Validación funcional: Solución para un cambio de nombre tonto
 Sugerir cambios
Sugerir cambios
Para la validación funcional, demostramos que un clúster de Kafka con un montaje NFSv3 para almacenamiento no puede realizar operaciones de Kafka como la redistribución de particiones, mientras que otro clúster montado en NFSv4 con la solución puede realizar las mismas operaciones sin interrupciones.
Configuración de validación
La configuración se ejecuta en AWS. La siguiente tabla muestra los diferentes componentes de la plataforma y la configuración ambiental utilizados para la validación.
| Componente de plataforma | Configuración del entorno |
|---|---|
Plataforma Confluent versión 7.2.1 |
|
Sistema operativo en todos los nodos |
RHEL8.7 o posterior |
Instancia NetApp Cloud Volumes ONTAP |
Instancia de un solo nodo – M5.2xLarge |
La siguiente figura muestra la configuración arquitectónica para esta solución.
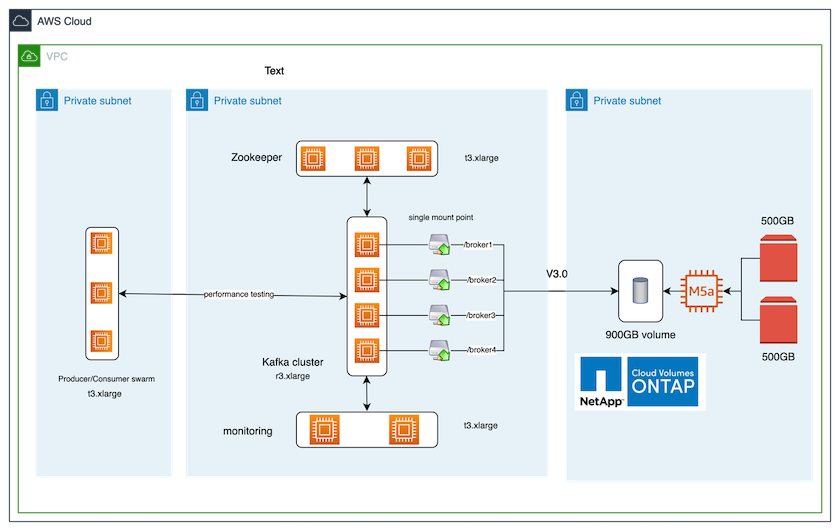
Flujo arquitectónico
-
Calcular. Utilizamos un clúster Kafka de cuatro nodos con un conjunto Zookeeper de tres nodos ejecutándose en servidores dedicados.
-
Escucha. Utilizamos dos nodos para una combinación Prometheus-Grafana.
-
Carga de trabajo. Para generar cargas de trabajo, utilizamos un clúster separado de tres nodos que puede producir y consumir desde este clúster de Kafka.
-
Almacenamiento. Utilizamos una instancia de NetApp Cloud Volumes ONTAP de un solo nodo con dos volúmenes AWS-EBS GP2 de 500 GB conectados a la instancia. Luego, estos volúmenes se expusieron al clúster de Kafka como un único volumen NFSv4.1 a través de un LIF.
Se eligieron las propiedades predeterminadas de Kafka para todos los servidores. Lo mismo se hizo con el enjambre de cuidadores del zoológico.
Metodología de pruebas
-
Actualizar
-is-preserve-unlink-enabled trueAl volumen de Kafka, como sigue:aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
Se crearon dos clústeres de Kafka similares con la siguiente diferencia:
-
Grupo 1. El servidor backend NFS v4.1 que ejecutaba ONTAP versión 9.12.1 lista para producción estaba alojado en una instancia CVO de NetApp . Se instalaron RHEL 8.7/RHEL 9.1 en los brokers.
-
Grupo 2. El servidor NFS backend era un servidor NFSv3 Linux genérico creado manualmente.
-
-
Se creó un tema de demostración en ambos clústeres de Kafka.
Grupo 1:

Grupo 2:

-
Se cargaron datos en estos temas recién creados para ambos clústeres. Esto se hizo utilizando el kit de herramientas de prueba de rendimiento del productor que viene en el paquete predeterminado de Kafka:
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
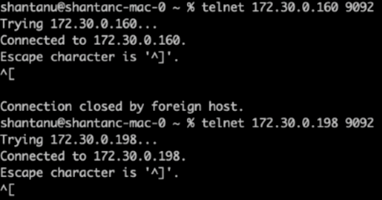
Se realizó una comprobación del estado del broker-1 para cada uno de los clústeres mediante telnet:
-
Telnet
172.30.0.160 9092 -
Telnet
172.30.0.198 9092En la siguiente captura de pantalla se muestra una verificación de estado exitosa de los corredores en ambos clústeres:
-
-
Para activar la condición de error que provoca que los clústeres de Kafka que usan volúmenes de almacenamiento NFSv3 se bloqueen, iniciamos el proceso de reasignación de particiones en ambos clústeres. La reasignación de particiones se realizó utilizando
kafka-reassign-partitions.sh. El proceso detallado es el siguiente:-
Para reasignar las particiones de un tema en un clúster de Kafka, generamos el JSON de configuración de reasignación propuesto (esto se realizó para ambos clústeres).
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
Luego, el JSON de reasignación generado se guardó en
/tmp/reassignment- file.json. -
El proceso de reasignación de partición real se activó mediante el siguiente comando:
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
Después de unos minutos, cuando se completó la reasignación, otra verificación del estado de los intermediarios mostró que el clúster que usaba volúmenes de almacenamiento NFSv3 se había topado con un problema de cambio de nombre tonto y se había bloqueado, mientras que el clúster 1 que usaba volúmenes de almacenamiento NetApp ONTAP NFSv4.1 con la solución continuó con sus operaciones sin interrupciones.
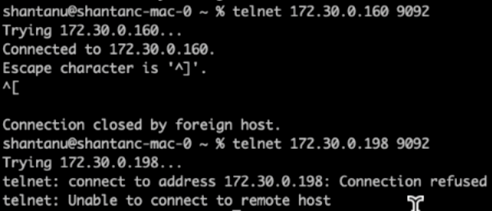
-
Cluster1-Broker-1 está activo.
-
Cluster2-broker-1 está muerto.
-
-
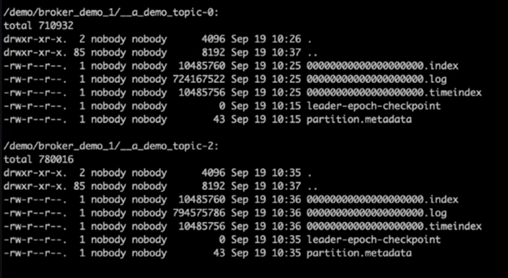
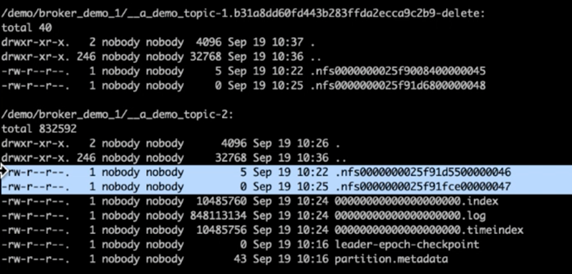
Al verificar los directorios de registro de Kafka, quedó claro que el Clúster 1 que usaba volúmenes de almacenamiento NetApp ONTAP NFSv4.1 con la corrección tenía una asignación de partición limpia, mientras que el Clúster 2 que usaba almacenamiento NFSv3 genérico no la tenía debido a problemas de cambio de nombre tontos, que provocaron el bloqueo. La siguiente imagen muestra el reequilibrio de la partición del Clúster 2, lo que provocó un problema de cambio de nombre tonto en el almacenamiento NFSv3.
La siguiente imagen muestra un reequilibrio de partición limpio del Clúster 1 utilizando almacenamiento NetApp NFSv4.1.