

TR-4928: IA responsable e inferencia confidencial - IA de NetApp con Protopia Image and Data Transformation
 Sugerir cambios
Sugerir cambios
Sathish Thyagarajan, Michael Oglesby, NetApp Byung Hoon Ahn, Jennifer Cwagenberg, Protopia
Las interpretaciones visuales se han convertido en una parte integral de la comunicación con el surgimiento de la captura y el procesamiento de imágenes. La inteligencia artificial (IA) en el procesamiento de imágenes digitales brinda nuevas oportunidades comerciales, como en el campo médico para la identificación del cáncer y otras enfermedades, en el análisis visual geoespacial para estudiar riesgos ambientales, en el reconocimiento de patrones, en el procesamiento de video para combatir el crimen, etc. Sin embargo, esta oportunidad también conlleva responsabilidades extraordinarias.
Cuanto más decisiones ponen las organizaciones en manos de la IA, más aceptan riesgos relacionados con la privacidad y la seguridad de los datos y con cuestiones legales, éticas y regulatorias. La IA responsable posibilita una práctica que permite a las empresas y organizaciones gubernamentales generar confianza y gobernanza, lo cual es crucial para la IA a escala en grandes empresas. Este documento describe una solución de inferencia de IA validada por NetApp en tres escenarios diferentes mediante el uso de tecnologías de gestión de datos de NetApp con el software de ofuscación de datos Protopia para privatizar datos confidenciales y reducir riesgos y preocupaciones éticas.
Cada día, tanto los consumidores como las entidades comerciales generan millones de imágenes con diversos dispositivos digitales. La consiguiente explosión masiva de datos y carga de trabajo computacional hace que las empresas recurran a plataformas de computación en la nube para lograr escalabilidad y eficiencia. Mientras tanto, las preocupaciones sobre la privacidad de la información sensible contenida en los datos de imágenes surgen con la transferencia a una nube pública. La falta de garantías de seguridad y privacidad se convierte en la principal barrera para la implementación de sistemas de IA de procesamiento de imágenes.
Además, existe la "derecho de supresión" por el RGPD, el derecho de un individuo a solicitar que una organización borre todos sus datos personales. También existe la "Ley de Privacidad" , que establece un código de prácticas justas de información. Las imágenes digitales, como las fotografías, pueden constituir datos personales según el RGPD, que regula cómo deben recopilarse, procesarse y borrarse los datos. No hacerlo constituye un incumplimiento del RGPD, lo que podría dar lugar a fuertes multas por incumplimiento que pueden ser gravemente perjudiciales para las organizaciones. Los principios de privacidad son la columna vertebral de la implementación de una IA responsable que garantice la imparcialidad en las predicciones de los modelos de aprendizaje automático (ML) y aprendizaje profundo (DL) y reduzca los riesgos asociados con la violación de la privacidad o el cumplimiento normativo.
Este documento describe una solución de diseño validada en tres escenarios diferentes con y sin ofuscación de imágenes relevantes para preservar la privacidad e implementar una solución de IA responsable:
-
Escenario 1. Inferencia a pedido dentro del cuaderno Jupyter.
-
Escenario 2. Inferencia por lotes en Kubernetes.
-
Escenario 3. Servidor de inferencia NVIDIA Triton.
Para esta solución, utilizamos el Face Detection Data Set and Benchmark (FDDB), un conjunto de datos de regiones faciales diseñado para estudiar el problema de la detección de rostros sin restricciones, combinado con el marco de aprendizaje automático PyTorch para la implementación de FaceBoxes. Este conjunto de datos contiene las anotaciones de 5171 caras en un conjunto de 2845 imágenes de varias resoluciones. Además, este informe técnico presenta algunas de las áreas de solución y casos de uso relevantes recopilados de clientes e ingenieros de campo de NetApp en situaciones donde esta solución es aplicable.
Público objetivo
Este informe técnico está dirigido a los siguientes públicos:
-
Líderes empresariales y arquitectos empresariales que quieran diseñar e implementar IA responsable y abordar cuestiones de privacidad y protección de datos relacionadas con el procesamiento de imágenes faciales en espacios públicos.
-
Científicos de datos, ingenieros de datos, investigadores de IA/aprendizaje automático (ML) y desarrolladores de sistemas de IA/ML que tienen como objetivo proteger y preservar la privacidad.
-
Arquitectos empresariales que diseñan soluciones de ofuscación de datos para modelos y aplicaciones de IA/ML que cumplen con estándares regulatorios como GDPR, CCPA o la Ley de Privacidad del Departamento de Defensa (DoD) y organizaciones gubernamentales.
-
Científicos de datos e ingenieros de IA que buscan formas eficientes de implementar modelos de inferencia de aprendizaje profundo (DL) e IA/ML/DL que protejan la información confidencial.
-
Administradores de dispositivos perimetrales y administradores de servidores perimetrales responsables de la implementación y la administración de modelos de inferencia perimetral.
Arquitectura de la solución
Esta solución está diseñada para gestionar cargas de trabajo de IA de inferencia en tiempo real y por lotes en grandes conjuntos de datos mediante el uso de la potencia de procesamiento de las GPU junto con las CPU tradicionales. Esta validación demuestra la inferencia de preservación de la privacidad para el aprendizaje automático y la gestión óptima de datos requerida por las organizaciones que buscan implementaciones de IA responsables. Esta solución proporciona una arquitectura adecuada para una plataforma Kubernetes de uno o varios nodos para computación en el borde y en la nube interconectada con NetApp ONTAP AI en el núcleo local, NetApp DataOps Toolkit y el software de ofuscación Protopia mediante interfaces Jupyter Lab y CLI. La siguiente figura muestra la descripción general de la arquitectura lógica de la estructura de datos impulsada por NetApp con DataOps Toolkit y Protopia.
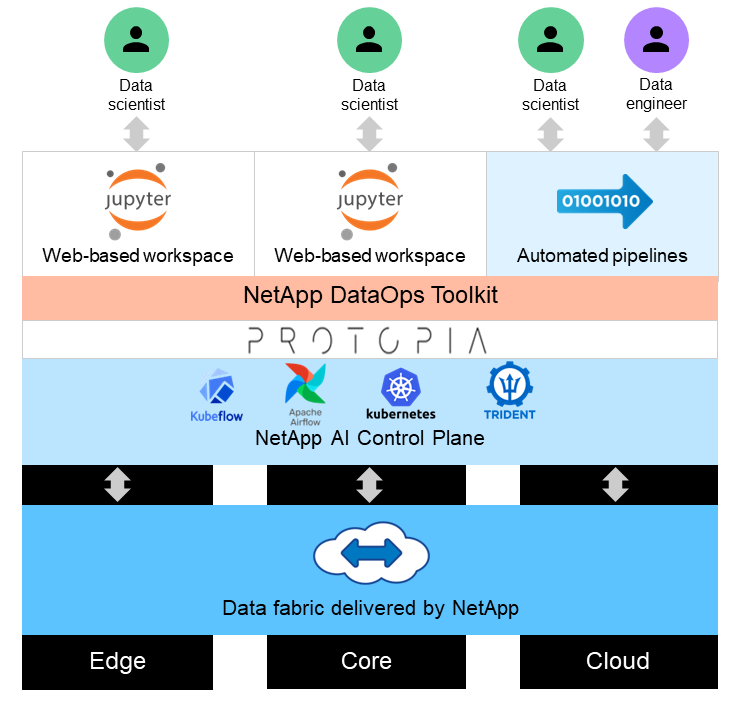
El software de ofuscación Protopia se ejecuta sin problemas sobre NetApp DataOps Toolkit y transforma los datos antes de salir del servidor de almacenamiento.