

Solución de transferencia de datos
 Sugerir cambios
Sugerir cambios
En un clúster de big data, los datos se almacenan en HDFS o HCFS, como MapR-FS, Windows Azure Storage Blob, S3 o el sistema de archivos de Google. Realizamos pruebas con HDFS, MapR-FS y S3 como fuente para copiar datos a la exportación NFS de NetApp ONTAP con la ayuda de NIPAM mediante el uso de hadoop distcp comando de la fuente.
El siguiente diagrama ilustra el movimiento de datos típico de un clúster Spark que se ejecuta con almacenamiento HDFS a un volumen NFS de NetApp ONTAP para que NVIDIA pueda procesar operaciones de IA.
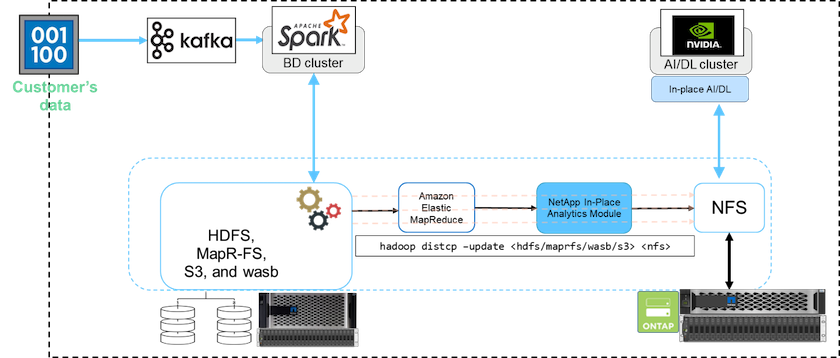
El hadoop distcp El comando utiliza el programa MapReduce para copiar los datos. NIPAM trabaja con MapReduce para actuar como controlador del clúster Hadoop al copiar datos. NIPAM puede distribuir una carga a través de múltiples interfaces de red para una sola exportación. Este proceso maximiza el rendimiento de la red al distribuir los datos a través de múltiples interfaces de red cuando copia los datos de HDFS o HCFS a NFS.

|
NIPAM no es compatible ni está certificado con MapR. |