

Descripción general de las soluciones Spark de NetApp
 Sugerir cambios
Sugerir cambios
NetApp tiene tres carteras de almacenamiento: FAS/ AFF, E-Series y Cloud Volumes ONTAP. Hemos validado AFF y el sistema de almacenamiento E-Series con ONTAP para soluciones Hadoop con Apache Spark.
La estructura de datos impulsada por NetApp integra servicios y aplicaciones de gestión de datos (bloques de construcción) para el acceso, control, protección y seguridad de los datos, como se muestra en la siguiente figura.
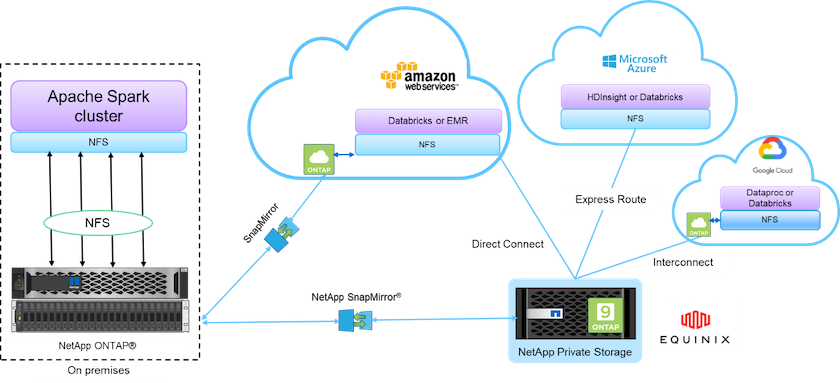
Los componentes básicos de la figura anterior incluyen:
-
Acceso directo a NFS de NetApp . Proporciona los últimos clústeres Hadoop y Spark con acceso directo a volúmenes NFS de NetApp sin requisitos de software o controladores adicionales.
-
* Cloud Volumes ONTAP NetApp Cloud ONTAP y Google Cloud NetApp Volumes.* Almacenamiento conectado definido por software basado en ONTAP que se ejecuta en Amazon Web Services (AWS) o Azure NetApp Files (ANF) en los servicios de nube de Microsoft Azure.
-
Tecnología NetApp SnapMirror . Proporciona capacidades de protección de datos entre las instancias locales y las de ONTAP Cloud o NPS.
-
Proveedores de servicios en la nube. Estos proveedores incluyen AWS, Microsoft Azure, Google Cloud e IBM Cloud.
-
PaaS. Servicios de análisis basados en la nube como Amazon Elastic MapReduce (EMR) y Databricks en AWS, así como Microsoft Azure HDInsight y Azure Databricks.
La siguiente figura muestra la solución Spark con almacenamiento NetApp .
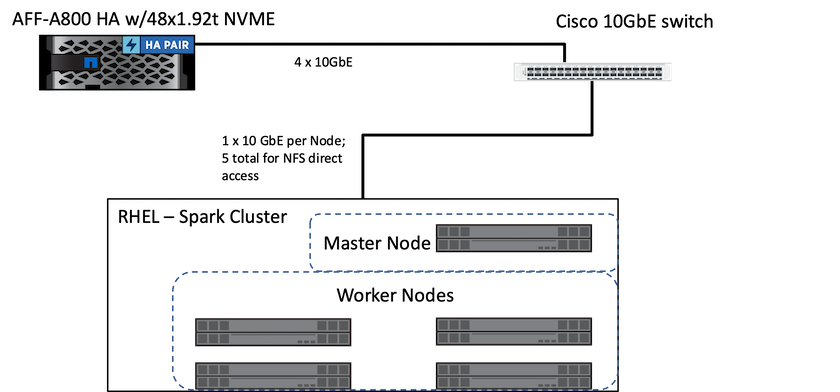
La solución ONTAP Spark utiliza el protocolo de acceso directo NFS de NetApp para análisis locales y flujos de trabajo de IA, ML y DL mediante el acceso a datos de producción existentes. Los datos de producción disponibles para los nodos Hadoop se exportan para realizar trabajos de análisis y de inteligencia artificial, aprendizaje automático y aprendizaje automático en el lugar. Puede acceder a los datos para procesarlos en los nodos Hadoop con acceso directo a NetApp NFS o sin él. En Spark con el independiente o yarn Administrador de clústeres, puede configurar un volumen NFS mediante file://<target_volume> . Validamos tres casos de uso con diferentes conjuntos de datos. Los detalles de estas validaciones se presentan en la sección "Resultados de las pruebas". (referencia cruzada)
La siguiente figura muestra el posicionamiento del almacenamiento Apache Spark/Hadoop de NetApp .
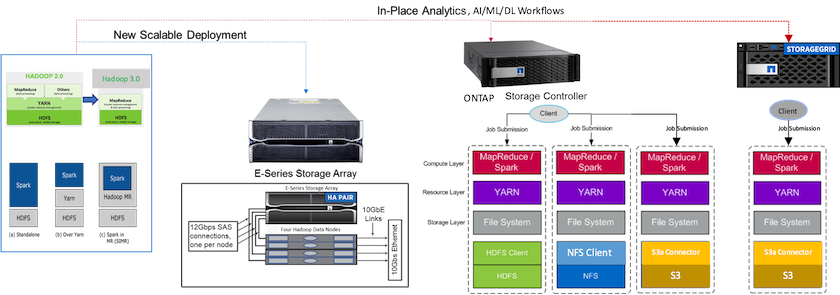
Identificamos las características únicas de la solución E-Series Spark, la solución AFF/ FAS ONTAP Spark y la solución StorageGRID Spark, y realizamos pruebas y validaciones detalladas. Con base en nuestras observaciones, NetApp recomienda la solución E-Series para instalaciones nuevas y nuevas implementaciones escalables, y la solución AFF/ FAS para análisis locales, IA, ML y cargas de trabajo de DL utilizando datos NFS existentes, y StorageGRID para IA, ML y DL y análisis de datos modernos cuando se requiere almacenamiento de objetos.
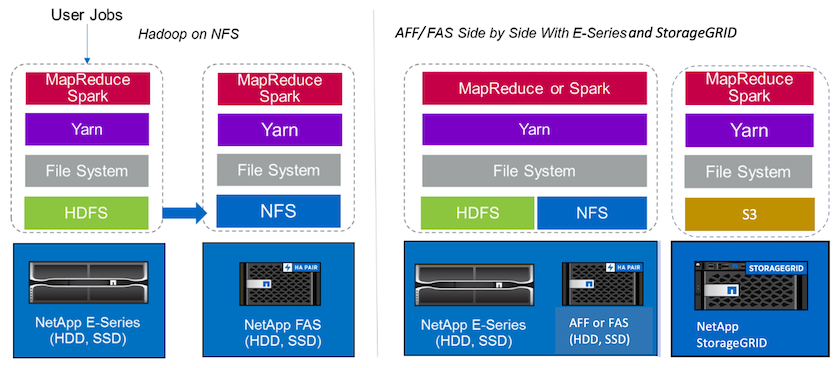
Un lago de datos es un repositorio de almacenamiento para grandes conjuntos de datos en formato nativo que pueden usarse para trabajos de análisis, inteligencia artificial, aprendizaje automático y aprendizaje automático. Creamos un repositorio de lago de datos para las soluciones Spark E-Series, AFF/ FAS y StorageGRID SG6060. El sistema E-Series proporciona acceso HDFS al clúster Hadoop Spark, mientras que se accede a los datos de producción existentes a través del protocolo de acceso directo NFS al clúster Hadoop. Para los conjuntos de datos que residen en el almacenamiento de objetos, NetApp StorageGRID proporciona acceso seguro S3 y S3a.