TR-4920: Continuidad del negocio de FlexPod Datacenter con NetApp SnapMirror y ONTAP 9.10
 Sugerir cambios
Sugerir cambios
Jyh-shing Chen, NetApp
Introducción
Solución de FlexPod
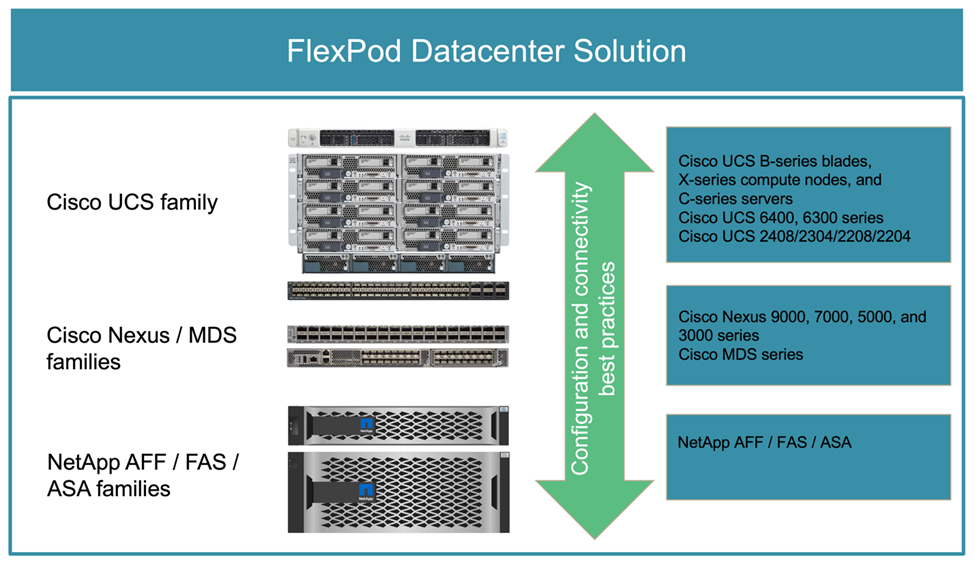
FlexPod es una arquitectura de centro de datos de infraestructura convergente que incluye los siguientes componentes de Cisco y NetApp:
-
Sistema de computación unificada de Cisco (Cisco UCS)
-
Familias de switches Cisco Nexus y MDS
-
Sistemas de cabinas FAS, AFF de NetApp y All SAN (ASA) de NetApp
En la siguiente figura, se describen algunos de los componentes utilizados para crear soluciones de FlexPod. Estos componentes están conectados y configurados según las prácticas recomendadas de Cisco y NetApp, a fin de proporcionar una plataforma ideal para ejecutar diversas cargas de trabajo empresariales con total confianza.
Hay disponible una amplia cartera de diseños validados por Cisco (CVD) y arquitecturas verificadas por NetApp (NVA). Estos CVD y NVA cubren todas las principales cargas de trabajo de los centros de datos y son el resultado de colaboraciones e innovaciones continuas entre NetApp y Cisco en soluciones FlexPod.
Incorporando pruebas y validaciones en su proceso de creación, los CVD y NVA de FlexPod proporcionan diseños de arquitectura de la solución de referencia y guías de puesta en marcha paso a paso para ayudar a los partners y a los clientes a poner en marcha y adoptar soluciones FlexPod. Al utilizar estos CVD y NVA como guías para el diseño y la implementación, las empresas pueden reducir los riesgos, reducir los tiempos de inactividad de la solución y aumentar la disponibilidad, la escalabilidad, la flexibilidad y la seguridad de las soluciones FlexPod que implementan.
Cada una de las familias de componentes de FlexPod mostradas (Cisco UCS, switches Cisco Nexus/MDS y almacenamiento de NetApp) ofrece opciones de plataformas y recursos para escalar la infraestructura de forma horizontal o vertical, al tiempo que admiten las características y la funcionalidad necesarias en las prácticas recomendadas de configuración y conectividad de FlexPod. FlexPod también se puede escalar horizontalmente para entornos que requieran varias puestas en marcha consistentes al implementar pilas FlexPod adicionales.
Continuidad del negocio y recuperación tras desastres
Las empresas pueden adoptar varios métodos para asegurarse de que pueden recuperar rápidamente sus servicios de datos y aplicaciones tras un desastre. Tener un plan de recuperación ante desastres (DR) y continuidad del negocio (BC), implementar una solución que cumpla con los objetivos empresariales y realizar pruebas regulares de los escenarios de desastre permite a las empresas recuperarse de un desastre y continuar con servicios empresariales críticos después de que se produzca una situación de desastre.
Es posible que las empresas tengan distintos requisitos de recuperación ante desastres y continuidad del negocio para distintos tipos de servicios de datos y aplicaciones. Es posible que algunas aplicaciones y datos no sean necesarios durante una situación de emergencia o desastre, mientras que otras deben estar siempre disponibles para respaldar los requisitos empresariales.
En el caso de servicios de datos y aplicaciones cruciales para la misión que podrían interrumpir su negocio cuando no estén disponibles, es necesario realizar una evaluación cuidadosa para responder a preguntas como qué tipo de situaciones de desastre y mantenimiento tiene que tener en cuenta la empresa, ¿cuántos datos puede permitirse perder los negocios en caso de desastre y con qué rapidez puede y debería producirse la recuperación?
Para las empresas que dependen de los servicios de datos para la generación de ingresos, es posible que los servicios de datos deban protegerse con una solución que pueda resistir no solo varios escenarios de un único punto de fallo, sino también un escenario de desastre de interrupción del servicio del sitio para proporcionar operaciones empresariales continuas.
Objetivo de punto de recuperación y objetivo de tiempo de recuperación
El objetivo de punto de recuperación (RPO) mide cuántos datos, en términos de tiempo, se pueden permitir perder o el punto hasta el que se pueden recuperar los datos. Con un plan de backup diario, una empresa puede perder un día de datos, ya que los cambios realizados en los datos desde el último backup podrían perderse en caso de desastre. En el caso de servicios de datos vitales para el negocio, puede que necesite un objetivo de punto de recuperación cero, así como una planificación e infraestructuras asociadas para proteger los datos sin pérdida alguna.
El objetivo de tiempo de recuperación (RTO) mide cuánto tiempo se puede permitir no tener los datos disponibles o la rapidez con la que se deben recuperar los servicios de datos. Por ejemplo, una empresa puede tener una implementación de backup y recuperación que utilice cintas tradicionales para ciertos conjuntos de datos debido a su tamaño. Como resultado, para restaurar los datos desde las cintas de backup, puede tardar varias horas o incluso días en caso de un fallo de la infraestructura. Además, las consideraciones en cuanto a tiempo deben incluir el tiempo para volver a poner en marcha la infraestructura además de restaurar los datos. En el caso de los servicios de datos de misión crítica, es posible que necesite un objetivo de tiempo de recuperación muy bajo y, por lo tanto, solo puede tolerar un tiempo de conmutación por error de segundos o minutos para volver a poner los servicios de datos online rápidamente y garantizar la continuidad del negocio.
SM-BC
A partir de ONTAP 9.8, puede proteger las cargas DE trabajo SAN para una conmutación por error de aplicaciones transparente con SM-BC de NetApp. Puede crear relaciones de grupos de consistencia entre dos clústeres de AFF o dos clústeres de ASA para que la replicación de datos logre un objetivo de punto de recuperación cero y un objetivo de tiempo de recuperación casi cero.
La solución SM-BC replica los datos mediante la tecnología SnapMirror Synchronous en una red IP. Proporciona granularidad en el nivel de las aplicaciones y conmutación por error automática para proteger los servicios de datos esenciales para la empresa, como Microsoft SQL Server, Oracle, etc., con LUN DE SAN basados en protocolos iSCSI o FC. Un mediador de ONTAP implementado en un centro tercero supervisa la solución SM-BC y permite la recuperación automática tras un desastre en el sitio.
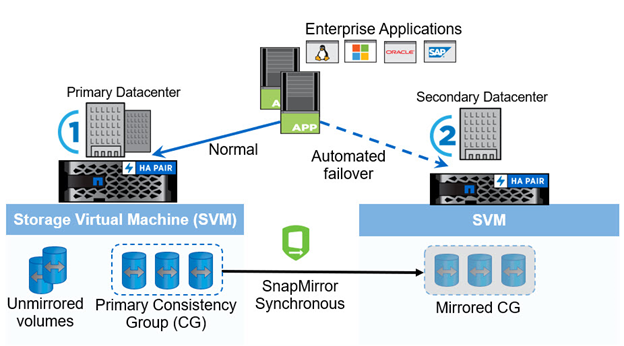
Un grupo de consistencia (CG) es una colección de volúmenes de FlexVol que proporciona una garantía de consistencia de orden de escritura para la carga de trabajo de la aplicación que debe protegerse para la continuidad empresarial. Permite realizar copias Snapshot simultáneas y coherentes con los fallos de una colección de volúmenes en un momento específico. Se establece una relación de SnapMirror, también conocida como una relación de CG, entre un CG de origen y un CG de destino. El grupo de volúmenes que se seleccionó para formar parte de un CG puede asignarse a una instancia de aplicación, a un grupo de instancias de aplicaciones o a una solución completa. Además, las relaciones del grupo de coherencia de SM-BC pueden crearse o eliminarse bajo demanda en función de los requisitos empresariales y cambios.
Como se muestra en la siguiente figura, los datos del grupo de consistencia se replican en un segundo clúster de ONTAP para recuperación ante desastres y continuidad del negocio. Las aplicaciones tienen conectividad con las LUN en ambos clústeres de ONTAP. El clúster principal proporciona I/o y se reanuda automáticamente desde el clúster secundario si se produce un desastre en el principal. Al diseñar una solución SM-BC, se deben observar los números de objetos admitidos para las relaciones de CG (por ejemplo, un máximo de 20 CG y un máximo de 200 extremos) para evitar que se superen los límites admitidos.