¿Por qué NetApp NFS para cargas de trabajo de Kafka?
 Sugerir cambios
Sugerir cambios
Ahora que existe una solución para el problema del cambio de nombre tonto en el almacenamiento NFS con Kafka, puede crear implementaciones sólidas que aprovechen el almacenamiento NetApp ONTAP para su carga de trabajo de Kafka. Esto no solo reduce significativamente los gastos operativos, sino que también aporta los siguientes beneficios a sus clústeres de Kafka:
-
Utilización reducida de CPU en los brókers de Kafka. El uso de almacenamiento desagregado de NetApp ONTAP separa las operaciones de E/S de disco del agente y, de este modo, reduce su huella de CPU.
-
Tiempo de recuperación del corredor más rápido. Dado que el almacenamiento desagregado de NetApp ONTAP se comparte entre los nodos del agente de Kafka, una nueva instancia de cómputo puede reemplazar a un agente defectuoso en cualquier momento en una fracción del tiempo en comparación con las implementaciones convencionales de Kafka sin reconstruir los datos.
-
Eficiencia de almacenamiento. Como la capa de almacenamiento de la aplicación ahora se aprovisiona a través de NetApp ONTAP, los clientes pueden aprovechar todos los beneficios de eficiencia de almacenamiento que viene con ONTAP, como compresión de datos en línea, deduplicación y compactación.
Estos beneficios fueron probados y validados en casos de prueba que discutimos en detalle en esta sección.
Uso reducido de la CPU en el bróker de Kafka
Descubrimos que la utilización general de la CPU es menor que la de su contraparte DAS cuando ejecutamos cargas de trabajo similares en dos clústeres de Kafka separados que eran idénticos en sus especificaciones técnicas pero diferían en sus tecnologías de almacenamiento. No solo la utilización general de la CPU es menor cuando el clúster de Kafka usa almacenamiento ONTAP , sino que el aumento en la utilización de la CPU demostró un gradiente más suave que en un clúster de Kafka basado en DAS.
Configuración arquitectónica
La siguiente tabla muestra la configuración ambiental utilizada para demostrar una utilización reducida de la CPU.
| Componente de plataforma | Configuración del entorno |
|---|---|
Herramienta de evaluación comparativa de Kafka 3.2.3: OpenMessaging |
|
Sistema operativo en todos los nodos |
RHEL 8.7 o posterior |
Instancia NetApp Cloud Volumes ONTAP |
Instancia de nodo único – M5.2xLarge |
Herramienta de evaluación comparativa
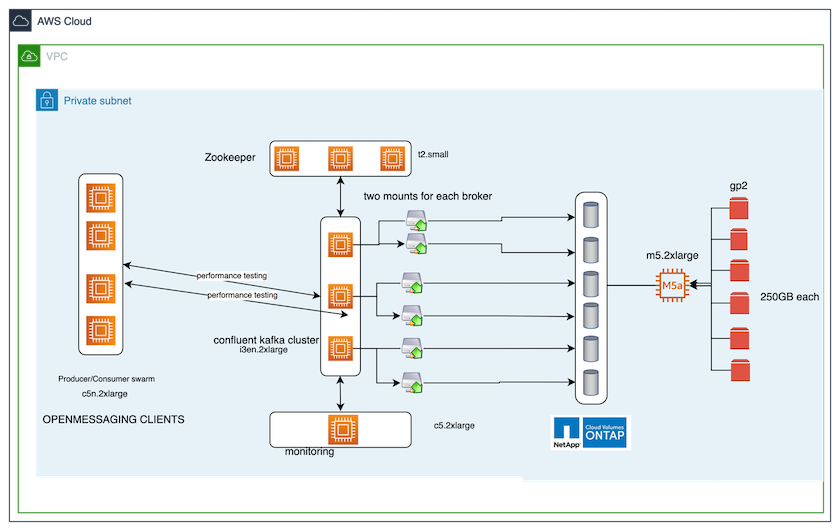
La herramienta de evaluación comparativa utilizada en este caso de prueba es la "Mensajería abierta" estructura. OpenMessaging es neutral respecto de proveedores e independiente del lenguaje; proporciona pautas industriales para finanzas, comercio electrónico, IoT y big data; y ayuda a desarrollar aplicaciones de mensajería y transmisión en sistemas y plataformas heterogéneos. La siguiente figura muestra la interacción de los clientes de OpenMessaging con un clúster de Kafka.
-
Calcular. Utilizamos un clúster Kafka de tres nodos con un conjunto Zookeeper de tres nodos ejecutándose en servidores dedicados. Cada agente tenía dos puntos de montaje NFSv4.1 en un solo volumen en la instancia CVO de NetApp a través de un LIF dedicado.
-
Escucha. Utilizamos dos nodos para una combinación Prometheus-Grafana. Para generar cargas de trabajo, tenemos un clúster separado de tres nodos que puede producir y consumir desde este clúster de Kafka.
-
Almacenamiento. Utilizamos una instancia de NetApp Cloud Volumes ONTAP de un solo nodo con seis volúmenes AWS-EBS GP2 de 250 GB montados en la instancia. Luego, estos volúmenes se expusieron al clúster de Kafka como seis volúmenes NFSv4.1 a través de LIF dedicados.
-
Configuración. Los dos elementos configurables en este caso de prueba fueron los agentes de Kafka y las cargas de trabajo de OpenMessaging.
-
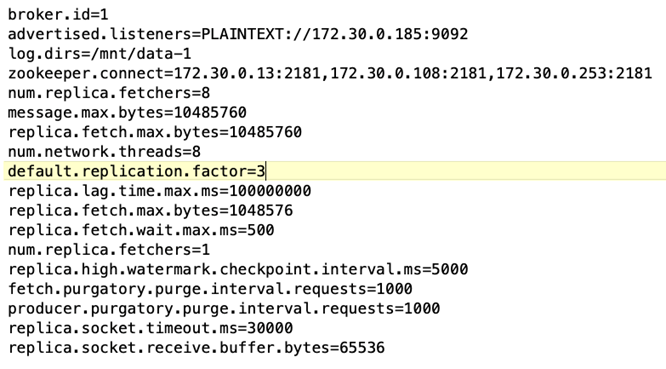
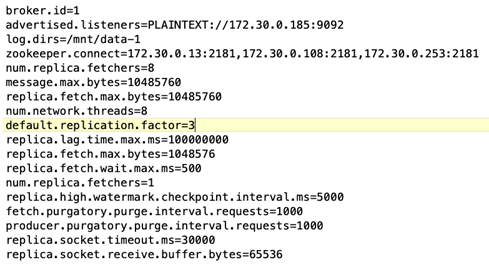
Configuración del corredor. Se seleccionaron las siguientes especificaciones para los corredores de Kafka. Utilizamos un factor de replicación de 3 para todas las mediciones, como se destaca a continuación.
-
-
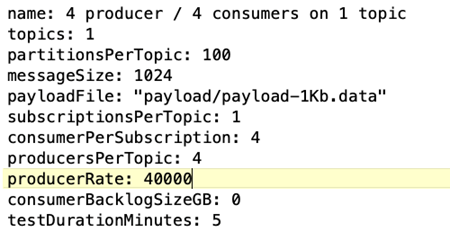
Configuración de carga de trabajo de referencia de OpenMessaging (OMB). Se proporcionaron las siguientes especificaciones: Especificamos una tasa de productor objetivo, resaltada a continuación.
Metodología de pruebas
-
Se crearon dos clústeres similares, cada uno con su propio conjunto de enjambres de clústeres de evaluación comparativa.
-
Grupo 1. Clúster Kafka basado en NFS.
-
Grupo 2. Clúster Kafka basado en DAS.
-
-
Usando un comando OpenMessaging, se activaron cargas de trabajo similares en cada clúster.
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
La configuración de la tasa de producción se incrementó en cuatro iteraciones y la utilización de la CPU se registró con Grafana. La tasa de producción se fijó en los siguientes niveles:
-
10.000
-
40.000
-
80.000
-
100.000
-
Observación
Hay dos beneficios principales de usar almacenamiento NFS de NetApp con Kafka:
-
Puede reducir el uso de la CPU en casi un tercio. El uso general de la CPU bajo cargas de trabajo similares fue menor para NFS en comparación con los SSD DAS; los ahorros varían del 5 % para tasas de producción más bajas al 32 % para tasas de producción más altas.
-
Una reducción de tres veces en la deriva de utilización de la CPU a tasas de producción más altas. Como era de esperar, hubo una tendencia ascendente en el aumento de la utilización de la CPU a medida que aumentaron las tasas de producción. Sin embargo, la utilización de la CPU en los brókers de Kafka que usan DAS aumentó del 31 % para la tasa de producción más baja al 70 % para la tasa de producción más alta, un aumento del 39 %. Sin embargo, con un backend de almacenamiento NFS, la utilización de la CPU aumentó del 26% al 38%, un aumento del 12%.
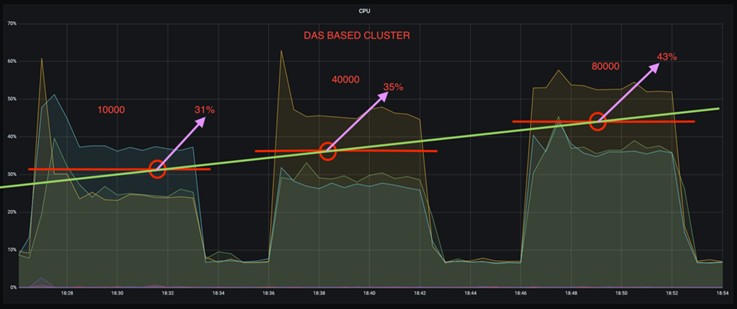
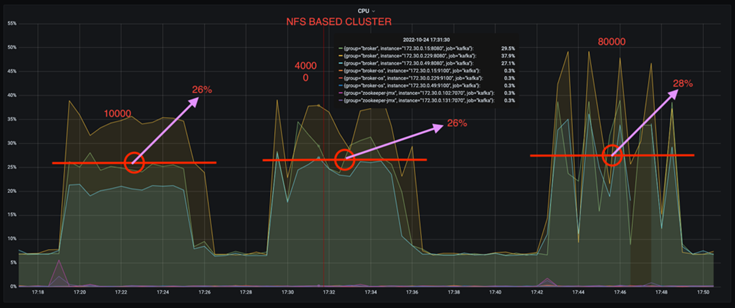
Además, con 100.000 mensajes, DAS muestra una mayor utilización de la CPU que un clúster NFS.
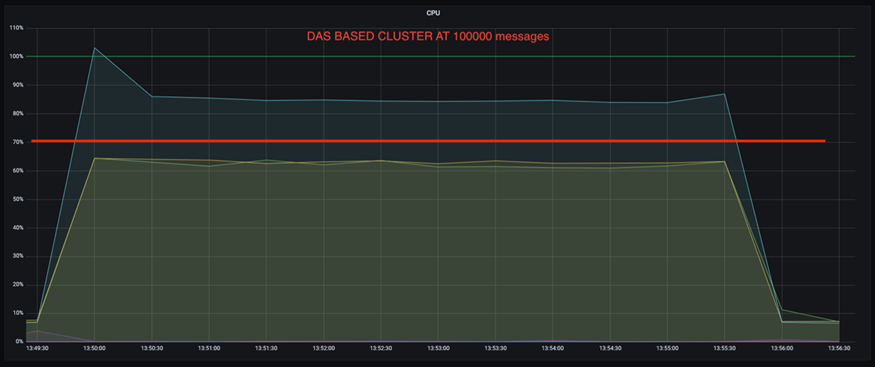
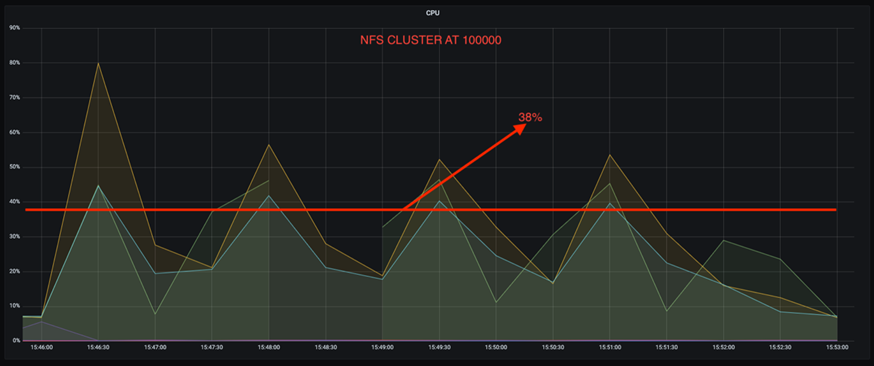
Recuperación más rápida del corredor
Descubrimos que los agentes de Kafka se recuperan más rápido cuando utilizan almacenamiento NFS compartido de NetApp . Cuando un broker falla en un clúster de Kafka, este broker puede ser reemplazado por un broker en buen estado con el mismo ID de broker. Al realizar este caso de prueba, descubrimos que, en el caso de un clúster de Kafka basado en DAS, el clúster reconstruye los datos en un agente en buen estado recién agregado, lo que consume mucho tiempo. En el caso de un clúster Kafka basado en NFS de NetApp , el agente de reemplazo continúa leyendo datos del directorio de registro anterior y se recupera mucho más rápido.
Configuración arquitectónica
La siguiente tabla muestra la configuración ambiental para un clúster de Kafka que utiliza NAS.
| Componente de plataforma | Configuración del entorno |
|---|---|
Kafka 3.2.3 |
|
Sistema operativo en todos los nodos |
RHEL8.7 o posterior |
Instancia NetApp Cloud Volumes ONTAP |
Instancia de un solo nodo – M5.2xLarge |
La siguiente figura muestra la arquitectura de un clúster de Kafka basado en NAS.
-
Calcular. Un clúster de Kafka de tres nodos con un conjunto Zookeeper de tres nodos que se ejecuta en servidores dedicados. Cada agente tiene dos puntos de montaje NFS en un solo volumen en la instancia CVO de NetApp a través de un LIF dedicado.
-
Escucha. Dos nodos para una combinación Prometheus-Grafana. Para generar cargas de trabajo, utilizamos un clúster separado de tres nodos que puede producir y consumir en este clúster de Kafka.
-
Almacenamiento. Una instancia de volúmenes NetApp Cloud ONTAP de un solo nodo con seis volúmenes AWS-EBS GP2 de 250 GB montados en la instancia. Luego, estos volúmenes se exponen al clúster de Kafka como seis volúmenes NFS a través de LIF dedicados.
-
Configuración del broker. El único elemento configurable en este caso de prueba son los brokers de Kafka. Se seleccionaron las siguientes especificaciones para los corredores de Kafka. El
replica.lag.time.mx.msse establece en un valor alto porque esto determina qué tan rápido se saca un nodo particular de la lista ISR. Cuando cambia entre nodos defectuosos y saludables, no desea que ese ID de agente se excluya de la lista de ISR.
Metodología de pruebas
-
Se crearon dos clústeres similares:
-
Un clúster confluente basado en EC2.
-
Un clúster confluente basado en NFS de NetApp .
-
-
Se creó un nodo de Kafka en espera con una configuración idéntica a los nodos del clúster de Kafka original.
-
En cada uno de los clústeres, se creó un tema de muestra y se completaron aproximadamente 110 GB de datos en cada uno de los corredores.
-
Clúster basado en EC2. Un directorio de datos del corredor de Kafka está asignado a
/mnt/data-2(En la siguiente figura, Broker-1 del cluster1 [terminal izquierda]). -
* Clúster basado en NFS de NetApp .* Un directorio de datos del agente de Kafka está montado en el punto NFS
/mnt/data(En la siguiente figura, Broker-1 del cluster2 [terminal derecha]).
-
-
En cada uno de los clústeres, se finalizó Broker-1 para desencadenar un proceso de recuperación de broker fallido.
-
Una vez finalizado el broker, su dirección IP se asignó como IP secundaria al broker en espera. Esto fue necesario porque un bróker en un clúster de Kafka se identifica por lo siguiente:
-
Dirección IP. Se asigna reasignando la IP del agente fallido al agente en espera.
-
Identificación del corredor. Esto se configuró en el agente en espera
server.properties.
-
-
Tras la asignación de IP, se inició el servicio Kafka en el bróker en espera.
-
Después de un tiempo, se extrajeron los registros del servidor para verificar el tiempo que tomó generar datos en el nodo de reemplazo en el clúster.
Observación
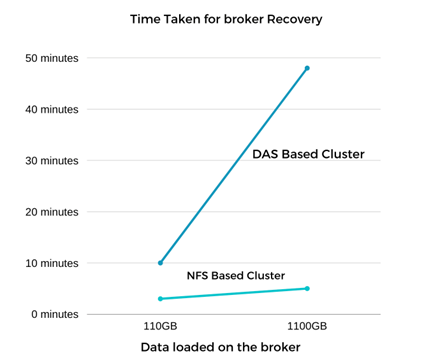
La recuperación del corredor de Kafka fue casi nueve veces más rápida. Se descubrió que el tiempo necesario para recuperar un nodo de agente fallido era significativamente más rápido cuando se usaba almacenamiento compartido NFS de NetApp en comparación con el uso de SSD DAS en un clúster de Kafka. Para 1 TB de datos de temas, el tiempo de recuperación de un clúster basado en DAS fue de 48 minutos, en comparación con menos de 5 minutos para un clúster Kafka basado en NetApp-NFS.
Observamos que el clúster basado en EC2 tardó 10 minutos en reconstruir los 110 GB de datos en el nuevo nodo del agente, mientras que el clúster basado en NFS completó la recuperación en 3 minutos. También observamos en los registros que las compensaciones del consumidor para las particiones de EC2 eran 0, mientras que, en el clúster NFS, las compensaciones del consumidor se tomaron del agente anterior.
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
Clúster basado en DAS
-
El nodo de respaldo se inició a las 08:55:53,730.

-
El proceso de reconstrucción de datos finalizó a las 09:05:24.860. El procesamiento de 110 GB de datos requirió aproximadamente 10 minutos.

Clúster basado en NFS
-
El nodo de respaldo se inició a las 09:39:17,213. La entrada del registro de inicio se resalta a continuación.

-
El proceso de reconstrucción de datos finalizó a las 09:42:29,115. El procesamiento de 110 GB de datos requirió aproximadamente 3 minutos.

La prueba se repitió para los corredores que contenían alrededor de 1 TB de datos, lo que tomó aproximadamente 48 minutos para DAS y 3 minutos para NFS. Los resultados se muestran en el siguiente gráfico.
Eficiencia de almacenamiento
Debido a que la capa de almacenamiento del clúster Kafka se aprovisionó a través de NetApp ONTAP, obtuvimos todas las capacidades de eficiencia de almacenamiento de ONTAP. Esto se probó generando una cantidad significativa de datos en un clúster de Kafka con almacenamiento NFS aprovisionado en Cloud Volumes ONTAP. Pudimos ver que hubo una reducción de espacio significativa debido a las capacidades de ONTAP .
Configuración arquitectónica
La siguiente tabla muestra la configuración ambiental para un clúster de Kafka que utiliza NAS.
| Componente de plataforma | Configuración del entorno |
|---|---|
Kafka 3.2.3 |
|
Sistema operativo en todos los nodos |
RHEL8.7 o posterior |
Instancia NetApp Cloud Volumes ONTAP |
Instancia de nodo único – M5.2xLarge |
La siguiente figura muestra la arquitectura de un clúster de Kafka basado en NAS.
-
Calcular. Utilizamos un clúster Kafka de tres nodos con un conjunto Zookeeper de tres nodos ejecutándose en servidores dedicados. Cada agente tenía dos puntos de montaje NFS en un solo volumen en la instancia CVO de NetApp a través de un LIF dedicado.
-
Escucha. Utilizamos dos nodos para una combinación Prometheus-Grafana. Para generar cargas de trabajo, utilizamos un clúster separado de tres nodos que podía producir y consumir en este clúster de Kafka.
-
Almacenamiento. Utilizamos una instancia de NetApp Cloud Volumes ONTAP de un solo nodo con seis volúmenes AWS-EBS GP2 de 250 GB montados en la instancia. Luego, estos volúmenes se expusieron al clúster de Kafka como seis volúmenes NFS a través de LIF dedicados.
-
Configuración. Los elementos configurables en este caso de prueba fueron los brokers de Kafka.
La compresión se desactivó en el extremo del productor, lo que permitió a los productores generar un alto rendimiento. La eficiencia del almacenamiento, en cambio, quedó a cargo de la capa de cómputo.
Metodología de pruebas
-
Se aprovisionó un clúster de Kafka con las especificaciones mencionadas anteriormente.
-
En el clúster, se produjeron alrededor de 350 GB de datos utilizando la herramienta OpenMessaging Benchmarking.
-
Una vez completada la carga de trabajo, se recopilaron las estadísticas de eficiencia de almacenamiento utilizando ONTAP System Manager y la CLI.
Observación
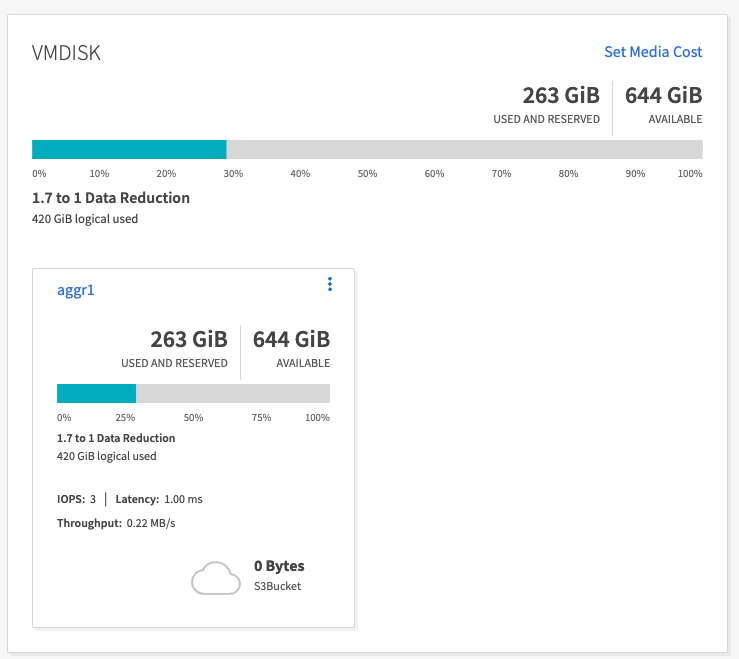
En el caso de los datos generados con la herramienta OMB, observamos un ahorro de espacio de aproximadamente un 33 % con una relación de eficiencia de almacenamiento de 1,70:1. Como se ve en las siguientes figuras, el espacio lógico utilizado por los datos producidos fue de 420,3 GB y el espacio físico utilizado para almacenar los datos fue de 281,7 GB.