

FabricPool
 Sugerir cambios
Sugerir cambios
Información general de FabricPool
FabricPool es una solución de almacenamiento híbrido en ONTAP que utiliza un agregado all-flash (SSD) como nivel de rendimiento y un almacén de objetos en un servicio de cloud público como nivel del cloud. Esta configuración permite el movimiento de datos basado en políticas, en función de si se accede con frecuencia a los datos o no. ONTAP admite FabricPool tanto para agregados AFF como para todos los SSD en plataformas FAS. El procesamiento de datos se realiza a nivel de bloque, con los bloques de datos a los que se accede con frecuencia en el nivel de rendimiento all-flash etiquetados como bloques activos y a los que se accede con poca frecuencia como inactivos.
El uso de FabricPool permite reducir los costes de almacenamiento sin sacrificar rendimiento, eficiencia, seguridad ni protección. FabricPool es transparente para las aplicaciones empresariales y aprovecha las eficiencias del cloud al reducir el TCO del almacenamiento sin tener que rediseñar la arquitectura de la infraestructura de aplicaciones.
FlexPod se puede beneficiar de las funcionalidades de almacenamiento por niveles de FabricPool para hacer un uso más eficiente del almacenamiento flash de ONTAP. Las máquinas virtuales inactivas (VM), las plantillas de máquinas virtuales que se usan con poca frecuencia y los backups de máquinas virtuales de NetApp SnapCenter para vSphere pueden consumir un espacio valioso en el volumen del almacén de datos. El traslado de datos inactivos al nivel de cloud libera espacio y recursos para las aplicaciones de alto rendimiento esenciales que se alojan en la infraestructura de FlexPod.

|
Los protocolos Fibre Channel e iSCSI suelen tardar más en experimentar un tiempo de espera (de 60 a 120 segundos), pero no se intentan volver a establecer una conexión del mismo modo que lo hacen los protocolos NAS. Si se agota el tiempo de espera de un protocolo SAN, debe reiniciarse la aplicación. Incluso una breve interrupción podría ser desastrosa para las aplicaciones de producción que utilizan protocolos SAN, ya que no hay forma de garantizar la conectividad con los clouds públicos. Para evitar este problema, NetApp recomienda el uso de clouds privados cuando la organización en niveles de los datos a los que acceden los protocolos SAN. |
En ONTAP 9.6, FabricPool se integra con todos los principales proveedores de cloud público: Alibaba Cloud Object Storage Service, Amazon AWS S3, Google Cloud Storage, IBM Cloud Object Storage y Microsoft Azure Blob Storage. Este informe se centra en el almacenamiento Amazon AWS S3 como nivel de objetos en el cloud elegido.
El agregado compuesto
Para crear una instancia de FabricPool, se asocia un agregado flash de ONTAP a un almacén de objetos en el cloud, como un bloque de AWS S3, para crear un agregado compuesto. Cuando se crean volúmenes dentro del agregado compuesto, se pueden aprovechar las funcionalidades de organización en niveles de FabricPool. Cuando se escriben datos en el volumen, ONTAP asigna una temperatura a cada uno de los bloques de datos. Cuando el bloque se escribe por primera vez, se le asigna una temperatura de calor. A medida que pasa el tiempo, si no se accede a los datos, se somete a un proceso de refrigeración hasta que finalmente se le asigna un estado de frío. Estos bloques de datos a los que se accede con poca frecuencia se organizan en niveles fuera del agregado de SSD de rendimiento y en el almacén de objetos en el cloud.
El período de tiempo entre el momento en el que un bloque se designa como frío y el momento en el que se mueve al almacenamiento de objetos en cloud se modifica con la política de organización en niveles del volumen en ONTAP. Se logra más granularidad mediante la modificación de la configuración de ONTAP que controla el número de días necesarios para que un bloque quede frío. Los candidatos para la organización en niveles de datos son las copias Snapshot de volúmenes tradicionales, los backups de SnapCenter para vSphere VM y otros backups basados en Snapshot de NetApp, y los bloques que se usan con poca frecuencia en un almacén de datos de vSphere, como las plantillas de máquinas virtuales y los datos de estas máquinas a los que se accede con poca frecuencia.
Generación de informes de datos inactivos
Los informes de datos inactivos (IDR, por sus siglas en inglés) están disponibles en ONTAP para ayudar a evaluar la cantidad de datos inactivos que se pueden organizar en niveles a partir de un agregado. IDR está activado de forma predeterminada en ONTAP 9.6 y utiliza una directiva de refrigeración predeterminada de 31 días para determinar qué datos del volumen están inactivos.
|
|
La cantidad de datos inactivos organizados en niveles depende de las políticas de organización en niveles establecidas en el volumen. Esta cantidad puede ser diferente de la cantidad de datos fríos detectados por IDR utilizando el período de enfriamiento predeterminado de 31 días. |
Creación de objetos y movimiento de datos
FabricPool funciona con bloques WAFL de NetApp, bloques de refrigeración, concatenarlos y objetos de almacenamiento y migran esos objetos a un nivel de cloud. Cada objeto de FabricPool es de 4 MB y está compuesto por 1,024 bloques de 4 KB. El tamaño del objeto es fijo de 4 MB en función de las recomendaciones de rendimiento de los principales proveedores de cloud y no puede modificarse. Si los bloques inactivos se leen y se activan, solo se recuperan los bloques solicitados del objeto de 4 MB y se vuelven a mover al nivel de rendimiento. Ni el objeto completo ni el archivo completo se vuelven a migrar. Solo se migran los bloques necesarios.
|
|
Si ONTAP detecta una oportunidad para lecturas secuenciales, solicita bloques del nivel de cloud antes de que se lean para mejorar el rendimiento. |
De forma predeterminada, los datos se mueven al nivel de cloud solo cuando se utiliza el agregado de rendimiento superior al 50 %. Este umbral se puede establecer en un porcentaje más bajo para permitir una menor cantidad de almacenamiento de datos en el nivel flash de rendimiento para moverse al cloud. Esto podría resultar útil si la estrategia de organización en niveles consiste en mover datos inactivos solo cuando el agregado está cerca de la capacidad.
Si el uso del nivel de rendimiento supera el 70 % de la capacidad, los datos inactivos se leen directamente desde el nivel de cloud sin que se vuelvan a escribir en el nivel de rendimiento. Al evitar la escritura de datos fríos en agregados muy utilizados, FabricPool conserva el agregado para los datos activos.
Reclame espacio en el nivel de rendimiento
Como hemos visto anteriormente, el principal caso de uso de FabricPool es facilitar el uso más eficiente del almacenamiento flash local de alto rendimiento. Los datos inactivos en forma de copias Snapshot de volumen y backup de equipos virtuales de la infraestructura virtual de FlexPod pueden ocupar una gran cantidad de almacenamiento flash de elevado coste. El valioso almacenamiento en el nivel de rendimiento se puede liberar implementando una de las dos políticas de almacenamiento por niveles: Solo Snapshot o automático.
Política de organización en niveles solo de Snapshot
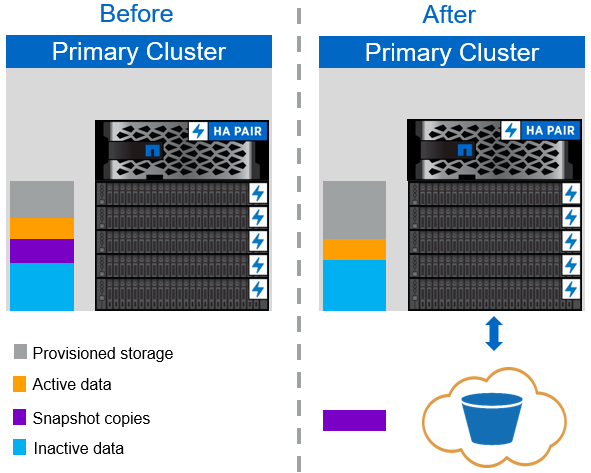
La política de organización en niveles de solo Snapshot, que se muestra en la siguiente figura, mueve datos Snapshot de volumen frío y backups de SnapCenter para vSphere de máquinas virtuales que ocupan espacio pero no comparten bloques con el sistema de archivos activo a un almacén de objetos de cloud. La política de organización en niveles solo de Snapshot mueve bloques de datos inactivos al nivel de cloud. Si hace falta una restauración, los bloques fríos en el cloud se activan y vuelven a transferirse al nivel flash de rendimiento de las instalaciones.
Política de organización automática en niveles
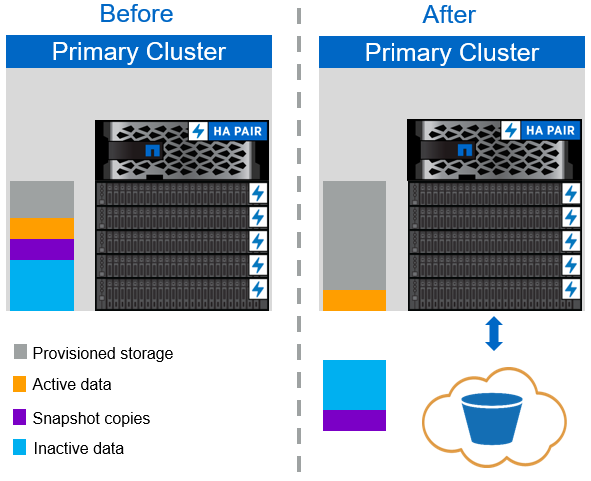
La política de organización en niveles automática de FabricPool, que se muestra en la siguiente figura, no solo mueve bloques de datos de copias snapshot activas al cloud, sino que también mueve bloques de datos inactivos del sistema de archivos activo. Esto puede incluir plantillas de máquina virtual y todos los datos de máquina virtual sin usar en el volumen de almacén de datos. Los bloques fríos que se mueven se controlan mediante el tiering-minimum-cooling-days configuración para el volumen. Si una aplicación lee aleatoriamente los bloques inactivos en el nivel de cloud, esos bloques se activan y vuelven a traerlos al nivel de rendimiento. Sin embargo, si un proceso secuencial lee los bloques fríos, como un análisis antivirus, los bloques permanecen inactivos y persisten en el almacén de objetos en la nube, ya que no se mueven de nuevo al nivel de rendimiento.
Cuando se usa la política de organización en niveles automática, los bloques a los que se accede con poca frecuencia se devuelven del nivel de cloud a la velocidad de conectividad del cloud. Esto puede afectar al rendimiento de la VM si la aplicación es sensible a la latencia, que debe tenerse en cuenta antes de usar la política de organización en niveles automática en el almacén de datos. NetApp recomienda colocar LIF de interconexión de clústeres en puertos con una velocidad de 10 GbE para lograr un rendimiento adecuado.
|
|
El generador de perfiles de almacén de objetos se debe usar para probar la latencia y el rendimiento del almacén de objetos antes de adjuntarlo a un agregado de FabricPool. |
Toda la política de organización en niveles
A diferencia de las políticas Auto y Snapshot, la política de organización en niveles total mueve volúmenes completos de datos inmediatamente al nivel de cloud. Esta política es más adecuada para la protección de datos secundaria o volúmenes de archivado para los que es necesario conservar los datos con fines históricos o normativos, pero a los que no se accede en raras ocasiones. La política todo no se recomienda para los volúmenes de almacenes de datos de VMware, ya que los datos escritos en el almacén de datos se mueven de inmediato al nivel de cloud. Las operaciones de lectura posteriores se realizan desde el cloud y podrían introducir problemas de rendimiento para las máquinas virtuales y las aplicaciones que residen en el volumen del almacén de datos.
Seguridad
La seguridad es una preocupación central para el cloud y FabricPool. Todas las funciones de seguridad nativas de ONTAP son compatibles con el nivel de rendimiento y el movimiento de datos se protege mientras se transfieren al nivel de cloud. FabricPool utiliza la "AES-256-GCM" el algoritmo de cifrado en el nivel de rendimiento y mantiene este cifrado de extremo a extremo en el nivel del cloud. Los bloques de datos que se mueven al almacén de objetos en el cloud están protegidos con seguridad de la capa de transporte (TLS) v1.2 a fin de mantener la confidencialidad y la integridad de los datos entre los niveles de almacenamiento.
|
|
NetApp admite la comunicación con el almacén de objetos cloud mediante una conexión no cifrada, pero no la recomienda. |
Cifrado de datos
El cifrado de datos es fundamental para la protección de la propiedad intelectual, la información comercial y la información personal del cliente. FabricPool es totalmente compatible tanto con el cifrado de volúmenes de NetApp (NVE) como con el cifrado del almacenamiento de NetApp (NSE) para mantener las estrategias de protección de datos existentes. Todos los datos cifrados en el nivel de rendimiento permanecen cifrados cuando se mueven al nivel de cloud. Las claves de cifrado en el cliente son propiedad de ONTAP, mientras que las claves de cifrado del almacén de objetos en el servidor son propiedad del almacén de objetos en cloud correspondiente. Los datos que no estén cifrados con NVE se cifran con el algoritmo AES-256-GCM. No se admiten otros cifrados AES-256.
|
|
El uso de NSE o NVE es opcional y no es obligatorio para utilizar FabricPool. |