Descripción general del rendimiento y validación en AWS
 Sugerir cambios
Sugerir cambios
Se evaluó el rendimiento de un clúster de Kafka con la capa de almacenamiento montada en NetApp NFS en la nube de AWS. Los ejemplos de evaluación comparativa se describen en las siguientes secciones.
Kafka en la nube de AWS con NetApp Cloud Volumes ONTAP (par de alta disponibilidad y nodo único)
Se evaluó el rendimiento de un clúster de Kafka con NetApp Cloud Volumes ONTAP (par HA) en la nube de AWS. Esta evaluación comparativa se describe en las siguientes secciones.
Configuración arquitectónica
La siguiente tabla muestra la configuración ambiental para un clúster de Kafka que utiliza NAS.
| Componente de plataforma | Configuración del entorno |
|---|---|
Kafka 3.2.3 |
|
Sistema operativo en todos los nodos |
RHEL8.6 |
Instancia NetApp Cloud Volumes ONTAP |
Instancia de par HA: m5dn.12xLarge x 2 nodos Instancia de nodo único: m5dn.12xLarge x 1 nodo |
Configuración de ONTAP del volumen del clúster de NetApp
-
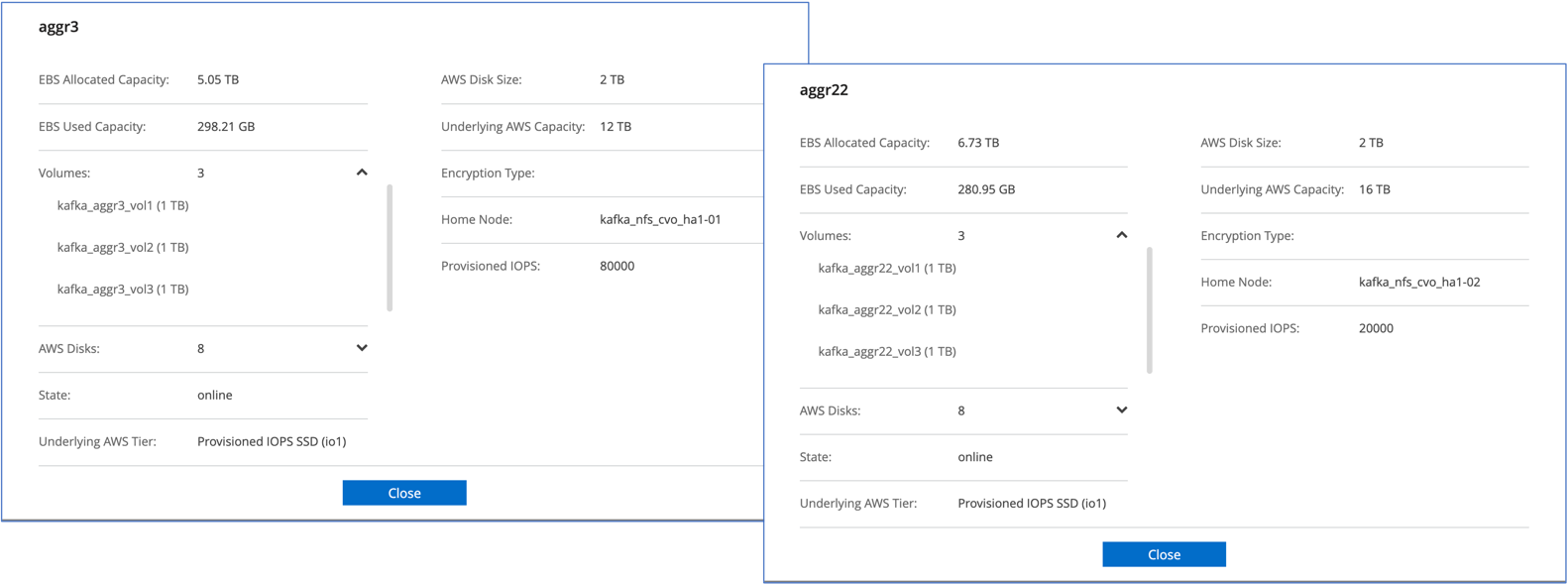
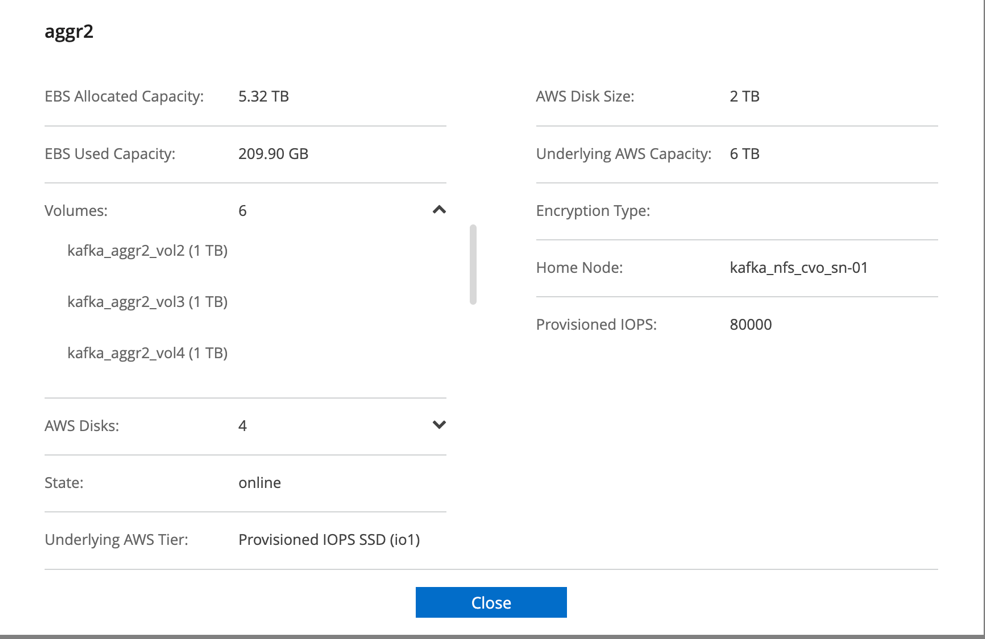
Para el par Cloud Volumes ONTAP HA, creamos dos agregados con tres volúmenes en cada agregado en cada controlador de almacenamiento. Para cada nodo de Cloud Volumes ONTAP , creamos seis volúmenes en total.
-
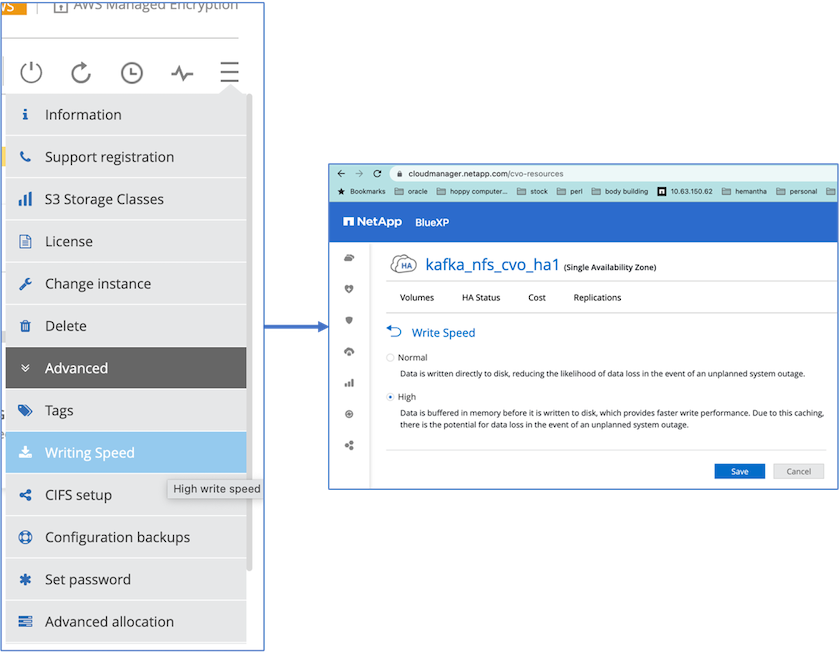
Para lograr un mejor rendimiento de la red, habilitamos redes de alta velocidad tanto para el par HA como para el nodo único.
-
Notamos que la NVRAM de ONTAP tenía más IOPS, por lo que cambiamos las IOPS a 2350 para el volumen raíz de Cloud Volumes ONTAP . El disco de volumen raíz en Cloud Volumes ONTAP tenía un tamaño de 47 GB. El siguiente comando ONTAP es para el par HA y el mismo paso se aplica para el nodo único.
statistics start -object vnvram -instance vnvram -counter backing_store_iops -sample-id sample_555 kafka_nfs_cvo_ha1::*> statistics show -sample-id sample_555 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-01 Counter Value -------------------------------- -------------------------------- backing_store_iops 1479 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-02 Counter Value -------------------------------- -------------------------------- backing_store_iops 1210 2 entries were displayed. kafka_nfs_cvo_ha1::*>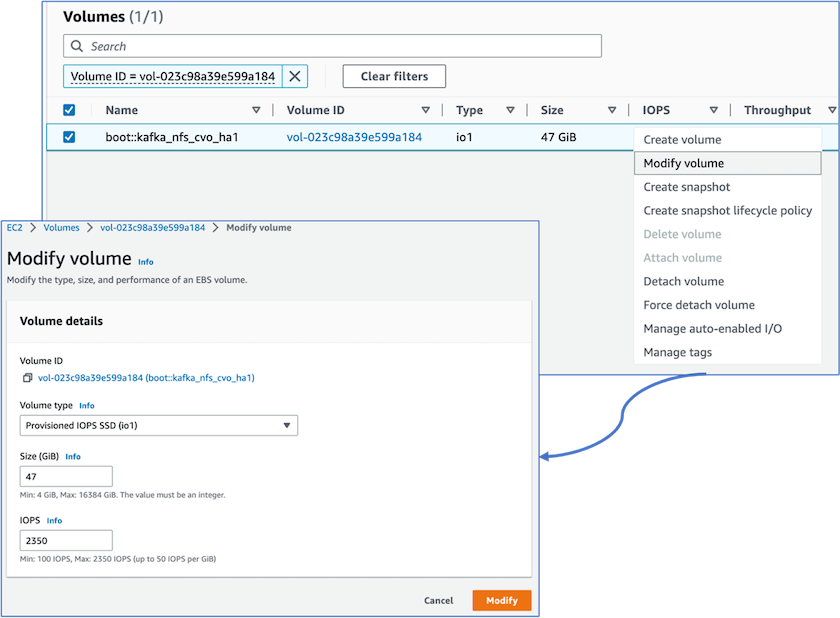
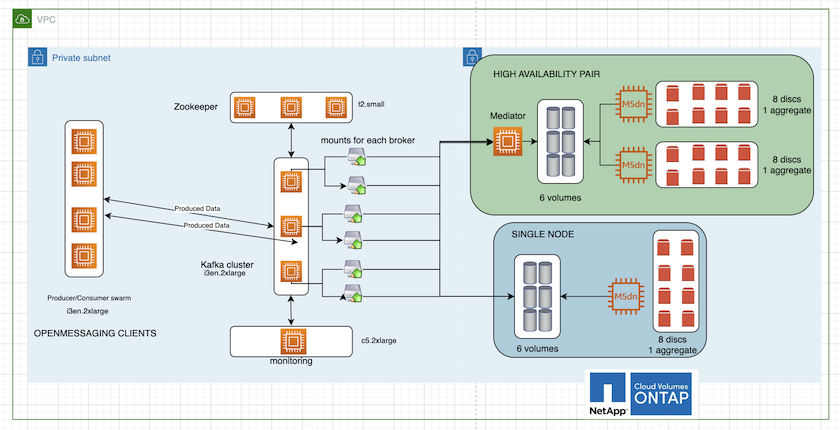
La siguiente figura muestra la arquitectura de un clúster de Kafka basado en NAS.
-
Calcular. Utilizamos un clúster Kafka de tres nodos con un conjunto Zookeeper de tres nodos ejecutándose en servidores dedicados. Cada agente tenía dos puntos de montaje NFS en un solo volumen en la instancia de Cloud Volumes ONTAP a través de un LIF dedicado.
-
Escucha. Utilizamos dos nodos para una combinación Prometheus-Grafana. Para generar cargas de trabajo, utilizamos un clúster separado de tres nodos que podía producir y consumir en este clúster de Kafka.
-
Almacenamiento. Utilizamos una instancia de Cloud Volumes ONTAP de par HA con un volumen AWS-EBS GP3 de 6 TB montado en la instancia. Luego, el volumen se exportó al broker de Kafka con un montaje NFS.
Configuraciones de evaluación comparativa de OpenMessage
-
Para un mejor rendimiento de NFS, necesitamos más conexiones de red entre el servidor NFS y el cliente NFS, que se pueden crear utilizando nconnect. Monte los volúmenes NFS en los nodos del agente con la opción nconnect ejecutando el siguiente comando:
[root@ip-172-30-0-121 ~]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38/xfsdefaults00 /dev/nvme1n1 /mnt/data-1 xfs defaults,noatime,nodiscard 0 0 /dev/nvme2n1 /mnt/data-2 xfs defaults,noatime,nodiscard 0 0 172.30.0.233:/kafka_aggr3_vol1 /kafka_aggr3_vol1 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol2 /kafka_aggr3_vol2 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol3 /kafka_aggr3_vol3 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol1 /kafka_aggr22_vol1 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol2 /kafka_aggr22_vol2 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol3 /kafka_aggr22_vol3 nfs defaults,nconnect=16 0 0 [root@ip-172-30-0-121 ~]# mount -a [root@ip-172-30-0-121 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 31G 0 31G 0% /dev tmpfs 31G 249M 31G 1% /run tmpfs 31G 0 31G 0% /sys/fs/cgroup /dev/nvme0n1p2 10G 2.8G 7.2G 28% / /dev/nvme1n1 2.3T 248G 2.1T 11% /mnt/data-1 /dev/nvme2n1 2.3T 245G 2.1T 11% /mnt/data-2 172.30.0.233:/kafka_aggr3_vol1 1.0T 12G 1013G 2% /kafka_aggr3_vol1 172.30.0.233:/kafka_aggr3_vol2 1.0T 5.5G 1019G 1% /kafka_aggr3_vol2 172.30.0.233:/kafka_aggr3_vol3 1.0T 8.9G 1016G 1% /kafka_aggr3_vol3 172.30.0.242:/kafka_aggr22_vol1 1.0T 7.3G 1017G 1% /kafka_aggr22_vol1 172.30.0.242:/kafka_aggr22_vol2 1.0T 6.9G 1018G 1% /kafka_aggr22_vol2 172.30.0.242:/kafka_aggr22_vol3 1.0T 5.9G 1019G 1% /kafka_aggr22_vol3 tmpfs 6.2G 0 6.2G 0% /run/user/1000 [root@ip-172-30-0-121 ~]#
-
Verifique las conexiones de red en Cloud Volumes ONTAP. El siguiente comando ONTAP se utiliza desde el único nodo Cloud Volumes ONTAP . El mismo paso se aplica al par Cloud Volumes ONTAP HA.
Last login time: 1/20/2023 00:16:29 kafka_nfs_cvo_sn::> network connections active show -service nfs* -fields remote-host node cid vserver remote-host ------------------- ---------- -------------------- ------------ kafka_nfs_cvo_sn-01 2315762628 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762629 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762630 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762631 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762632 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762633 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762634 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762635 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762636 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762637 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762639 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762640 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762641 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762642 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762643 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762644 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762645 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762646 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762647 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762648 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762649 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762650 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762651 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762652 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762653 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762656 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762657 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762658 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762659 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762660 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762661 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762662 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762663 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762664 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762665 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762666 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762667 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762668 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762669 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762670 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762671 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762672 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762673 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762674 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762676 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762677 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762678 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762679 svm_kafka_nfs_cvo_sn 172.30.0.223 48 entries were displayed. kafka_nfs_cvo_sn::>
-
Usamos el siguiente Kafka
server.propertiesen todos los brokers de Kafka para el par Cloud Volumes ONTAP HA. Ellog.dirsLa propiedad es diferente para cada corredor y las propiedades restantes son comunes para los corredores. Para el broker1, ellog.dirsEl valor es el siguiente:[root@ip-172-30-0-121 ~]# cat /opt/kafka/config/server.properties broker.id=0 advertised.listeners=PLAINTEXT://172.30.0.121:9092 #log.dirs=/mnt/data-1/d1,/mnt/data-1/d2,/mnt/data-1/d3,/mnt/data-2/d1,/mnt/data-2/d2,/mnt/data-2/d3 log.dirs=/kafka_aggr3_vol1/broker1,/kafka_aggr3_vol2/broker1,/kafka_aggr3_vol3/broker1,/kafka_aggr22_vol1/broker1,/kafka_aggr22_vol2/broker1,/kafka_aggr22_vol3/broker1 zookeeper.connect=172.30.0.12:2181,172.30.0.30:2181,172.30.0.178:2181 num.network.threads=64 num.io.threads=64 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 replica.fetch.max.bytes=524288000 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 [root@ip-172-30-0-121 ~]#
-
Para el broker2, el
log.dirsEl valor de la propiedad es el siguiente:log.dirs=/kafka_aggr3_vol1/broker2,/kafka_aggr3_vol2/broker2,/kafka_aggr3_vol3/broker2,/kafka_aggr22_vol1/broker2,/kafka_aggr22_vol2/broker2,/kafka_aggr22_vol3/broker2
-
Para el broker3, el
log.dirsEl valor de la propiedad es el siguiente:log.dirs=/kafka_aggr3_vol1/broker3,/kafka_aggr3_vol2/broker3,/kafka_aggr3_vol3/broker3,/kafka_aggr22_vol1/broker3,/kafka_aggr22_vol2/broker3,/kafka_aggr22_vol3/broker3
-
-
Para el nodo único de Cloud Volumes ONTAP , Kafka
servers.propertieses lo mismo que para el par Cloud Volumes ONTAP HA excepto por ellog.dirspropiedad.-
Para el broker1, el
log.dirsEl valor es el siguiente:log.dirs=/kafka_aggr2_vol1/broker1,/kafka_aggr2_vol2/broker1,/kafka_aggr2_vol3/broker1,/kafka_aggr2_vol4/broker1,/kafka_aggr2_vol5/broker1,/kafka_aggr2_vol6/broker1
-
Para el broker2, el
log.dirsEl valor es el siguiente:log.dirs=/kafka_aggr2_vol1/broker2,/kafka_aggr2_vol2/broker2,/kafka_aggr2_vol3/broker2,/kafka_aggr2_vol4/broker2,/kafka_aggr2_vol5/broker2,/kafka_aggr2_vol6/broker2
-
Para el broker3, el
log.dirsEl valor de la propiedad es el siguiente:log.dirs=/kafka_aggr2_vol1/broker3,/kafka_aggr2_vol2/broker3,/kafka_aggr2_vol3/broker3,/kafka_aggr2_vol4/broker3,/kafka_aggr2_vol5/broker3,/kafka_aggr2_vol6/broker3
-
-
La carga de trabajo en la OMB está configurada con las siguientes propiedades:
(/opt/benchmark/workloads/1-topic-100-partitions-1kb.yaml).topics: 4 partitionsPerTopic: 100 messageSize: 32768 useRandomizedPayloads: true randomBytesRatio: 0.5 randomizedPayloadPoolSize: 100 subscriptionsPerTopic: 1 consumerPerSubscription: 80 producersPerTopic: 40 producerRate: 1000000 consumerBacklogSizeGB: 0 testDurationMinutes: 5
El
messageSizePuede variar para cada caso de uso. En nuestra prueba de rendimiento, utilizamos 3K.Utilizamos dos controladores diferentes, Sync o Throughput, de OMB para generar la carga de trabajo en el clúster de Kafka.
-
El archivo yaml utilizado para las propiedades del controlador de sincronización es el siguiente
(/opt/benchmark/driver- kafka/kafka-sync.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 flush.messages=1 flush.ms=0 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
El archivo yaml utilizado para las propiedades del controlador de rendimiento es el siguiente
(/opt/benchmark/driver- kafka/kafka-throughput.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 default.api.timeout.ms=1200000 request.timeout.ms=1200000 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Metodología de pruebas
-
Se aprovisionó un clúster de Kafka según la especificación descrita anteriormente utilizando Terraform y Ansible. Terraform se utiliza para construir la infraestructura utilizando instancias de AWS para el clúster de Kafka y Ansible construye el clúster de Kafka en ellas.
-
Se activó una carga de trabajo OMB con la configuración de carga de trabajo descrita anteriormente y el controlador de sincronización.
Sudo bin/benchmark –drivers driver-kafka/kafka- sync.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Se activó otra carga de trabajo con el controlador de rendimiento con la misma configuración de carga de trabajo.
sudo bin/benchmark –drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
Observación
Se utilizaron dos tipos diferentes de controladores para generar cargas de trabajo para evaluar el rendimiento de una instancia de Kafka que se ejecuta en NFS. La diferencia entre los controladores es la propiedad de vaciado del registro.
Para un par de Cloud Volumes ONTAP HA:
-
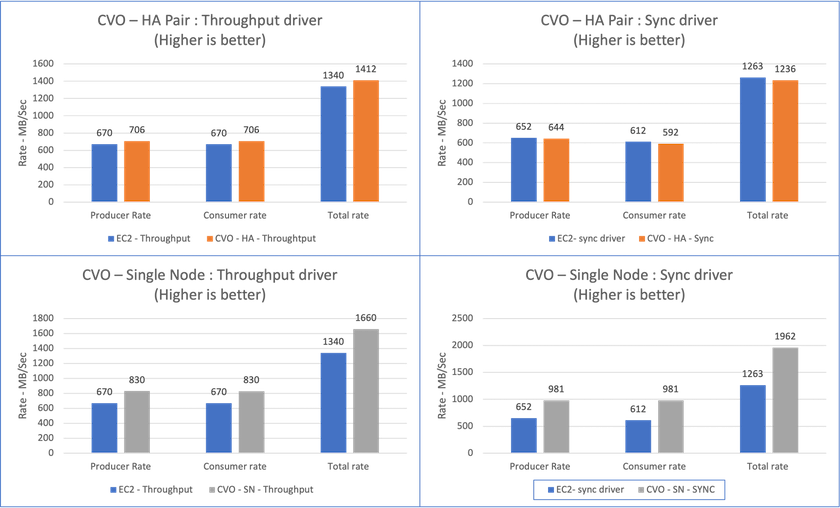
Rendimiento total generado consistentemente por el controlador de sincronización: ~1236 MBps.
-
Rendimiento total generado para el controlador de rendimiento: pico ~1412 MBps.
Para un solo nodo de Cloud Volumes ONTAP :
-
Rendimiento total generado consistentemente por el controlador de sincronización: ~ 1962 MBps.
-
Rendimiento total generado por el controlador de rendimiento: pico ~1660 MBps
El controlador de sincronización puede generar un rendimiento constante a medida que los registros se vacían en el disco instantáneamente, mientras que el controlador de rendimiento genera ráfagas de rendimiento a medida que los registros se envían al disco en forma masiva.
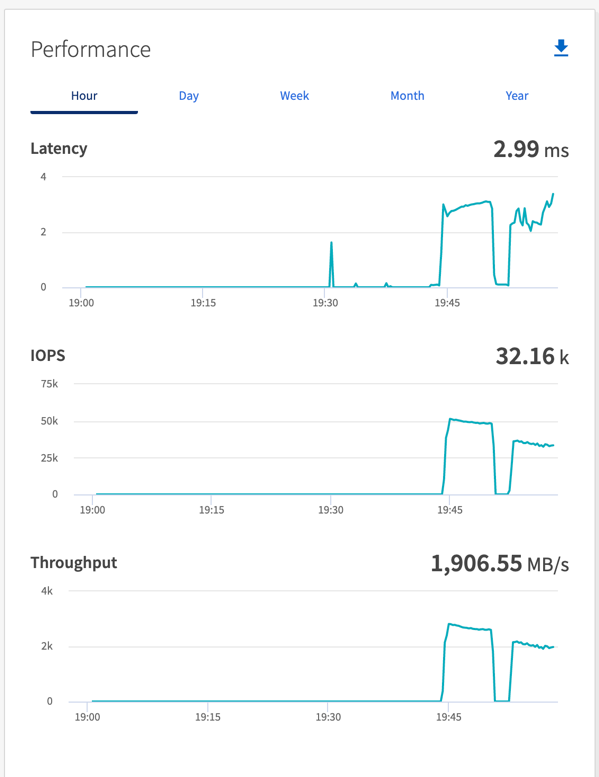
Estos números de rendimiento se generan para la configuración de AWS dada. Para requisitos de mayor rendimiento, los tipos de instancias se pueden escalar y ajustar aún más para obtener mejores números de rendimiento. El rendimiento total o tasa total es la combinación de la tasa del productor y del consumidor.
Asegúrese de verificar el rendimiento del almacenamiento al realizar evaluaciones comparativas del controlador de sincronización o del rendimiento.