

Descripción general del rendimiento y validación con AFF A900 en las instalaciones
 Sugerir cambios
Sugerir cambios
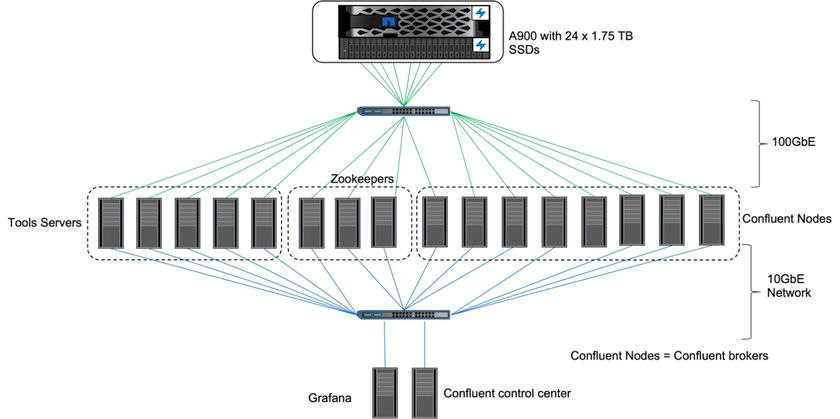
En las instalaciones, utilizamos el controlador de almacenamiento NetApp AFF A900 con ONTAP 9.12.1RC1 para validar el rendimiento y la escalabilidad de un clúster de Kafka. Utilizamos el mismo banco de pruebas que en nuestras prácticas recomendadas de almacenamiento en niveles anteriores con ONTAP y AFF.
Utilizamos Confluent Kafka 6.2.0 para evaluar el AFF A900. El clúster cuenta con ocho nodos intermediarios y tres nodos guardianes del zoológico. Para probar el rendimiento, utilizamos cinco nodos de trabajo OMB.
Configuración de almacenamiento
Utilizamos instancias de NetApp FlexGroups para proporcionar un único espacio de nombres para los directorios de registro, lo que simplifica la recuperación y la configuración. Utilizamos NFSv4.1 y pNFS para proporcionar acceso directo a los datos del segmento de registro.
Ajuste del cliente
Cada cliente montó la instancia de FlexGroup con el siguiente comando.
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
Además, aumentamos la max_session_slots` del valor predeterminado 64 a 180 . Esto coincide con el límite de espacio de sesión predeterminado en ONTAP.
Ajuste del bróker de Kafka
Para maximizar el rendimiento en el sistema bajo prueba, aumentamos significativamente los parámetros predeterminados para ciertos grupos de subprocesos clave. Recomendamos seguir las mejores prácticas de Confluent Kafka para la mayoría de las configuraciones. Este ajuste se utilizó para maximizar la concurrencia de E/S pendientes al almacenamiento. Estos parámetros se pueden ajustar para que coincidan con los recursos computacionales y los atributos de almacenamiento de su corredor.
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
Metodología de prueba del generador de carga de trabajo
Utilizamos las mismas configuraciones OMB que para las pruebas en la nube para el controlador de rendimiento y la configuración del tema.
-
Se aprovisionó una instancia de FlexGroup mediante Ansible en un clúster AFF .
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
Se habilitó pNFS en ONTAP SVM.
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
La carga de trabajo se activó con el controlador de rendimiento utilizando la misma configuración de carga de trabajo que para Cloud Volumes ONTAP. Ver la sección "Rendimiento en estado estacionario " abajo. La carga de trabajo utilizó un factor de replicación de 3, lo que significa que se mantuvieron tres copias de segmentos de registro en NFS.
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Por último, completamos mediciones utilizando un backlog para medir la capacidad de los consumidores para ponerse al día con los últimos mensajes. La OMB crea un backlog pausando a los consumidores durante el comienzo de una medición. Esto produce tres fases distintas: creación de cartera de pedidos (tráfico exclusivo del productor), vaciado de cartera de pedidos (una fase de gran actividad del consumidor en la que los consumidores se ponen al día con los eventos perdidos en un tema) y el estado estable. Ver la sección "Rendimiento extremo y exploración de los límites del almacenamiento " para obtener más información.
Rendimiento en estado estacionario
Evaluamos el AFF A900 utilizando OpenMessaging Benchmark para proporcionar una comparación similar a la de Cloud Volumes ONTAP en AWS y DAS en AWS. Todos los valores de rendimiento representan el rendimiento del clúster de Kafka a nivel de productor y consumidor.
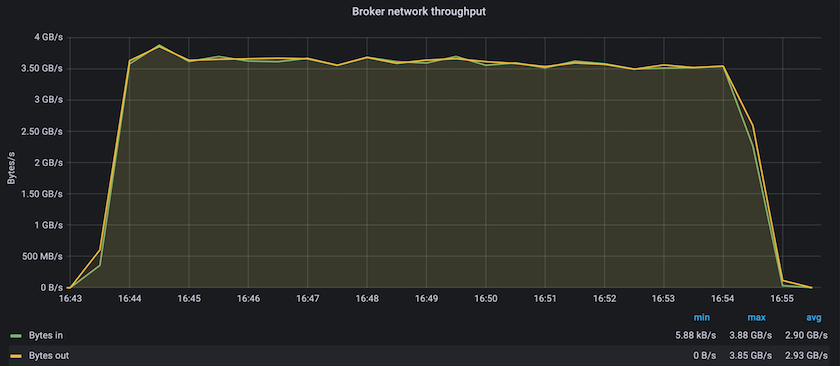
El rendimiento en estado estable con Confluent Kafka y AFF A900 logró un rendimiento promedio de más de 3,4 GBps tanto para el productor como para los consumidores. Esto supone más de 3,4 millones de mensajes en todo el clúster de Kafka. Al visualizar el rendimiento sostenido en bytes por segundo para BrokerTopicMetrics, vemos el excelente rendimiento en estado estable y el tráfico admitido por el AFF A900.
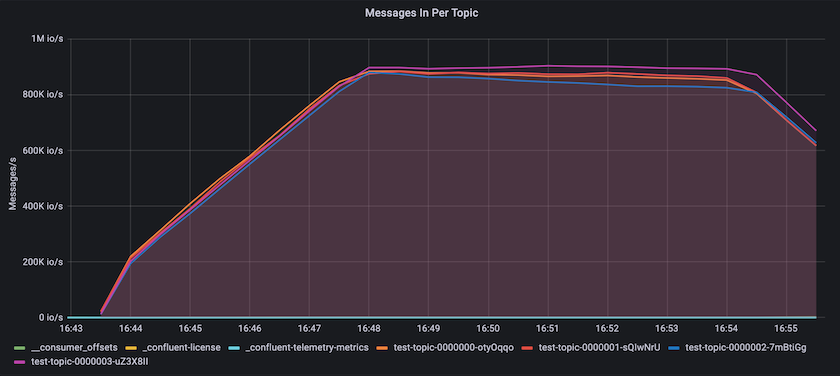
Esto se alinea bien con la vista de los mensajes entregados por tema. El siguiente gráfico proporciona un desglose por tema. En la configuración probada, vimos casi 900 000 mensajes por tema en cuatro temas.
Rendimiento extremo y exploración de los límites del almacenamiento
Para AFF, también realizamos pruebas con OMB utilizando la función de backlog. La función de acumulación de eventos pausa las suscripciones de los consumidores mientras se crea una acumulación de eventos en el clúster de Kafka. Durante esta fase, solo se produce tráfico de productor, lo que genera eventos que se confirman en los registros. Esto emula de manera más cercana el procesamiento por lotes o los flujos de trabajo de análisis fuera de línea; en estos flujos de trabajo, se inician las suscripciones de los consumidores y deben leer datos históricos que ya se han eliminado de la memoria caché del agente.
Para comprender las limitaciones de almacenamiento en el rendimiento del consumidor en esta configuración, medimos solo la fase de productor para comprender cuánto tráfico de escritura podía absorber el A900. Vea la siguiente sección "Guía de tallas "para entender cómo aprovechar estos datos.
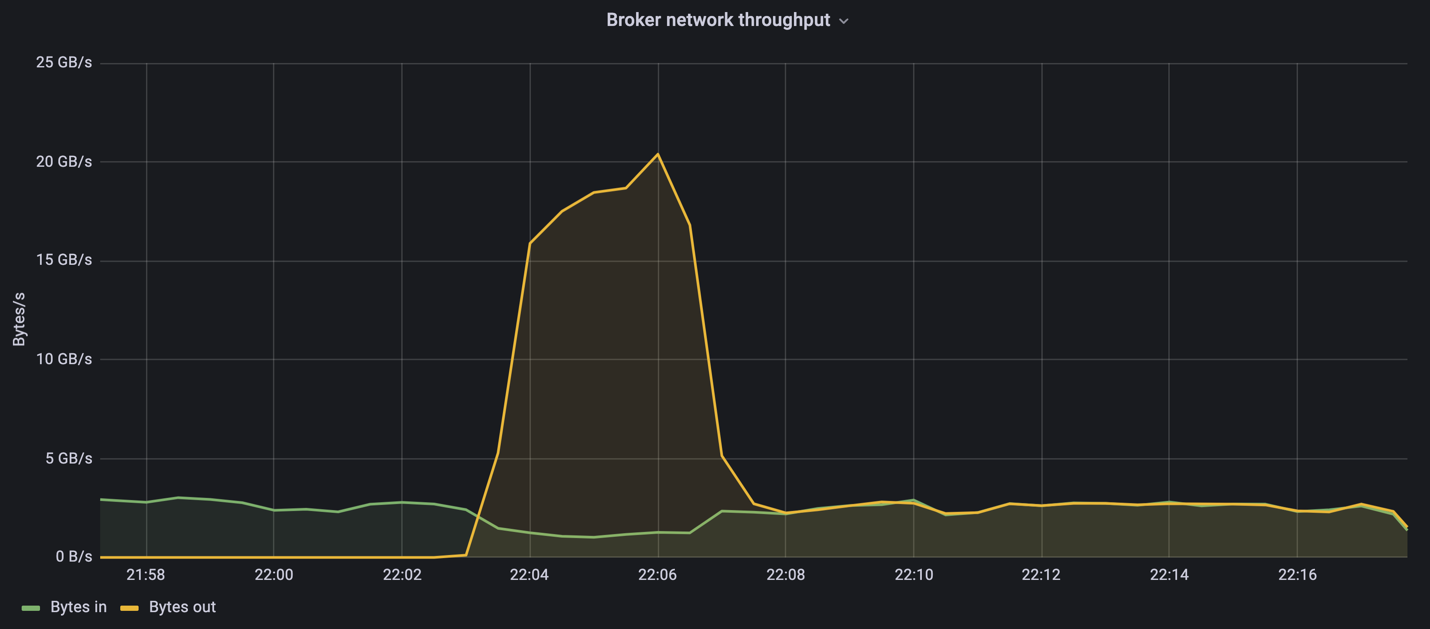
Durante la parte de esta medición solo para productores, vimos un alto pico de rendimiento que empujó los límites del rendimiento del A900 (cuando otros recursos del broker no estaban saturados y atendían el tráfico de productores y consumidores).

|
Aumentamos el tamaño del mensaje a 16k para esta medición para limitar los costos generales por mensaje y maximizar el rendimiento del almacenamiento en los puntos de montaje NFS. |
messageSize: 16384 consumerBacklogSizeGB: 4096
El clúster Confluent Kafka alcanzó un rendimiento máximo de producción de 4,03 GBps.
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
Después de que OMB terminó de completar el registro de eventos, se reinició el tráfico del consumidor. Durante las mediciones con drenaje de cartera, observamos un rendimiento máximo del consumidor de más de 20 GBps en todos los temas. El rendimiento combinado del volumen NFS que almacena los datos del registro OMB se acercó a ~30 GBps.
Guía de tallas
Amazon Web Services ofrece una "guía de tallas" para dimensionar y escalar clústeres de Kafka.
Este dimensionamiento proporciona una fórmula útil para determinar los requisitos de rendimiento de almacenamiento para su clúster de Kafka:
Para un rendimiento agregado producido en el clúster tcluster con un factor de replicación de r, el rendimiento recibido por el almacenamiento del intermediario es el siguiente:
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
Esto se puede simplificar aún más:
max(t[cluster]) <= max(t[storage]) * #brokers/r
El uso de esta fórmula le permite seleccionar la plataforma ONTAP adecuada para sus necesidades de nivel activo de Kafka.
La siguiente tabla explica el rendimiento del productor previsto para el A900 con diferentes factores de replicación:
| Factor de replicación | Rendimiento del productor (GPps) |
|---|---|
3 (medido) |
3,4 |
2 |
5,1 |
1 |
10,2 |