TR-4912: Pautas recomendadas para el almacenamiento en niveles de Confluent Kafka con NetApp
 Sugerir cambios
Sugerir cambios
Karthikeyan Nagalingam, Joseph Kandatilparambil, NetApp Rankesh Kumar, Confluent
Apache Kafka es una plataforma de transmisión de eventos distribuida por la comunidad capaz de gestionar billones de eventos al día. Inicialmente concebido como una cola de mensajes, Kafka se basa en una abstracción de un registro de confirmación distribuido. Desde que LinkedIn lo creó y lo puso en código abierto en 2011, Kafka ha evolucionado desde una cola de mensajes a una plataforma completa de transmisión de eventos. Confluent ofrece la distribución de Apache Kafka con la plataforma Confluent. La plataforma Confluent complementa Kafka con funciones comerciales y comunitarias adicionales diseñadas para mejorar la experiencia de transmisión tanto de operadores como de desarrolladores en producción a gran escala.
Este documento describe las pautas recomendadas para usar Confluent Tiered Storage en una oferta de almacenamiento de objetos de NetApp proporcionando el siguiente contenido:
-
Verificación confluente con almacenamiento de objetos de NetApp – NetApp StorageGRID
-
Pruebas de rendimiento de almacenamiento por niveles
-
Pautas de mejores prácticas para Confluent en sistemas de almacenamiento NetApp
¿Por qué el almacenamiento en niveles de Confluent?
Confluent se ha convertido en la plataforma de transmisión en tiempo real predeterminada para muchas aplicaciones, especialmente para big data, análisis y cargas de trabajo de transmisión. El almacenamiento en niveles permite a los usuarios separar el procesamiento del almacenamiento en la plataforma Confluent. Hace que el almacenamiento de datos sea más rentable, le permite almacenar cantidades prácticamente infinitas de datos y escalar cargas de trabajo hacia arriba (o hacia abajo) según demanda, y facilita las tareas administrativas como el reequilibrio de datos e inquilinos. Los sistemas de almacenamiento compatibles con S3 pueden aprovechar todas estas capacidades para democratizar los datos con todos los eventos en un solo lugar, eliminando la necesidad de una ingeniería de datos compleja. Para obtener más información sobre por qué debería utilizar almacenamiento por niveles para Kafka, consulte"Este artículo de Confluent" .
NetApp instaclustr también es compatible con Kafka con almacenamiento en niveles desde 3.8.1. Por favor, consulte más detalles aquí "Instaclust con almacenamiento por niveles de Kafka"
¿Por qué NetApp StorageGRID para el almacenamiento en niveles?
StorageGRID es una plataforma de almacenamiento de objetos líder en la industria de NetApp. StorageGRID es una solución de almacenamiento basada en objetos y definida por software que admite API de objetos estándar de la industria, incluida la API de Amazon Simple Storage Service (S3). StorageGRID almacena y administra datos no estructurados a escala para proporcionar un almacenamiento de objetos seguro y duradero. El contenido se coloca en el lugar correcto, en el momento correcto y en el nivel de almacenamiento correcto, lo que optimiza los flujos de trabajo y reduce los costos de los medios enriquecidos distribuidos globalmente.
El mayor diferenciador de StorageGRID es su motor de políticas de gestión del ciclo de vida de la información (ILM) que permite la gestión del ciclo de vida de los datos basada en políticas. El motor de políticas puede usar metadatos para administrar cómo se almacenan los datos a lo largo de su vida útil para optimizar inicialmente el rendimiento y optimizar automáticamente el costo y la durabilidad a medida que los datos envejecen.
Habilitación del almacenamiento en niveles confluent
La idea básica del almacenamiento por niveles es separar las tareas de almacenamiento de datos del procesamiento de datos. Con esta separación, resulta mucho más fácil que el nivel de almacenamiento de datos y el nivel de procesamiento de datos escalen de forma independiente.
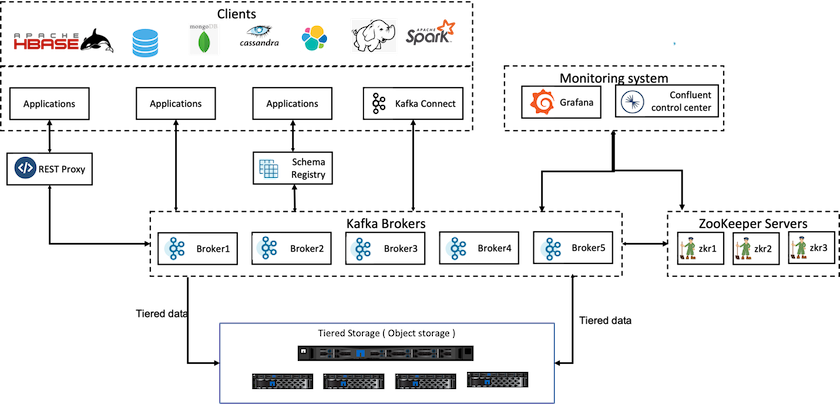
Una solución de almacenamiento por niveles para Confluent debe tener en cuenta dos factores. En primer lugar, debe solucionar o evitar las propiedades comunes de consistencia y disponibilidad del almacén de objetos, como las inconsistencias en las operaciones LIST y la falta de disponibilidad ocasional de objetos. En segundo lugar, debe gestionar correctamente la interacción entre el almacenamiento en niveles y el modelo de replicación y tolerancia a fallas de Kafka, incluida la posibilidad de que los líderes zombis sigan compensando rangos en niveles. El almacenamiento de objetos de NetApp brinda disponibilidad de objetos constante y el modelo HA hace que el almacenamiento agotado esté disponible para rangos de compensación de niveles. El almacenamiento de objetos de NetApp brinda disponibilidad de objetos constante y un modelo de alta disponibilidad (HA) para que el almacenamiento agotado esté disponible para rangos de compensación de niveles.
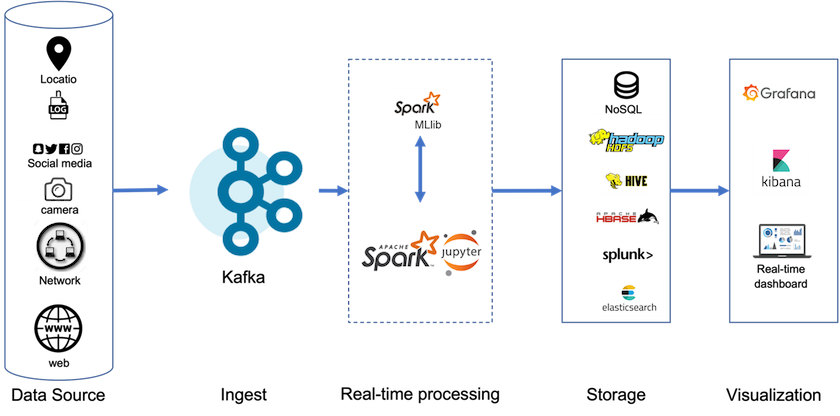
Con el almacenamiento en niveles, puede usar plataformas de alto rendimiento para lecturas y escrituras de baja latencia cerca del final de sus datos de transmisión, y también puede usar almacenes de objetos más económicos y escalables como NetApp StorageGRID para lecturas históricas de alto rendimiento. También tenemos una solución técnica para Spark con controlador de almacenamiento NetApp y los detalles están aquí. La siguiente figura muestra cómo Kafka encaja en un flujo de trabajo de análisis en tiempo real.
La siguiente figura muestra cómo NetApp StorageGRID encaja como nivel de almacenamiento de objetos de Confluent Kafka.