistema operativo invitado de la VM y cualquier aplicación en ejecución puedan funcionar de manera eficiente. -
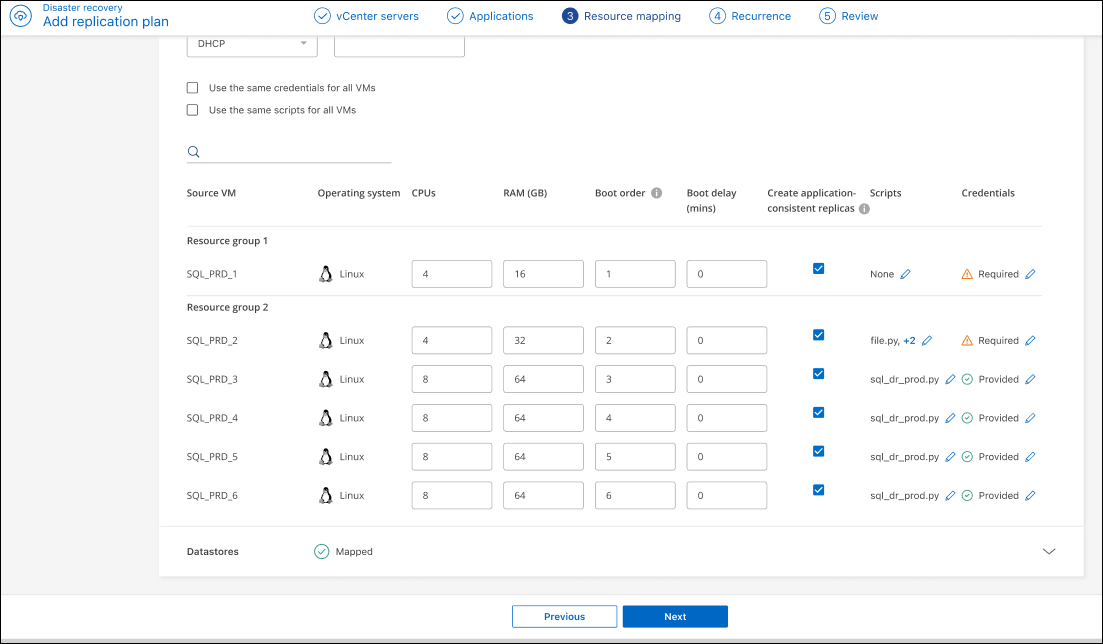
Orden de arranque: puede modificar el orden de arranque después de una conmutación por error para todas las máquinas virtuales seleccionadas en los grupos de recursos. De forma predeterminada, todas las máquinas virtuales arrancan juntas en paralelo; sin embargo, puedes realizar cambios en esta etapa. Esto es útil para garantizar que todas las máquinas virtuales de prioridad uno se estén ejecutando antes de que se inicien las máquinas virtuales de prioridad posterior.
Disaster Recovery inicia cualquier máquina virtual con el mismo número de orden de inicio en paralelo.
-
Arranque secuencial: asigna a cada VM un número único para arrancar en el orden asignado, por ejemplo, 1, 2, 3, 4, 5.
-
Arranque simultáneo: asigne el mismo número a todas las máquinas virtuales para iniciarlas al mismo tiempo, por ejemplo, 1,1,1,1,2,2,3,4,4.
-
-
Retraso de arranque: ajusta el retraso en minutos de la acción de arranque, indicando la cantidad de tiempo que la VM esperará antes de iniciar el proceso de encendido. Introduzca un valor de 0 a 10 minutos.
-
App consistent: Indica si quieres crear copias snapshot consistentes con las aplicaciones. El servicio pondrá en reposo la aplicación y luego tomará una snapshot para obtener un estado consistente de la aplicación. Esta función es compatible con Oracle ejecutándose en Windows y Linux, y con SQL Server ejecutándose en Windows. Mira más detalles a continuación.
Debes activar el interruptor Advance settings para esta opción. Si activas la consistencia con las aplicaciones, debes proporcionar credenciales en forma de nombre de usuario y contraseña.
Crear réplicas consistentes con la aplicación
Muchas máquinas virtuales alojan servidores de bases de datos como Oracle o Microsoft SQL Server. Estos servidores de bases de datos requieren instantáneas consistentes con la aplicación para garantizar que la base de datos esté en un estado consistente cuando se toma la instantánea.
Las instantáneas consistentes con la aplicación garantizan que la base de datos esté en un estado consistente cuando se toma la instantánea. Esto es importante porque garantiza que la base de datos pueda restaurarse a un estado consistente después de una operación de conmutación por error o recuperación.
Los datos administrados por el servidor de base de datos pueden estar alojados en el mismo almacén de datos que la máquina virtual que aloja el servidor de base de datos o pueden estar alojados en un almacén de datos diferente. La siguiente tabla muestra las configuraciones admitidas para instantáneas consistentes con la aplicación en recuperación ante desastres:
| Ubicación de los datos | Apoyado | Notas |
|---|---|---|
Dentro del mismo almacén de datos de vCenter que la máquina virtual |
Sí |
Debido a que el servidor de base de datos y la base de datos residen en el mismo almacén de datos, tanto el servidor como los datos estarán sincronizados en caso de conmutación por error. |
Dentro de un almacén de datos de vCenter diferente al de la máquina virtual |
No |
La recuperación ante desastres no puede identificar cuándo los datos de un servidor de base de datos están en un almacén de datos de vCenter diferente. El servicio no puede replicar los datos, pero puede replicar la máquina virtual del servidor de base de datos. Si bien los datos de la base de datos no se pueden replicar, el servicio garantiza que el servidor de la base de datos realice todos los pasos necesarios para garantizar que la base de datos esté inactiva en el momento de la copia de seguridad de la máquina virtual. |
Dentro de una fuente de datos externa |
No |
Si los datos residen en un LUN o recurso compartido NFS montado por el invitado, Disaster Recovery no puede replicar los datos, pero puede replicar la máquina virtual del servidor de base de datos. Si bien los datos de la base de datos no se pueden replicar, el servicio garantiza que el servidor de la base de datos realice todos los pasos necesarios para garantizar que la base de datos esté inactiva en el momento de la copia de seguridad de la máquina virtual. |
Durante una copia de seguridad programada, Disaster Recovery inactiva el servidor de base de datos y luego toma una instantánea de la máquina virtual que aloja el servidor de base de datos. Esto garantiza que la base de datos esté en un estado consistente cuando se toma la instantánea.
-
Para las máquinas virtuales de Windows, el servicio utiliza el Servicio de instantáneas de volumen (VSS) de Microsoft para coordinarse con cualquiera de los servidores de base de datos.
-
Para las máquinas virtuales Linux, el servicio utiliza un conjunto de scripts para colocar el servidor Oracle en modo de respaldo.
Para habilitar réplicas consistentes con la aplicación de las máquinas virtuales y sus almacenes de datos de alojamiento, marque la casilla junto a Crear réplicas consistentes con la aplicación para cada máquina virtual y proporcione credenciales de inicio de sesión de invitado con los privilegios adecuados.
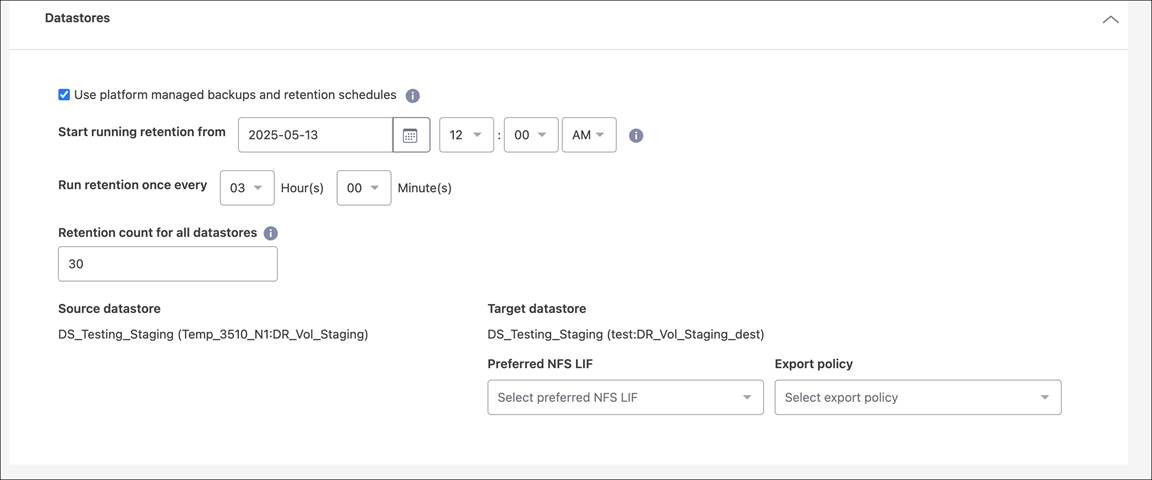
Sección de Datastores
Los almacenes de datos de VMware están alojados en volúmenes ONTAP FlexVol o LUN iSCSI o FC de ONTAP mediante VMware VMFS. Utilice la sección Almacenes de datos para definir el clúster ONTAP de destino, la máquina virtual de almacenamiento (SVM) y el volumen o LUN para replicar los datos del disco al destino.
Seleccione la flecha hacia abajo junto a Almacenes de datos. Según la selección de máquinas virtuales, las asignaciones de almacenes de datos se seleccionan automáticamente.
Esta sección puede estar habilitada o deshabilitada según su selección.
-
Utilizar copias de seguridad administradas por la plataforma y programas de retención: si está utilizando una solución de administración de instantáneas externa, marque esta casilla. NetApp Disaster Recovery admite el uso de soluciones de gestión de instantáneas externas, como el programador de políticas nativo ONTAP SnapMirror o integraciones de terceros. Si cada almacén de datos (volumen) en el plan de replicación ya tiene una relación SnapMirror que se administra en otro lugar, puede usar esas instantáneas como puntos de recuperación en NetApp Disaster Recovery.
Cuando se selecciona esta opción, NetApp Disaster Recovery no configura una programación de respaldo. Sin embargo, aún es necesario configurar un programa de retención porque aún se podrían tomar instantáneas para operaciones de prueba, conmutación por error y recuperación.
Una vez configurado esto, el servicio no toma ninguna instantánea programada regularmente, sino que depende de la entidad externa para tomar y actualizar esas instantáneas.
-
Backups and retention start time: Introduce la fecha y hora en la que quieres que empiecen a ejecutarse las copias de seguridad y la retención.
-
Copias de seguridad y frecuencia de retención: introduce el intervalo de tiempo en horas y minutos. Por ejemplo, si introduces 1 hora, el servicio realizará una instantánea cada hora.
-
Recuento de retención para todos los almacenes de datos: Ingresa el número de instantáneas que quieres conservar.
La cantidad de instantáneas retenidas junto con la tasa de cambio de datos entre cada instantánea determina la cantidad de espacio de almacenamiento consumido tanto en el origen como en el destino. Cuanto más instantáneas conserve, más espacio de almacenamiento se consumirá. -
Almacenes de datos de origen y destino: si existen múltiples relaciones SnapMirror (de abanico), puede seleccionar el destino que desea utilizar. Si un volumen ya tiene una relación SnapMirror establecida, aparecen los almacenes de datos de origen y destino correspondientes. Si un volumen no tiene una relación SnapMirror , puede crear uno ahora seleccionando un clúster de destino, seleccionando un SVM de destino y proporcionando un nombre de volumen. El servicio creará el volumen y la relación SnapMirror .
Si desea crear una relación SnapMirror en este servicio, el clúster y su emparejamiento SVM ya deben haberse configurado fuera de NetApp Disaster Recovery. -
Si las máquinas virtuales son del mismo volumen y del mismo SVM, el servicio realiza una instantánea de ONTAP estándar y actualiza los destinos secundarios.
-
Si las máquinas virtuales son de diferentes volúmenes y del mismo SVM, el servicio crea una instantánea del grupo de consistencia incluyendo todos los volúmenes y actualiza los destinos secundarios.
-
Si las máquinas virtuales son de diferentes volúmenes y diferentes SVM, el servicio realiza una instantánea de la fase de inicio y la fase de confirmación del grupo de consistencia incluyendo todos los volúmenes en el mismo clúster o en uno diferente y actualiza los destinos secundarios.
-
Durante la conmutación por error, puede seleccionar cualquier instantánea. Si selecciona la última instantánea, el servicio crea una copia de seguridad a pedido, actualiza el destino y utiliza esa instantánea para la conmutación por error.
-
Agregar asignaciones de conmutación por error de prueba
-
Para configurar diferentes asignaciones para el entorno de prueba, desmarque la casilla y seleccione la pestaña Asignaciones de prueba.
-
Revise cada pestaña como antes, pero esta vez para el entorno de prueba.
En la pestaña Asignaciones de prueba, las asignaciones de máquinas virtuales y almacenes de datos están deshabilitadas.
Podrás probar el plan completo más tarde. En este momento, estás configurando las asignaciones para el entorno de prueba.
Revisar el plan de replicación
Por último, tómese unos momentos para revisar el plan de replicación.
|
|
Posteriormente podrá deshabilitar o eliminar el plan de replicación. |
-
Revise la información en cada pestaña: Detalles del plan, Mapeo de conmutación por error y Máquinas virtuales.
-
Seleccione Agregar plan.
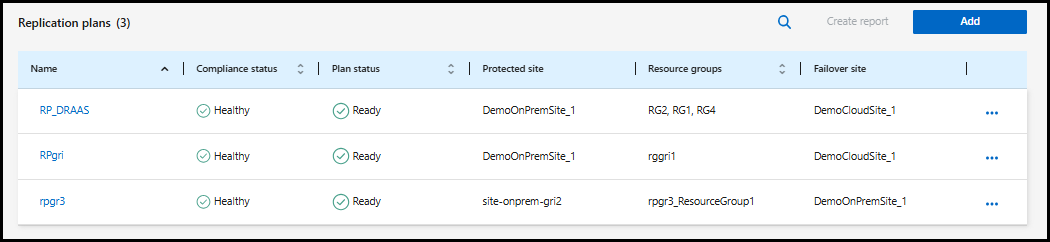
El plan se agrega a la lista de planes.
Modificar un plan de replicación
Puedes modificar la programación de un plan de replicación para comprobar el cumplimiento y asegurarte de que las pruebas de conmutación por error se completen correctamente.
-
Impacto en el tiempo de cumplimiento: cuando se crea un plan de replicación, el servicio crea un programa de cumplimiento de forma predeterminada. El tiempo de cumplimiento predeterminado es de 30 minutos. Para cambiar este tiempo, puede editar la programación en el plan de replicación.
-
Impacto de la conmutación por error de prueba: puede probar un proceso de conmutación por error a pedido o según un cronograma. Esto le permite probar la conmutación por error de máquinas virtuales a un destino especificado en un plan de replicación.
Una conmutación por error de prueba crea un volumen FlexClone , monta el almacén de datos y mueve la carga de trabajo en ese almacén de datos. Una operación de conmutación por error de prueba no afecta las cargas de trabajo de producción, la relación SnapMirror utilizada en el sitio de prueba y las cargas de trabajo protegidas que deben seguir funcionando normalmente.
Según el cronograma, se ejecuta la prueba de conmutación por error y garantiza que las cargas de trabajo se muevan al destino especificado por el plan de replicación.
-
En el menú NetApp Disaster Recovery , seleccione Planes de replicación.
-
Seleccione las Acciones*
 icono y seleccione *Editar horarios.
icono y seleccione *Editar horarios. -
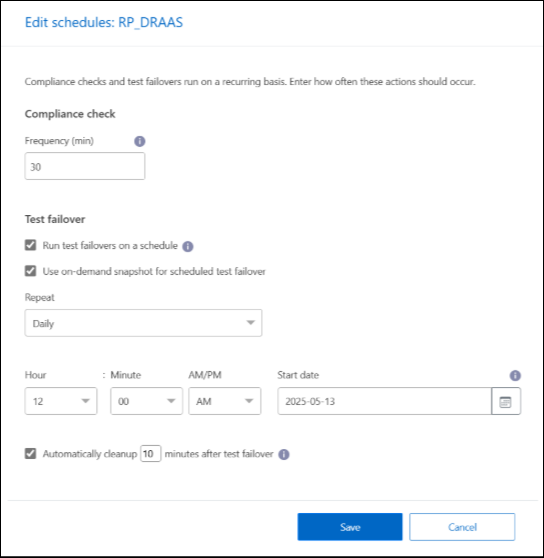
Ingrese la frecuencia en minutos con la que desea que NetApp Disaster Recovery verifique el cumplimiento de las pruebas.
-
Para comprobar que sus pruebas de conmutación por error funcionan correctamente, marque Ejecutar conmutaciones por error según una programación mensual.
-
Seleccione el día del mes y la hora en que desea que se ejecuten estas pruebas.
-
Ingrese la fecha en formato aaaa-mm-dd en la que desea que comience la prueba.
-
-
Usar instantánea a pedido para conmutación por error de prueba programada: para tomar una nueva instantánea antes de iniciar la conmutación por error de prueba automatizada, marque esta casilla.
-
Para limpiar el entorno de prueba una vez finalizada la prueba de conmutación por error, marque Limpiar automáticamente después de la conmutación por error de prueba e ingrese la cantidad de minutos que desea esperar antes de que comience la limpieza.
Este proceso anula el registro de las máquinas virtuales temporales de la ubicación de prueba, elimina el volumen FlexClone que se creó y desmonta los almacenes de datos temporales. -
Seleccione Guardar.