

Resultados de la prueba
 Sugerir cambios
Sugerir cambios
Se realizaron multitud de pruebas para evaluar el rendimiento de la arquitectura propuesta.
Hay seis cargas de trabajo diferentes (clasificación de imágenes, detección de objetos [pequeños], detección de objetos [grandes], imágenes médicas, conversión de voz a texto y procesamiento del lenguaje natural [PLN]), que puede ejecutar en tres escenarios diferentes: sin conexión, transmisión única y transmisión múltiple.

|
El último escenario se implementa solo para la clasificación de imágenes y la detección de objetos. |
Esto da 15 cargas de trabajo posibles, todas ellas probadas en tres configuraciones diferentes:
-
Servidor único/almacenamiento local
-
Almacenamiento en red/servidor único
-
Almacenamiento en red/multiservidor
Los resultados se describen en las siguientes secciones.
Inferencia de IA en un escenario fuera de línea para AFF
En este escenario, todos los datos estaban disponibles en el servidor y se midió el tiempo que tardaba en procesar todas las muestras. Informamos los anchos de banda en muestras por segundo como resultados de las pruebas. Cuando se utilizó más de un servidor de cómputo, informamos el ancho de banda total sumado entre todos los servidores. Los resultados para los tres casos de uso se muestran en la siguiente figura. Para el caso de dos servidores, informamos el ancho de banda combinado de ambos servidores.

Los resultados muestran que el almacenamiento en red no afecta negativamente el rendimiento: el cambio es mínimo y, para algunas tareas, no se encuentra ninguno. Al agregar el segundo servidor, el ancho de banda total se duplica exactamente o, en el peor de los casos, el cambio es inferior al 1 %.
Inferencia de IA en un escenario de flujo único para AFF
Este punto de referencia mide la latencia. Para el caso de servidores computacionales múltiples, informamos la latencia promedio. Los resultados para el conjunto de tareas se muestran en la siguiente figura. Para el caso de dos servidores, informamos la latencia promedio de ambos servidores.

Los resultados muestran nuevamente que el almacenamiento en red es suficiente para manejar las tareas. La diferencia entre el almacenamiento local y el almacenamiento en red en el caso de un servidor es mínima o nula. De manera similar, cuando dos servidores usan el mismo almacenamiento, la latencia en ambos servidores permanece igual o cambia en una cantidad muy pequeña.
Inferencia de IA en un escenario multisecuencia para AFF
En este caso, el resultado es la cantidad de transmisiones que el sistema puede manejar mientras satisface la restricción de QoS. Por tanto, el resultado es siempre un número entero. Para más de un servidor, informamos el número total de transmisiones sumadas en todos los servidores. No todas las cargas de trabajo admiten este escenario, pero hemos ejecutado las que sí lo hacen. Los resultados de nuestras pruebas se resumen en la siguiente figura. Para el caso de dos servidores, informamos el número combinado de transmisiones de ambos servidores.
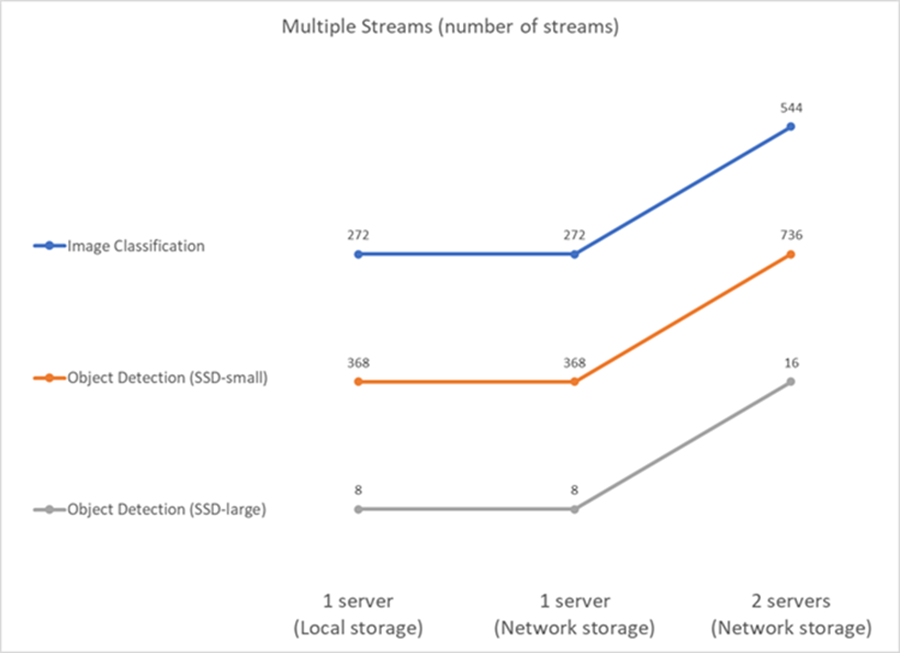
Los resultados muestran un rendimiento perfecto de la configuración: el almacenamiento local y en red dan los mismos resultados y agregar el segundo servidor duplica la cantidad de transmisiones que la configuración propuesta puede manejar.
Resultados de la prueba de EF
Se realizaron multitud de pruebas para evaluar el rendimiento de la arquitectura propuesta. Hay seis cargas de trabajo diferentes (clasificación de imágenes, detección de objetos [pequeños], detección de objetos [grandes], imágenes médicas, conversión de voz a texto y procesamiento del lenguaje natural [PLN]), que se ejecutaron en dos escenarios diferentes: fuera de línea y en flujo único. Los resultados se describen en las siguientes secciones.
Inferencia de IA en un escenario fuera de línea para EF
En este escenario, todos los datos estaban disponibles en el servidor y se midió el tiempo que tardaba en procesar todas las muestras. Informamos los anchos de banda en muestras por segundo como resultados de las pruebas. Para ejecuciones de un solo nodo, informamos el promedio de ambos servidores, mientras que para ejecuciones de dos servidores, informamos el ancho de banda total sumado de todos los servidores. Los resultados de los casos de uso se muestran en la siguiente figura.

Los resultados muestran que el almacenamiento en red no afecta negativamente el rendimiento: el cambio es mínimo y, para algunas tareas, no se encuentra ninguno. Al agregar el segundo servidor, el ancho de banda total se duplica exactamente o, en el peor de los casos, el cambio es inferior al 1 %.
Inferencia de IA en un escenario de flujo único para EF
Este punto de referencia mide la latencia. Para todos los casos, informamos la latencia promedio en todos los servidores involucrados en las ejecuciones. Se dan los resultados para el conjunto de tareas.

Los resultados muestran nuevamente que el almacenamiento en red es suficiente para manejar las tareas. La diferencia entre el almacenamiento local y el de red en el caso de un servidor es mínima o nula. De manera similar, cuando dos servidores usan el mismo almacenamiento, la latencia en ambos servidores permanece igual o cambia en una cantidad muy pequeña.